dubbo的配置
在之前的文章中配置了spring boot和dubbo框架的使用(传送门:springboot使用dubbo框架),看到了把dubbo相关的配置配置在了配置文件中。这里官方文档中也去讲解了对应的dubbo配置的加载。

在之前的文章中配置了spring boot和dubbo框架的使用(传送门:springboot使用dubbo框架),看到了把dubbo相关的配置配置在了配置文件中。这里官方文档中也去讲解了对应的dubbo配置的加载。
spring boot肯定是现在用的做多的开发框架,而dubbo框架是最流行的rpc框架之一,整合springboot和dubbo的使用很有必要。本篇博客还是根据上一篇中的dubbo简单demo的简单示例来整合spring boot。(上一篇传送门:dubbo-demo)
在上一篇中介绍了dubbo诞生的背景和框架的特性:dubbo概念和基本概念,这里就来一个dubbo的简单使用小体验。
dubbo中的官方文档的快速启动使用的是multicast广播注册中心暴露服务地址,这里选择的是使用zk作为注册中心,因为zk是很多公司作为dubbo注册中心,并且zk也是dubbo官方文档中推荐使用的注册中心。
本次是使用的mac上安装的zk,安装步骤:mac下安装zk
此次是采用maven构建整个项目。整个项目中的module结构如下:
其中:
此次在项目中的依赖用到了dubbo的依赖,因为使用的是zk注册中心,所以这里要引入zk的客户端依赖,这里要注意的是dubbo2.6版本之后是要引入zk的curator客户端。
dubbo依赖:
1 | <!-- https://mvnrepository.com/artifact/com.alibaba/dubbo 这个dubbo版本是集成了spring的 --> |
zk client依赖
1 | <!-- curator-framework --> |
由dubbo的架构图可知
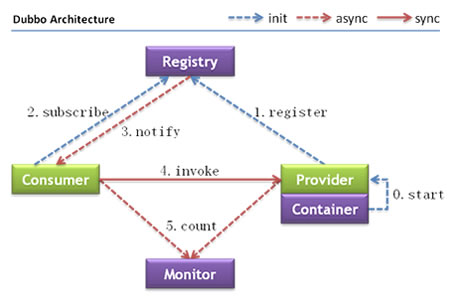
provider提供的服务要先注册在注册中心上,这里就要去配置provider相关的配置。
可以看到provider要提供的接口服务:
1 | public interface UserService { |
这里可以给一个简单实现:
1 | public class UserServiceImpl implements UserService { |
这里的关键是provider的xml配置:
1 | <?xml version="1.0" encoding="UTF-8"?> |
其中的配置:
这里可以简单的测试一下服务是否注册成功:
1 | public class TestProvider { |
启动这个测试程序后可以用telnet测试一下服务是否在本地的zk上注册上去
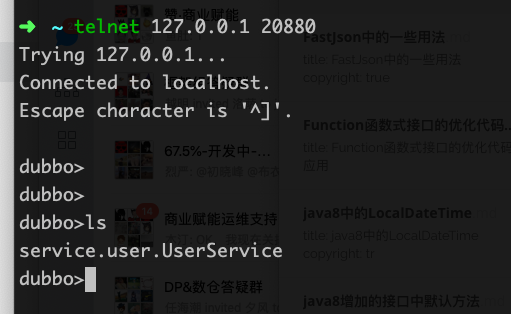
zk也可以看到多了一个dubbo节点:
同样consumer也要先实现order服务的接口
1 |
|
配置对应的consumer.xml文件
1 | <?xml version="1.0" encoding="UTF-8"?> |
这里多了一个dubbo的reference标签,这里就是要引用刚才暴露的接口。
在实现里看到了将实现类作为spring bean管理,这里在xml中开启了包扫描。
这里去写一个简单的test程序去测试写的consumer程序:
1 | public class TestConsumer { |
同时这里也启动这个test类,看控制台中的输出观察是否调用了远程接口。
可以看到在TestConsumer控制台输出
1 | 调用远程接口完成 |
在TestProvider控制台输出
1 | 调用到了消费者 |
可以看到调用成功。
此次的代码已上传至github: github
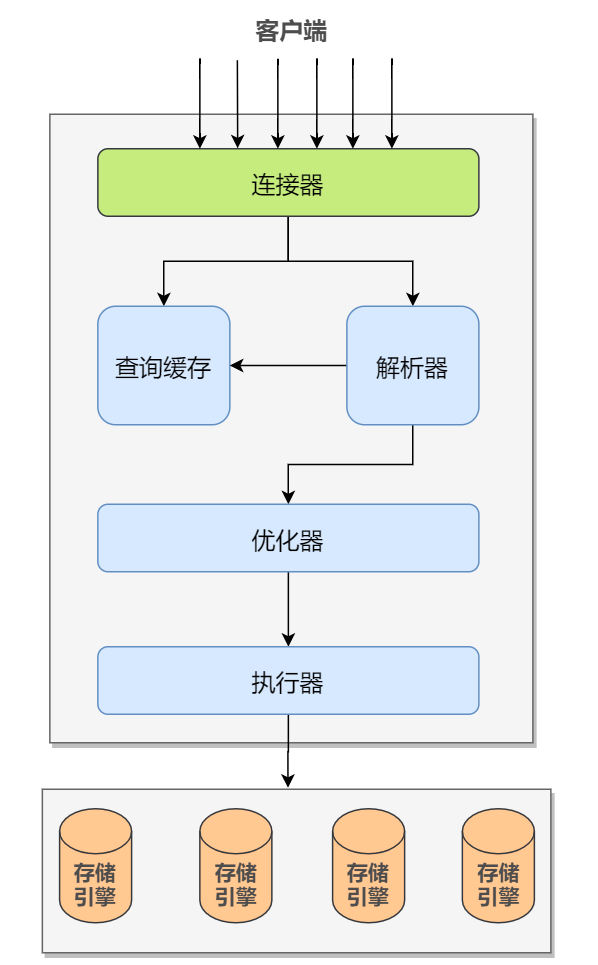
Mysql的binlog只能用于归档,不足以实现崩溃恢复(Crash-Safe),需要借助引擎层的redo-log才能拥有崩溃恢复的能力。 所谓崩溃恢复,即指在数据库宕机恢复之后,也要保证事务的完整性,不能做一半操作,同时也要注意主从同步的一致性。
简单看下binlog和redo log的区别:
其中第三点写入方式不同决定了redo log拥有恢复能力,因为追加写没办法看出binlog日志何时写入磁盘的,不能去做区分;而在宕机之后,可以根据redo log中的日志恢复到内存即可,也就是知道要恢复哪些数据。
对于一条update的SQL,也是大致上边的步骤,但是在执行器和存储引擎中要多写redo log和binlog的过程。比如对于SQL:1
update table set age = age + 1 where id = 1;
流程图如下:
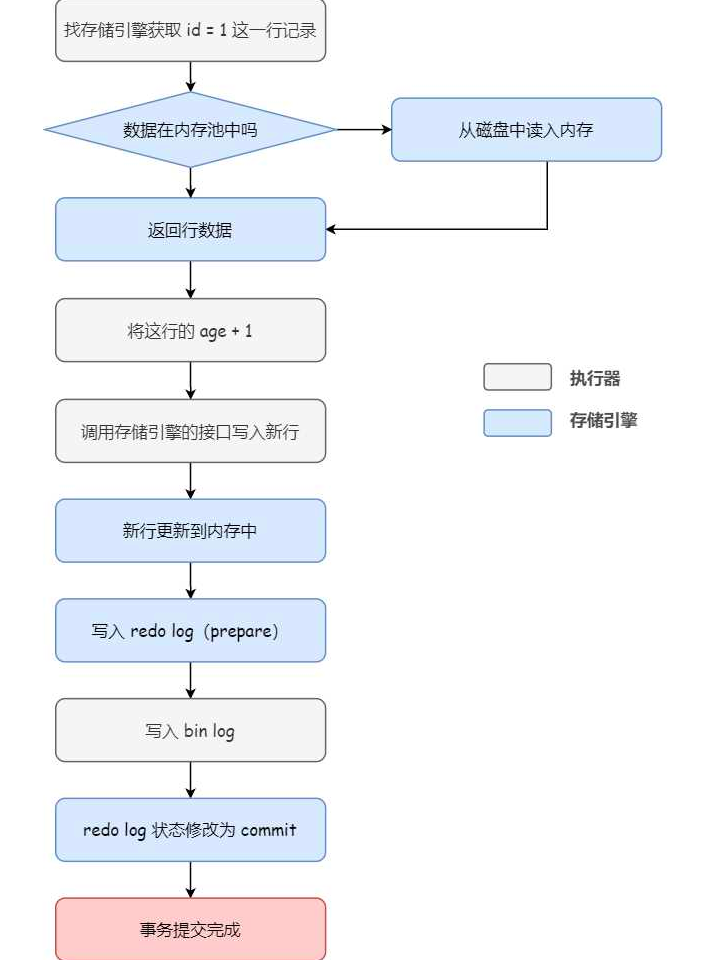
这里根据两阶段提交的流程,在Crash之后做崩溃恢复流程是这样的:
这里主要是考虑了主备同步的问题,从库都是通过binlog进行主备同步。这里的binlog的完整取决于其自身的格式,比如row模式和statement模式下或者mixed模式下各自的校验,或者各自的checkSum之类的,这里不去纠结。
如果redo log在prepare阶段Crash,但是binlog不完整,那么此时如果去继续提交事务,那么因为崩溃之前的binlog没有生成或者不完整,所以从库是没有这条SQL结果的数据的。所以此时去回滚这个redo log。
反过来,如果是在写入binlog成功之后数据库Crash,那么此时因为 binlog已经写入成功,从库有了这条数据,那么处于prepare阶段的redo log要去commit操作,进行事务的提交来保证主从数据一致性。
所以,处于prepare阶段的redo log和完整的binlog就能保证数据库Crash-Safe了
假设也是先写redo log,再写binlog,但是redo log是直接commit的,数据已经修改,这时如果写binlog crash了,那么redo log已经提交,主库中有数据但从库此时无法同步数据,就造成数据不一致。
主从的架构下,binlog到磁盘,从库同步数据,如果在写redo log时Crash,就会造成主从不一致。
dubbo是公司选择rpc框架时首先会去选择的框架,好好了解dubbo框架是一个合格程序员的必经之路。这里作为dubbo的入门篇,把一些概念和官方文档搞清楚一定是最应该开始的步骤。
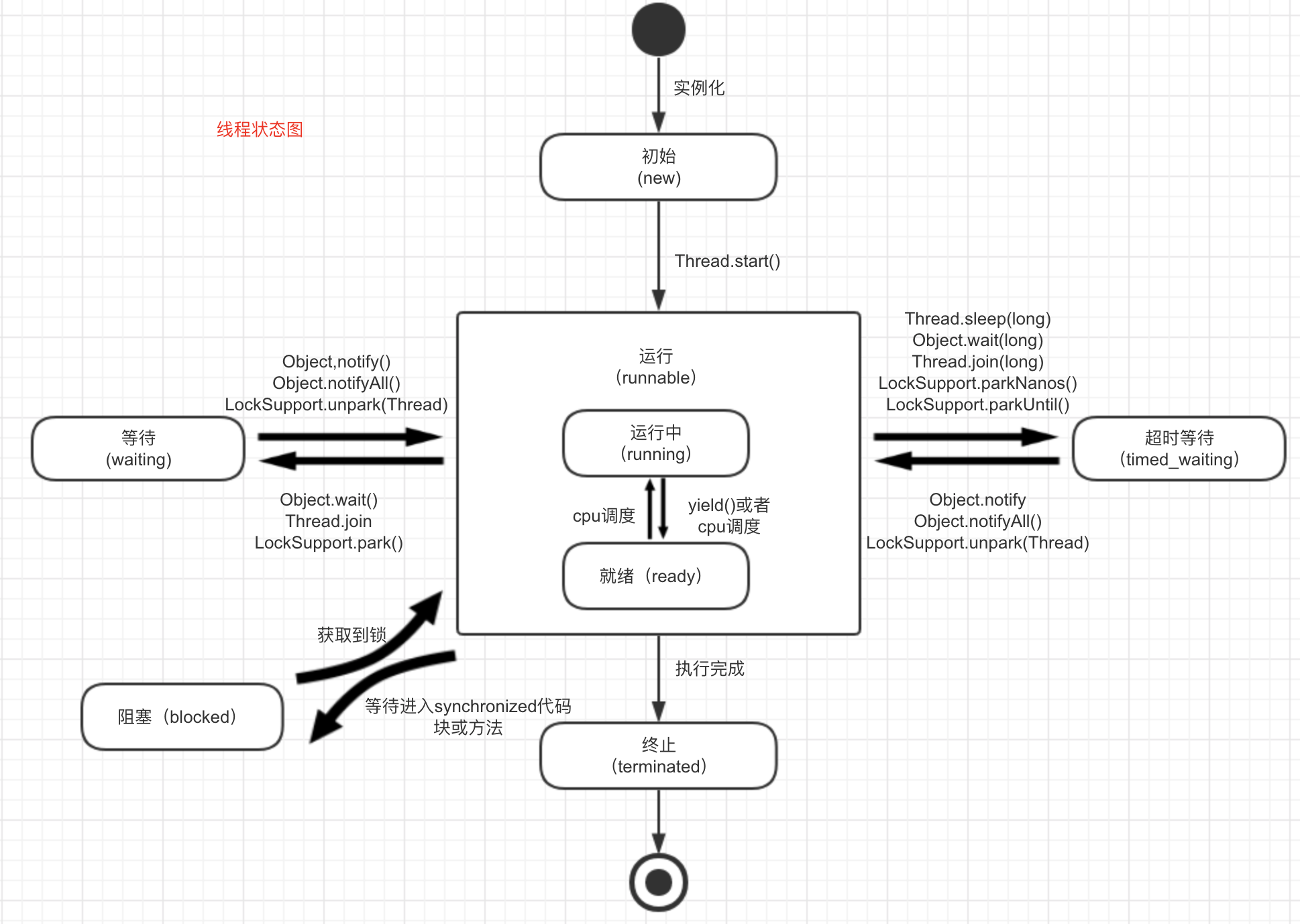
线程的状态很早之前就理解过了,最近翻《并发编程艺术》的书时候,看到有个点之前理解的不太对。
在书中有这样的一个例子:
1 | /** |
这里用了jps和jstack命令去观察了线程状态:
1 | // blockedThread-2线程阻塞在获取Blocked.class的锁上 |