题目
在小马哥的每日一问中看到了一道这个题:输出什么?。当时看错了在static块中的代码,就毫不意外的答错了= =,这个题其实没有看起来那么简单,这里去记录下这个题。小马哥这个每日一题的系列有很多比较”坑”的题,一般第一遍都比较难答对,推荐每天没事的时候可以去思否上看看这个题,也算拾遗一些基础~

java枚举是在开发过程中用的最多的类,这里对java之前的枚举常量类和枚举做了一个分析,并且对枚举相关知识拾遗。
在出现枚举之前,通常是一个final类去表示”可枚举”这个概念,比如下面这个列举数字的枚举类
1 | /** |
可以看到枚举类的特点:
这样有些缺点,比如:
这里写出对应的java枚举
1 | enum CountingEnum { |
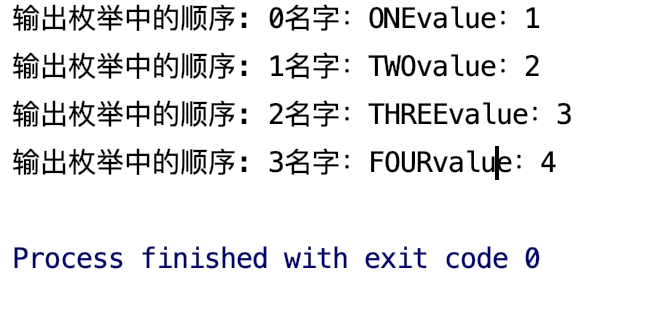
这里如果想要输出对应的名字和顺序,那么就十分方便了。
1 | // 输出 枚举 中的名字、位置、输出所有枚举 |
可以看到输出:
这是因为java所有的枚举都是继承Enum抽象类的,而valueOf()方法、ordinal()方法、name()方法都是定义在其中的,可以看下Eunm抽象类。
1 |
|
仔细看也许你会有两个疑问:
对这两个疑问我们可以去看这个类对应的字节码: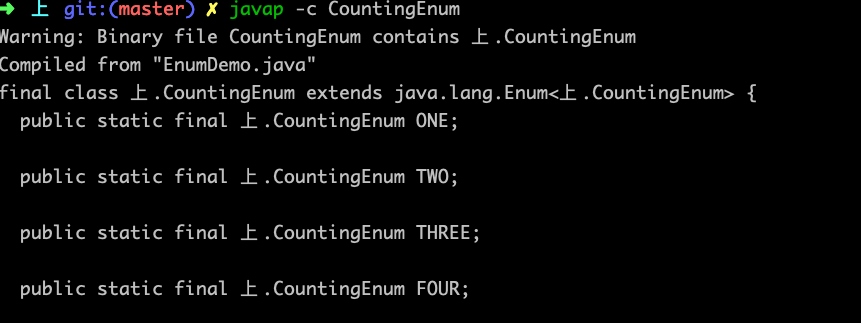
可以看到:
Enum<T>类的,所以可以访问到对应的name,ordinal字段,这个设计让我们输出枚举一些信息的时候很便捷。也提供了valueOf方法,也可以在动态判断枚举的时候使用。在来看下边的字节码:

可以看到是有values方法,其实这个是jvm通过字节码提升的方式去为枚举做的优化。所以使用枚举可以快速遍历并且一些输出之类的操作。
可以总结下枚举的特点:
我们在看基础语法的时候,总是说final 和 abstract是互斥的,所以想当然的认为枚举中不能定义抽象方法,但结论其实是可以的。
我们先看一个枚举来实现加减操作的例子:
1 | enum Opration { |
这个实现其实是通过在枚举中加入了非枚举含义的方法和域来实现的操作的一个类型枚举。但是有个问题,当拓展新的操作符时,需要破坏switch中的逻辑,这个不太符合开闭原则,这时候就可以通过把apply作为抽象方法,使得拓展时只需要实现符合自己的抽象逻辑。
1 | /** |
所以枚举是可以定义抽象方法的。
jdk中其实也有对应的例子,可以看下TimeUnit这个时间单位枚举,枚举类型都是通过实现抽象方法(其实是返回异常的普通方法,思想是一样的)来实现不同时间单位的转化。
如何给上边的枚举类实现一个values方法?
因为需要遍历所有的字段,所以很自然的想到了反射去实现。这里需要注意,因为枚举类定义的枚举都是public static final,而作为val变量是int的一个修饰符,需要将除了枚举外的val变量排除~
示例代码:
1 | final class EnumClass { |
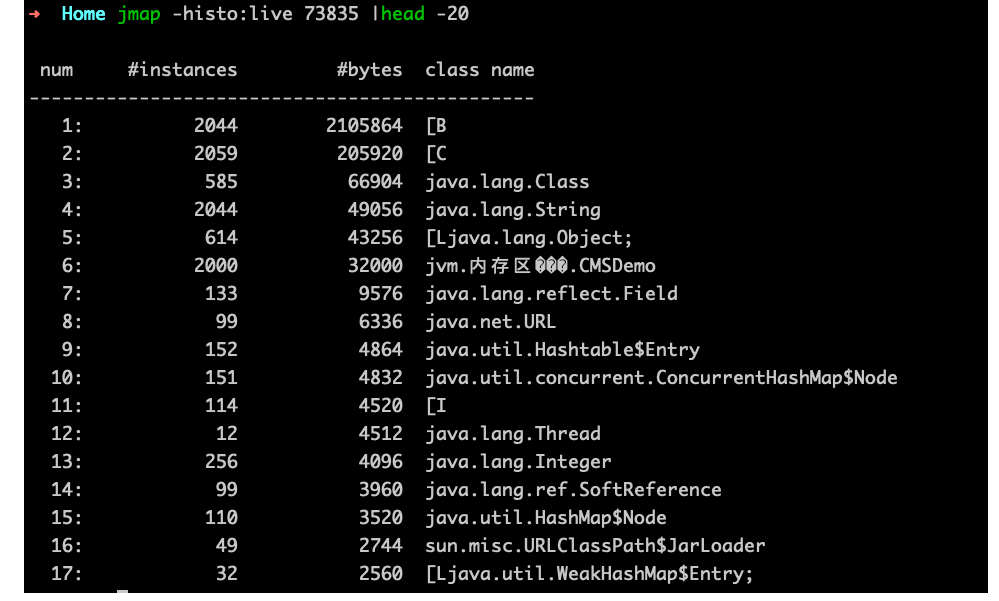
jmap可以查看内存信息、对象实例个数和占用内存大小。
比如下面命令可以查看堆内存中存活的对象实例个数和占用内存大小1
jmap -histo:live pid > ./log.txt
还可以通过命令dump JVM的内存1
jmap -dump:format=b,file=CMSdemo.hprof pid
jstack可以查看线程堆栈,比如命令:1
jstack -e pid
jstack能自动输出存在线程死锁的详细信息。(线程状态,互相等待的线程,等待的对象等)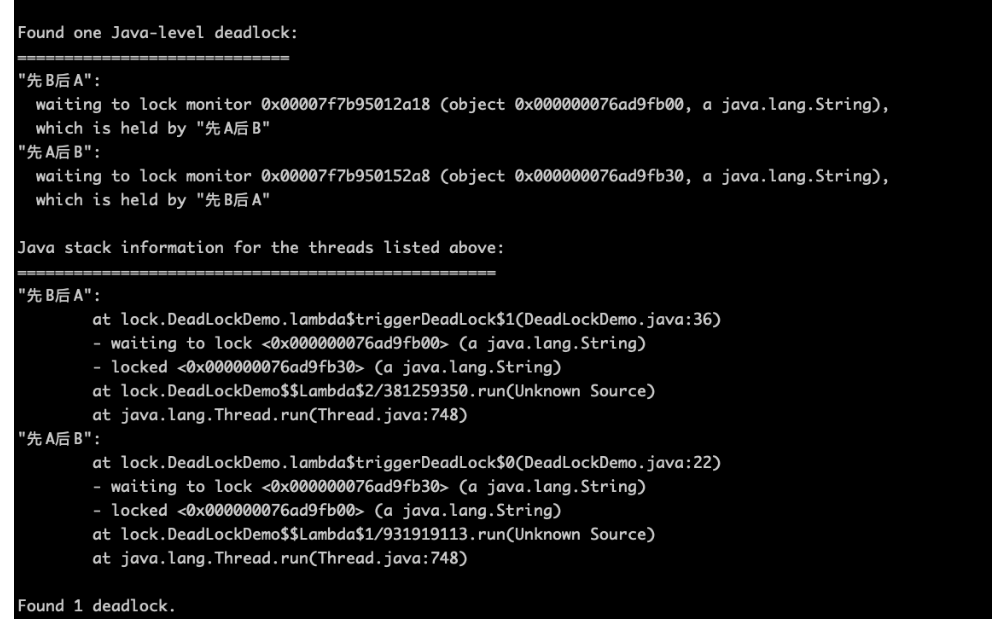
另外在机器CPU飙高之后,可以使用jstack来排查占用cpu时间最多的线程。
当然用Arthas更方便的排查CPU利用率高的线程。
查看正在运行的Java程序的扩展参数。
比如查看jvm参数,可以用命令:1
jinfo -flags pid

可以用命令,查看jvm的系统参数1
info -sysprops 75453
jstast可以看JVM堆内存各部分的使用量,以及加载类的数量。
1 | jstat -gc pid 2000 100 -- 代表输出进程=pid的java堆gc信息,每2000ms打印一次,打印100次 |

下面的命令可以查看堆内存统计1
jstat -gccapacity pid

1 | jstat -gcnew 75453 1000 10 |
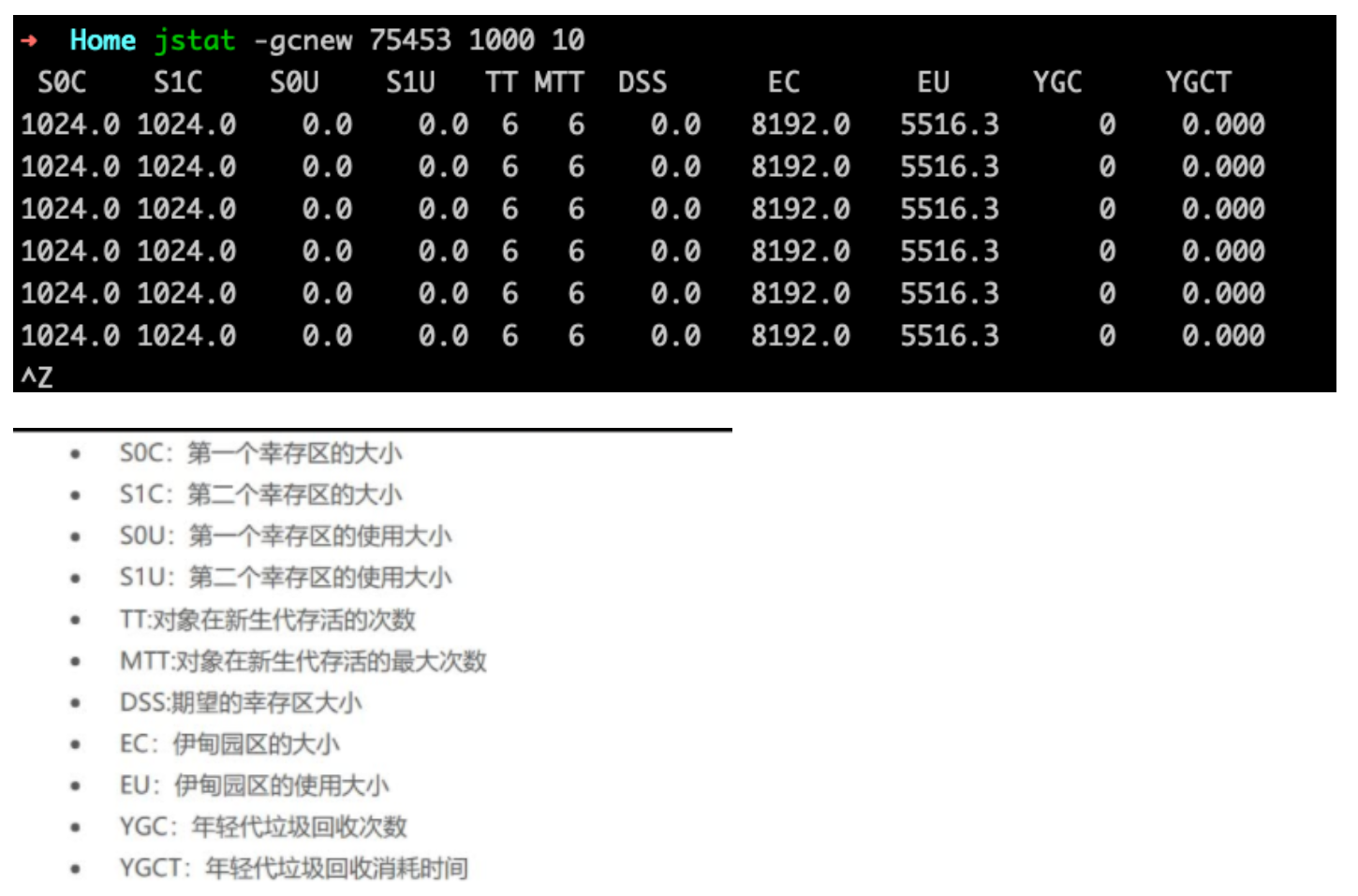
1 | jstat -gcnewcapacity 75453 1000 10 |

1 | jstat -gcoldcapacity 75453 1000 10 |
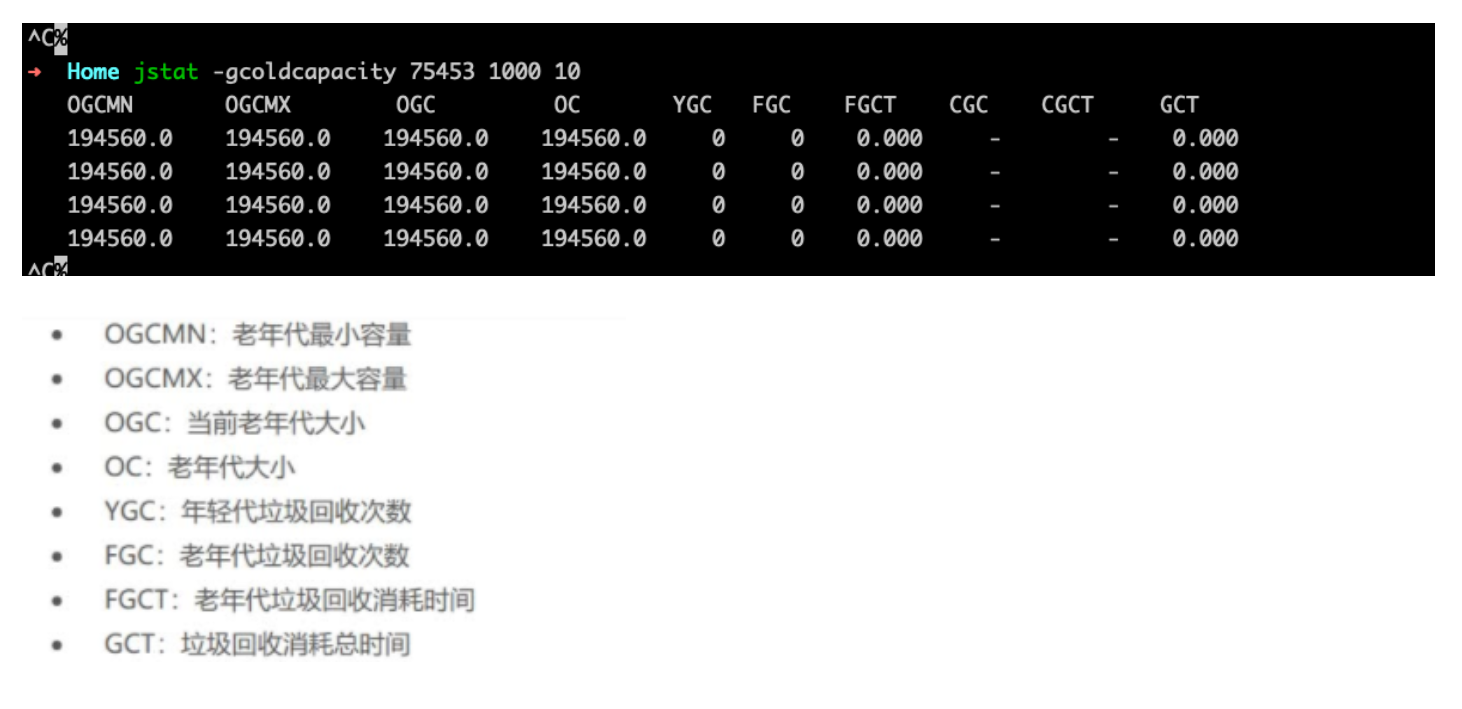
1 | jstat -gcold 75453 1000 10 |
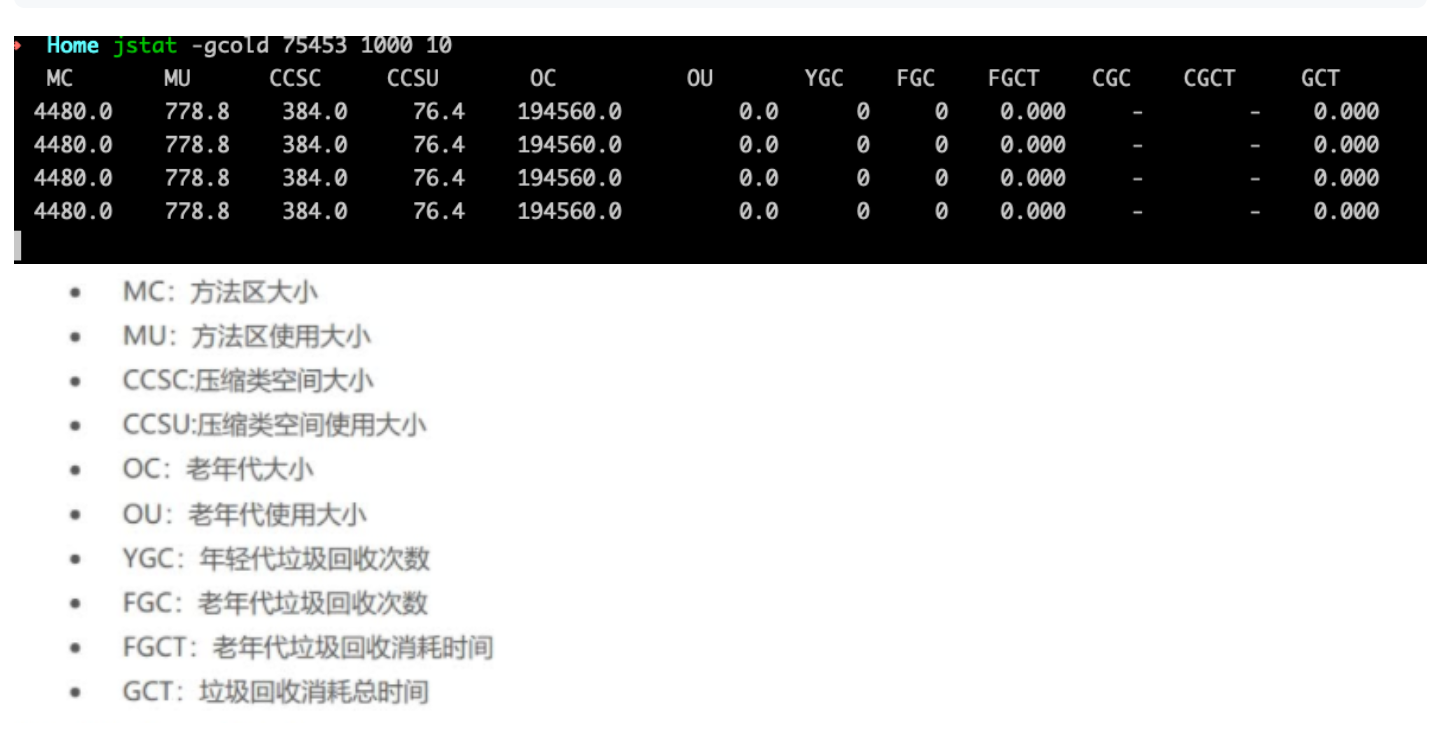
1 | jstat -gcmetacapacity 75453 1000 10 |
jstat -gc pid命令可以观察到堆内存使用情况和GC情况,则可以通过jstast观测的结果来了解和预估JVM的运行情况。
观察EU(Eden区的使用)来估算每秒eden大概新增多少对象,可以根据负载去调整观察频率。注意系统的高峰期和日长期,在不同时间去观测对象增长速率。
知道了年轻代对象增长速率,再根据Eden区的大小就可以知道YoungGC的触发频率,还可以根据YGC / YGCT 来计算出YoungGC每次的耗时。
如果知道了YoungGC没过多久触发了一次,比如1s触发一次,可以用命令
jstat -gc pid 1000 10 来打印最近10次的内存和GC情况,观察SU和OU的增长,因为每次YoungGC之后,存活对象会移动到Survivor区或者晋升到老年代中,所以可以看到每次多少对象进入到老年代。
FullGC的触发频率可以根据每次YoungGC多少对象进入老年代和老年代的大小来大致估算下。(当然老年代有很多参数,比如CMS垃圾回收器中触发CMS回收的阈值;比如元空间不足、手动调用System.gc()也都会触发FullGC)
FullGC的每次耗时可以根据FGCT / FGC来计算得出。
优化思路主要是根据JVM内存分配和对象流转策略的几个点来的,主要是去优化FullGC的频率。同时要对JVM的内存有一个划分: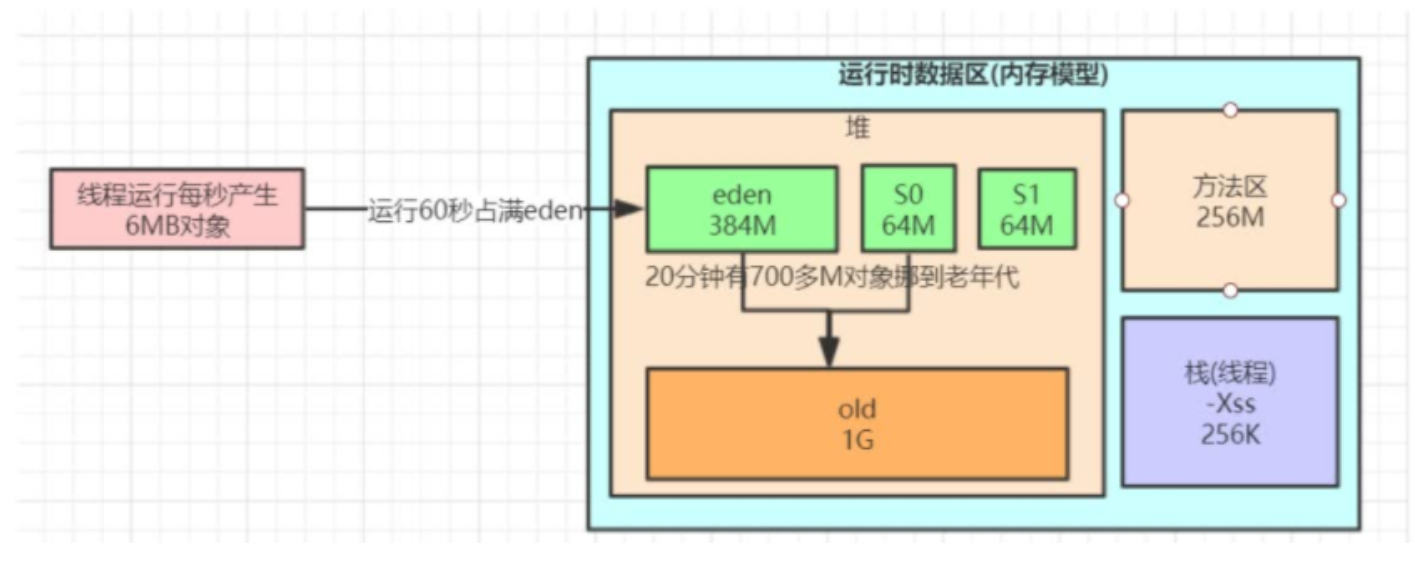
优化的原则比如:
增加内存大小
设置合理的内存区域大小和分代晋升年龄
根据对象的动态年龄判定来优化
对象的动态年龄判定是指的年轻代的对象不一定要在GC分代年龄到达设置阈值才晋升到老年代,如果Survivor空间中相同年龄的所有对象大小总和大于Survivor空间的一半,年龄大于此年龄的对象可以直接老年代,不需要等待达到晋升老年代的阈值。
这里尽量减少YoungGC之后对象在Survivor区占用的比例,可以适当调大Survivor区的大小,避免生命周期短的对象对象提前晋升到老年代,来增加老年代的压力和FullGC的频率。
大对象直接进入到老年代
新生代采用复制算法来GC,所以大于阈值的对象会为了避免复制则直接晋升到老年代中。应该尽量避免大对象的产生,因为大多数都是要在年轻代GC掉的对象,进入老年代可能会增加FullGC的频率。(比如未淘汰的缓存对象、未分页查询的SQL结果对象等)
老年代空间分配担保机制
可能出现的现象:频繁FullGC、FullGC次数比YoungGC次数都多
在MinorGC之前,只要老年代的连续空间小于新生代对象总和或历次晋升的对象平均大小,就会进行一次FullGC。这时如果可预测有生命周期长的对象,那么可以设置较小的晋升阈值或者较小的晋升年龄提前进入老年代;如果对象都是快速被GC的,可以设置较大的老年代空间。都是为了避免因为空间担保机制频繁FullGC。
如果不设置元空间的JVM相关参数,那么MetaSpace默认大小21m,在启动过程中会不断FullGC,(自动扩大元空间大小,再次触发FullGC的一个过程)
在确定了大体原因之后,如果要定位有问题的代码,可以使用jmap去看存活对象或者导出内存快照,也可以jstack看占用CPU比较高的线程(一般不断的创建对象代表线程的活跃)区定位具体的问题代码。
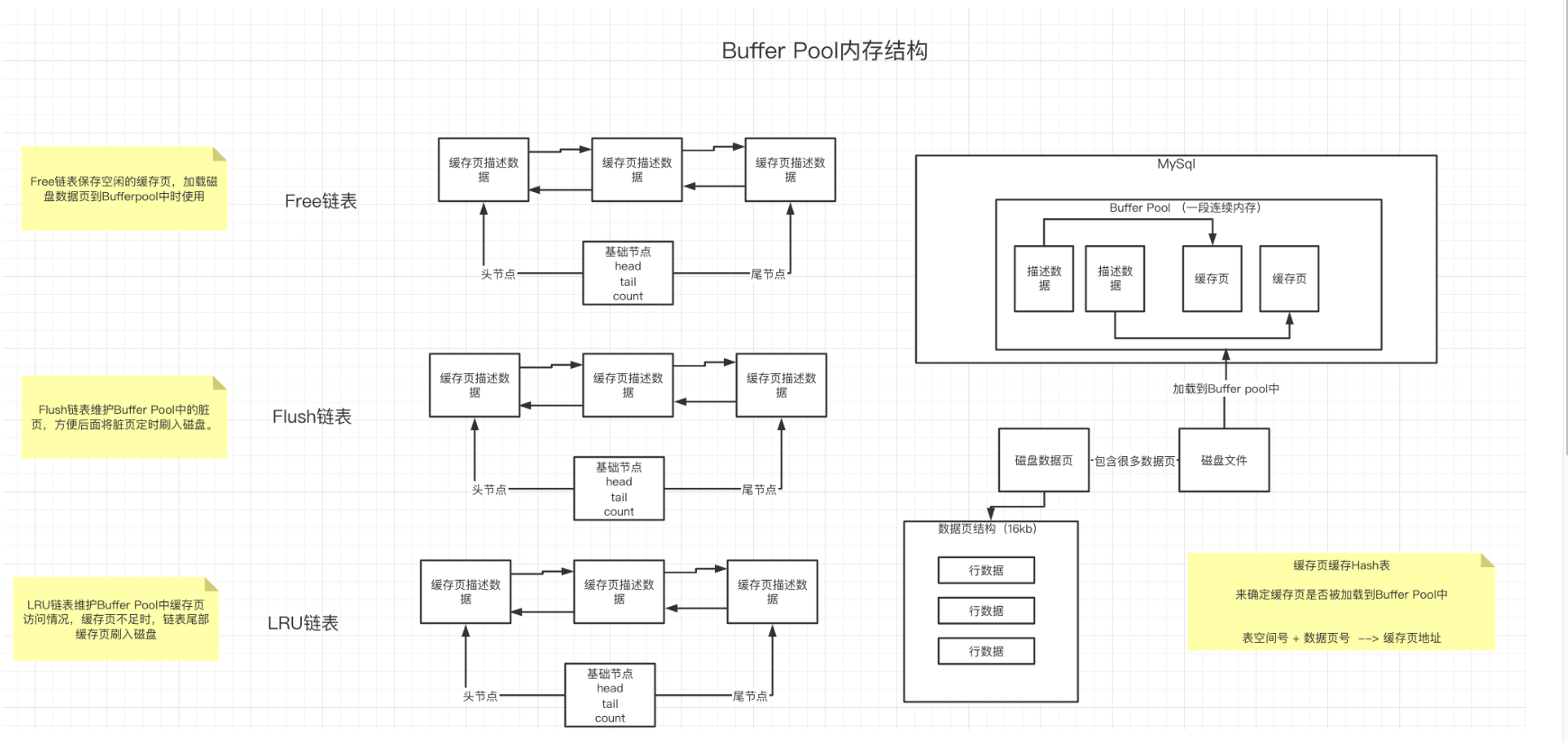
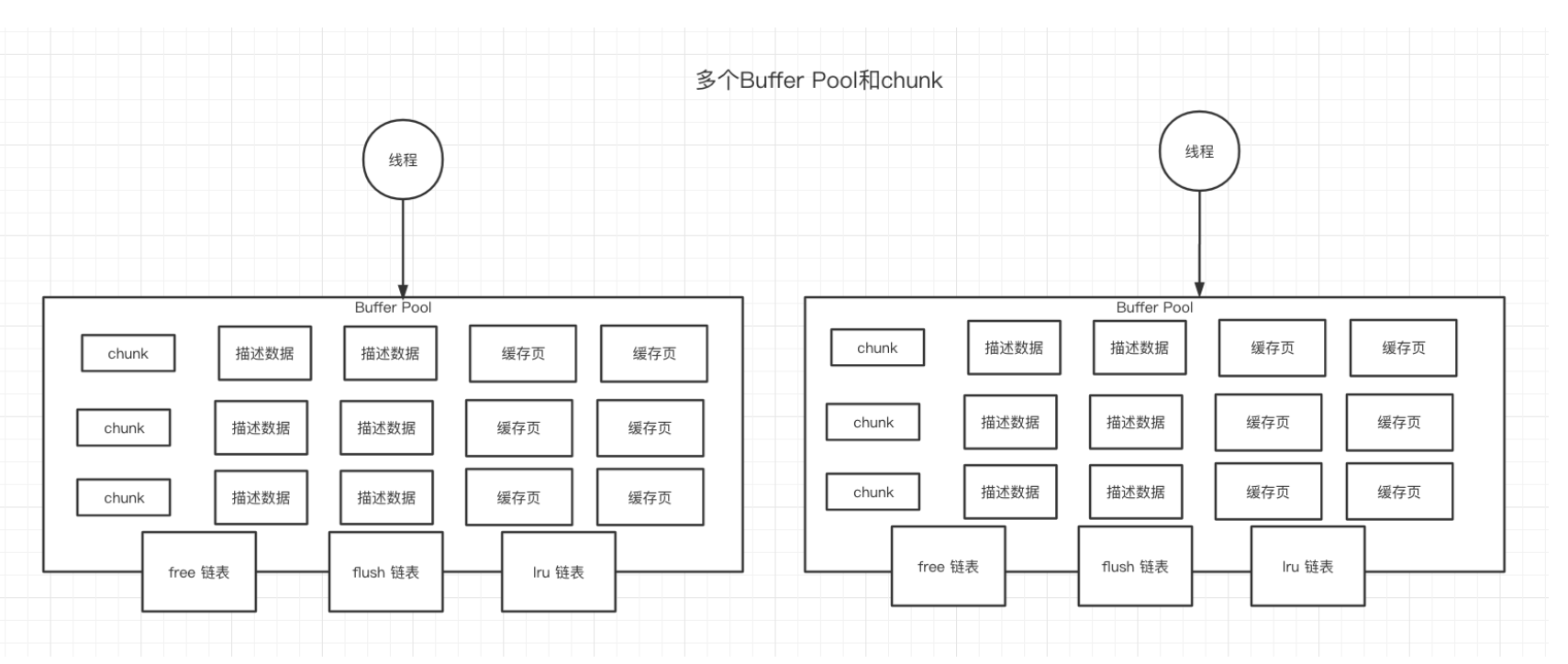
前一段时间一直在忙,拉下了一些知识的学习,现在努力追赶修补中。= =
当然也有一些新的知识的学习,但其实更多的是关于一些知识的拾遗。之前在工作当中发现对redis命令掌握的还不是很完善,所以想花比较少的碎片时间去写一下redis常用命令的拾遗。
对这些命令的拾遗记录是在网站:http://redisdoc.com上进行学习的,很简单明了,推荐给大家进行学习拾遗。
这里只是把日常会被忽略或者遗忘的点进行一下梳理,并不是每个知识点的一个总结。
####set命令
set可以通过一系列参数进行修改:
setex命令效果等价于执行下边两个命令:
1 | set key value |
但是不同的是,setex是一个原子的操作,它是在同一时间完成设置值和过期时间的操作,经常用在存储缓存时候。
setex设置成功时候 返回ok。
同样psetex只是单位是毫秒而已。
get命令不用多说,但是注意get命令只是用在字符串操作,如果key对应的值不是字符串类型,那么返回一个错误。
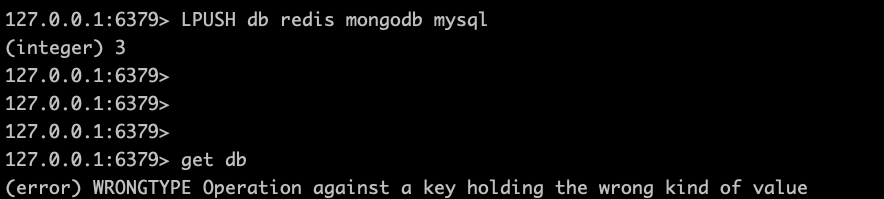
此命令的作用是:将key设置为value,并且返回key在被设置之前的值。如果key之前不存在,则返回nil。当键key存在但不是字符串时,会报错。
返回字符串key的长度,当key不是字符串时,返回一个错误。如果key不存在,返回0。
append命令:如果已经存在key并且它的值是一个字符串,append命令将value追加到key对应值的末尾。如果key不存在,append命令会像执行set key value一样将值设置为对应的key的值。
append命令的返回值是值字符串的长度。
注意append的时间复杂度是平摊o(1)
指从偏移量offset开始,用value参数覆写value值。这个命令会确保字符串足够长以便于设置value到对应的偏移量。比如字符串只有5个字符长,但设置的offset是10,那么会在原来字符串值到偏移量之间设置零字节(“\x00”)进行填充。
这个命令的返回值是被修改之后字符串值的长度
这个命令指的是返回键key对应的字符串值的指定部分,字符串的截取范围由start end两个参数决定(包括start和end在内)。start和end支持负数偏移量,-1代表最后一个字符,-2代表倒数第二个字符。但是注意只能按照字符串顺序获取,不能倒序获取(比如 getrange key -1 -3)
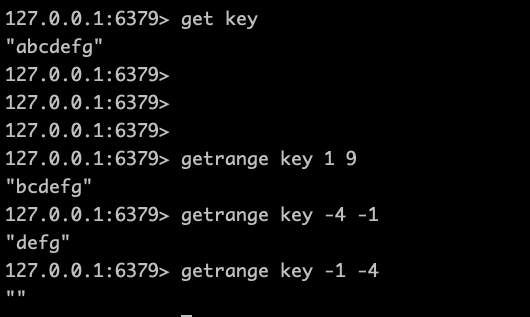
incr虽然是自增的含义命令,但其实是一个属于字符串的操作,redis并未提供一个专用的整数类型,所以键key存储的值在执行incr命令的时候会被翻译解释为十进制64位有符号整数。
如果incr操作的key值对应不存在,那么先会初始化为0,然后再执行incr命令。
如果key值不能被解释为数字,那么会返回一个错误。
和incr一样的含义,只不过有递增量为increment。同样的递减是有对应的decr key和decrby key decrement。
这个就是针对浮点数的增加计算。注意incrbyfloat命令计算的结果最多只保留小数点后面17位。
同时为多个键设置值,这个命令是一个原子操作,所有给定键会在同一时间内被设置,并且具有set的特性,会覆盖key对应原来的值。如果仅是在不存在的情况下设置值,可以用msetnx,msetnx也是一个原子操作,如果多个key中有一个key没有设置上,那么所有的key都不会设置对应的值。
特点
(1)Mapper文件中有Mapper接口映射关系的唯一标识,比如findById在接口中定义此方法,那么在mapper.xml肯定也有findById标签对应的sql模板,如果写错会在Mybatis启动的时候报错,达到提前校验的目的。
(2)Mapper接口在使用时不用为其实现接口,就可以自动绑定映射其对应的sql模板执行方法。在spring环境中也可以接口注入直接使用。这里注入的是Mapper接口的代理类。
这些功能就在mybatis框架的binding包下。
binging的核心组件及关系如下:
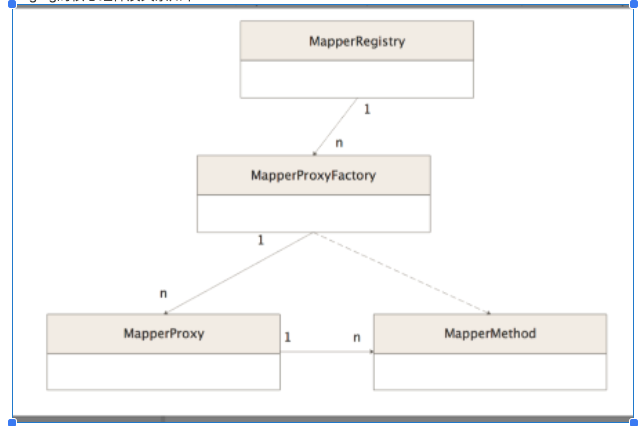
MapperRegistry
MapperRegistry是Mybatis初始化过程中构造的一个对象,主要作用是维护Mapper接口和其对应的MapperProxyFactory。
核心字段:
1 | public class MapperRegistry { |
addMapper和getMapper方法
addMapper是为Mapper接口添加对应的代理工厂到kownsMapper中。
1 | public <T> void addMapper(Class<T> type) { |
getMapper是获取Mapper接口的一个代理对象,也是通过获取到knownMappers map中的MapperFactoryProxy,然后通过newInstance方法来获取新的代理对象
1 | public <T> T getMapper(Class<T> type, SqlSession sqlSession) { |
MapperProxyFactory
MapperProxyFactory逻辑很简单,就是生成代理类的工厂。
其中核心字段为:
1 | public class MapperProxyFactory<T> { |
MapperProxy
MapperProxy实现了InvocationHandler接口,用于拦截生成代理类。
代理逻辑是利用Method对应的MapperMethod去执行对应execut方法。
1 | public class MapperProxy<T> implements InvocationHandler, Serializable { |
MapperMethod
MapperMethod是最终执行sql的地方,也是存储了当前执行Mapper接口方法的Method对象。其中包含两个核心字段 sqlCommond、methodSignature。这两个都是其中的静态内部类。
SqlCommand
sqlCommand变量维护了关联sql语句的相关信息。
其在构造函数中根据传入的Mapper接口和method方法来初始化SqlCommond。逻辑其实就是从传入接口或其父类中解析出MapperStatement对象,其能标识mapper.xml中的完整的一个sql模板。再从中解析出name和commandType。
1 | public static class SqlCommand { |
MethodSignature
MethodSignature主要维护了当前接口方法的信息,如返回值类型、参数和实际入参的绑定关系(运用了ParamNameResolver工具类)等。
在methodSignature.convertArgsToSqlCommandParam方法中,也是处理了@Param注解与sql模板中的参数绑定关系。
1 | public static class MethodSignature { |
execute方法
最终sql的执行都是通过MapperMethod的execute方法执行,这里依赖了其中的sqlCommond和methodSignature两个变量。
execute核心逻辑就是根据具体的sqlCommondType来选择执行具体的方法。其中也处理了不同的返回值
对应Select类型,
1 | /** |
总结
重点介绍了 MyBatis 中的 binding 模块,正是该模块实现了 Mapper 接口与 Mapper.xml 配置文件的映射功能。
首先,介绍了 MapperRegistry 这个注册中心,其中维护了 Mapper 接口与代理工厂对象之间的映射关系。
然后,分析了 MapperProxy 和 MapperProxyFactory,其中 MapperProxyFactory 使用 JDK 动态代理方式为相应的 Mapper 接口创建了代理对象,MapperProxy 则封装了核心的代理逻辑,将拦截到的目标方法委托给对应的 MapperMethod 处理。
最后,详细讲解了 MapperMethod,分析了它是如何根据方法签名执行相应的 SQL 语句。
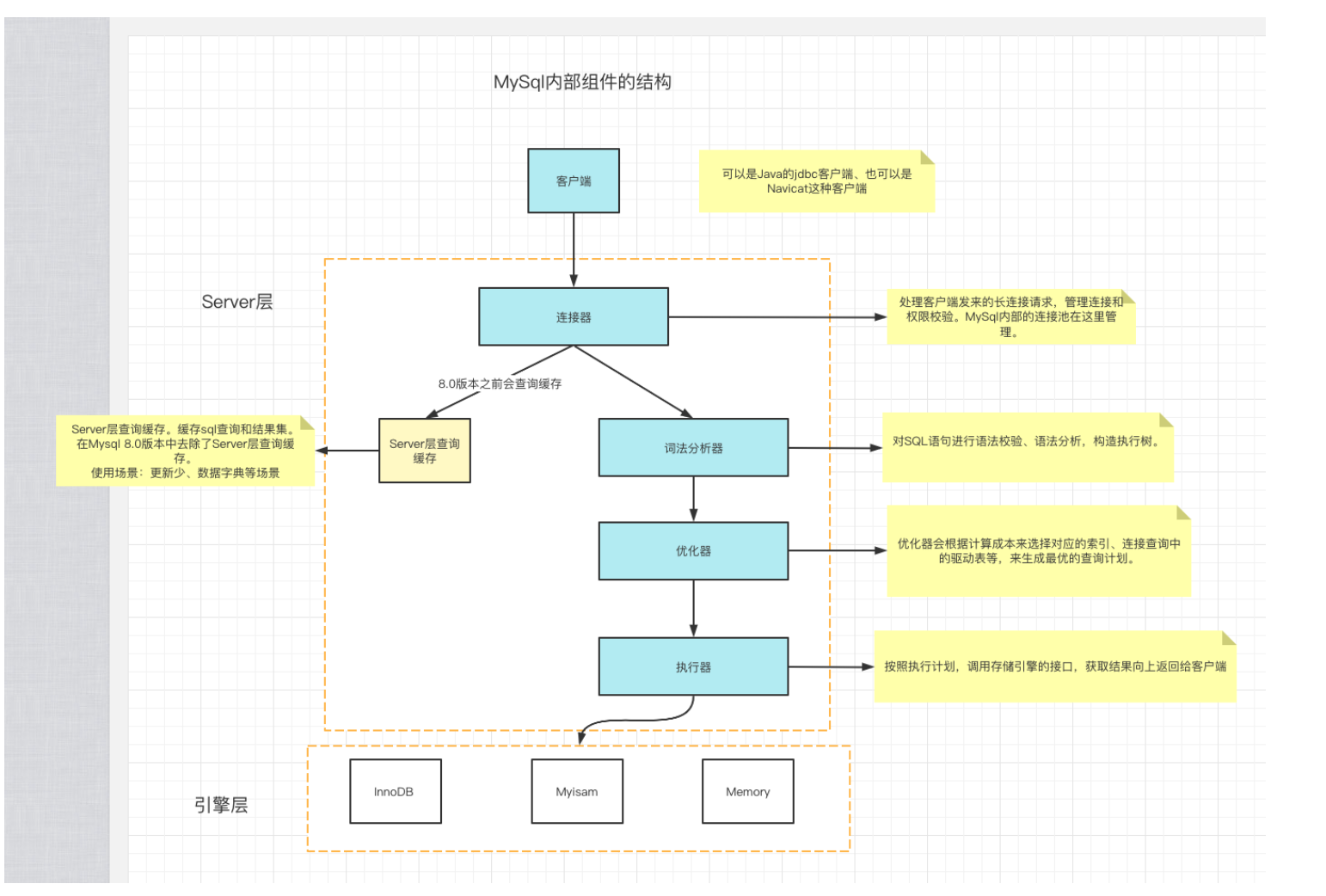
如图所示:客户端发来一条SQL语句之后,Mysql内部组件会:
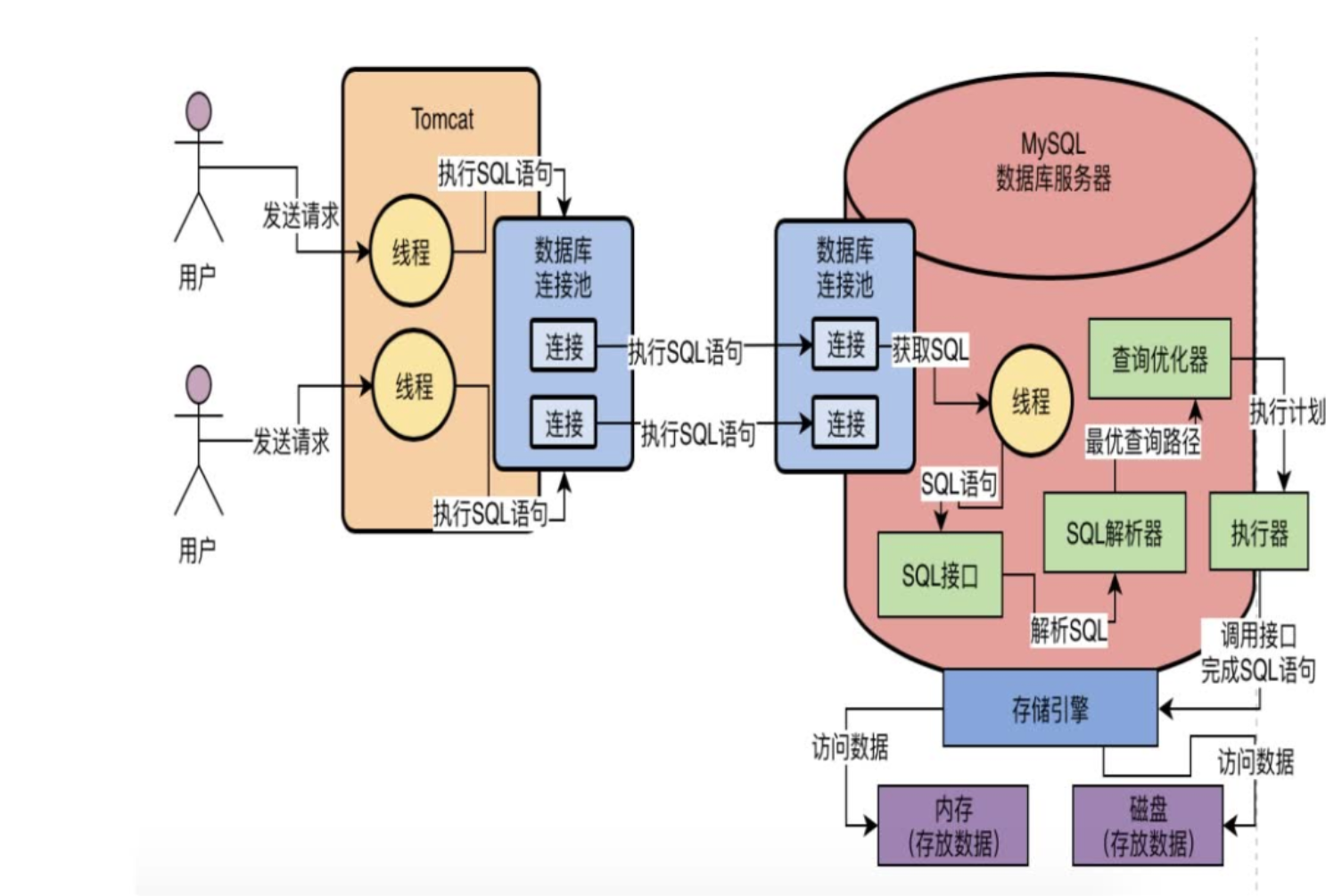
binlog是MySqlServer层实现的二进制逻辑日志,和redo log不同,redo log记录的是物理日志(表空间 + 区号 + 数据页 + 偏移量 + 修改内容),binlog的内容大概是(user表id = 1的记录name更新为xxx)是一个逻辑日志。同时redo log是innodb存储引擎实现事务中的持久性特性而存在的,在其他存储引擎不存在,而binlog是mysql都有的。
在事务Commit时,会写binlog,这个过程存在于redo log的二阶段提交过程。因为binlog常用于数据恢复和主从同步,所以要保证redo和binlog的一致性采用了两阶段。
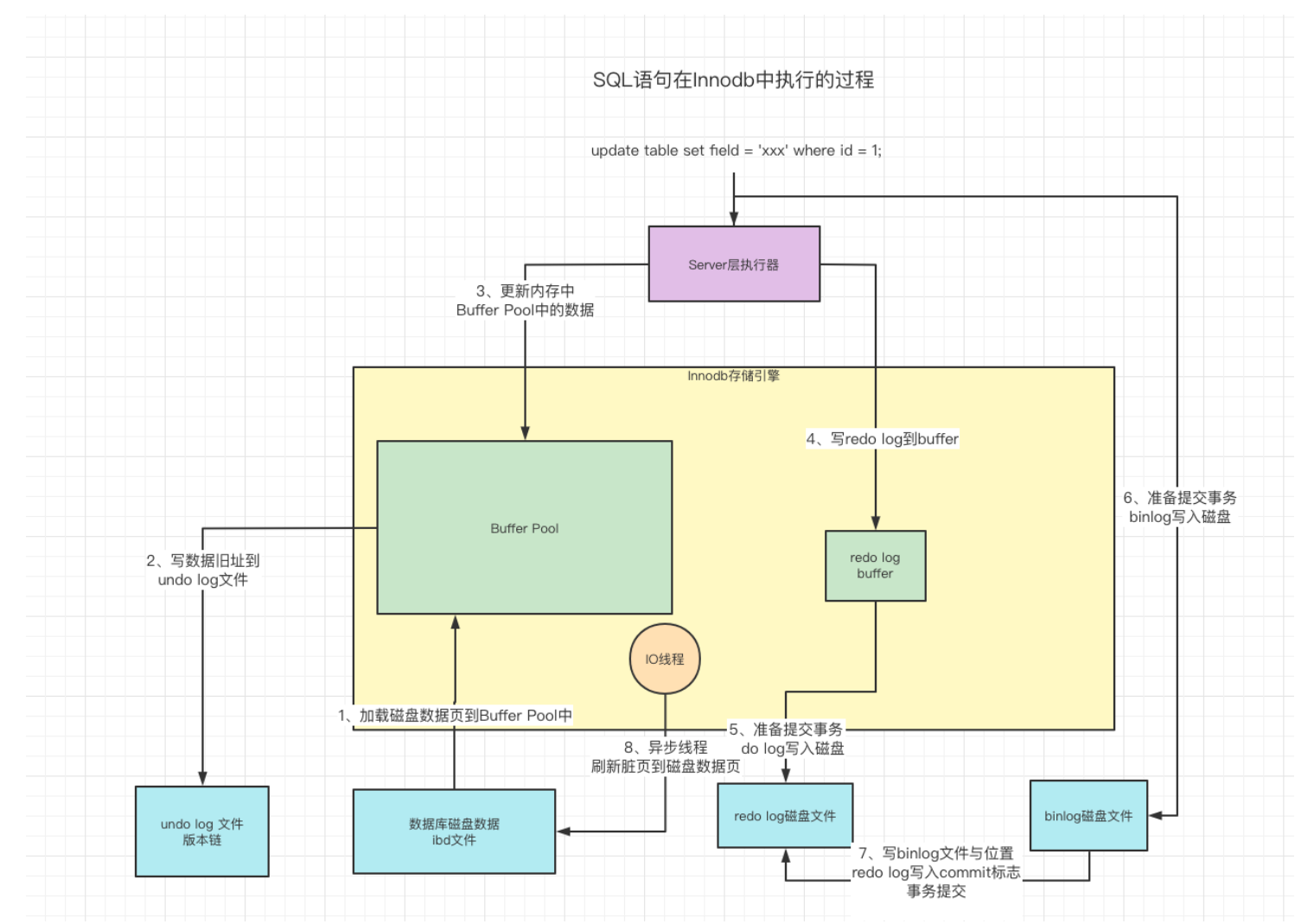
而redo log用于实现持久性,只要redo log和binlog的两阶段完成,就能保证这次变更是crash safe的,不会丢失。
binlog也会用于数据恢复和主从同步,是server层面的二进制逻辑日志,记录了语句信息。
写那么多的日志都是在文件末尾追加写,相当于是追加写,是顺序IO;而因为更新数据要维护不同的索引树,数据的分布在磁盘上访问是随机IO,效率不是一个数量级的,这样innodb选择去写这些日志,异步线程去刷新内存中的脏页到磁盘上,来提高事务的效率。