开始
HashMap是在开发工作中经常使用的集合类之一,熟悉其源码应该是基本要求。这篇文章对jdk1.8版本中的HashMap的一些常用方法的源码进行个记录。ps:这篇文章没有对其中的树化进行深究,比如提供的TreeNode内部类的结构和在扩容、Hash碰撞的时候的静态方法,之后有时间再研究下。

HashMap是在开发工作中经常使用的集合类之一,熟悉其源码应该是基本要求。这篇文章对jdk1.8版本中的HashMap的一些常用方法的源码进行个记录。ps:这篇文章没有对其中的树化进行深究,比如提供的TreeNode内部类的结构和在扩容、Hash碰撞的时候的静态方法,之后有时间再研究下。
Comparator接口或者Comparable接口在日常开发工作中是经常用到的,用于比较一组数据或者对象,在java8之后,也可以看到在Comparator接口中加入了一些default方法和static方法,这里做一个简单说明。
一道很经典的数据结构的题目实现。
栈:一般是后进先出的顺序,可以看下java中的Stack这个类。
队列:一般是先进先出的顺序,但是java中的Queue接口中也写了注释,没有要求是必须严格的先进先出,比如java中也有优先级队列、双端队列Deque。
https://segmentfault.com/a/1190000021217176
Spring其实是可以帮助解决循环依赖的,但是在循环依赖的两个bean上有一个加入了@Async注解之后,在启动的时候就报错不能进行循环依赖。
1 | @Component |
对应的错误:1
org.springframework.beans.factory.BeanCurrentlyInCreationException: Error creating bean with name 'a': Bean with name 'a' has been injected into other beans [b] in its raw version as part of a circular reference, but has eventually been wrapped. This means that said other beans do not use the final version of the bean. This is often the result of over-eager type matching - consider using 'getBeanNamesOfType' with the 'allowEagerInit' flag turned off, for example.
注意这里@Transaction虽然也是使用的代理,但是循环引用如果是@Transaction注解 是不影响启动的 可以在最早初始化类实例的时候就能拿到代理对象, 而async是在postProcessor后置处理器当中处理的,所以在循环引用时会放入原始对象而不是代理对象 在之后的check时会报错。这里要做下区分。
报错所在方法:
org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory#doCreateBean
1 | protected Object doCreateBean( ... ){ |
debug看到的对象注入: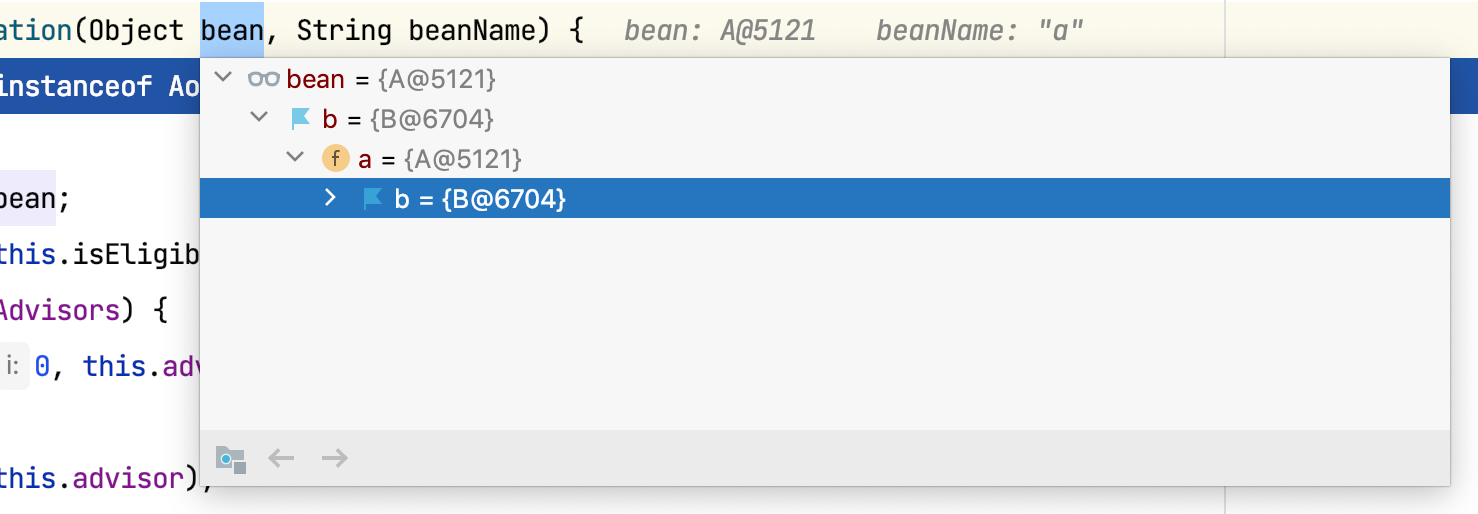
可以看到@Async注解标注的Bean的创建代理的时机是在检查bean中引用的之后的。看@EnableAsync注解会通过AsyncConfigurationSelector注入AsyncAnnotationBeanPostProcessor这个后置处理器,在其实现了postProcessAfterInitalization方法,创建代理即在此中。
这里的根本原理是只要能被切面AsyncAnnotationAdvisor切入的Bean都会在后置处理器中生成一个代理对象(如果已经是代理对象,那么加入该切面即可),赋值为上边doCreateBean中的exposedObject作为返回值加入到spring容器中。
1 | // 关键是这里。当Bean初始化完成后这里会执行,这里会决策看看要不要对此Bean创建代理对象再返回~~~ |

1 | public class SnowflakeIdWorker { |
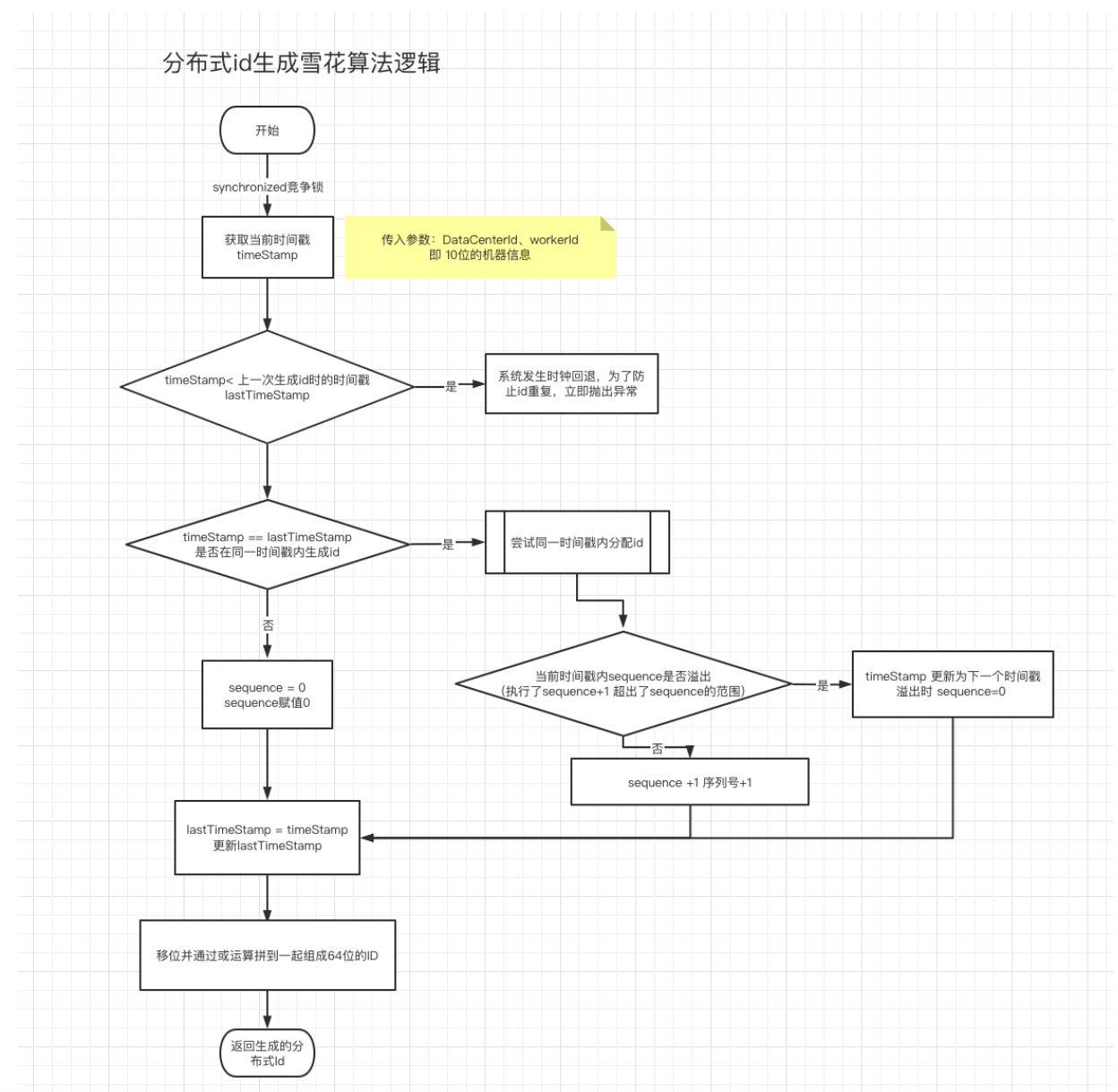
https://segmentfault.com/a/1190000018730103
1 | show engine innodb status; |
记录锁(LOCK_REC_NOT_GAP): lock_mode X locks rec but not gap
间隙锁(LOCK_GAP): lock_mode X locks gap before rec
Next-key 锁(LOCK_ORNIDARY): lock_mode X
插入意向锁(LOCK_INSERT_INTENTION): lock_mode X locks gap before rec insert intention

1 | ===================================== |
一些注释:
LATEST DETECTED DEADLOCK:标示为最新发生的死锁;
(1) TRANSACTION:此处表示事务1开始 ;
MySQL thread id 16, OS thread handle 140548578129664, query id 3052 183.6.50.229 root update:此处为记录当前数据库线程id;
insert into t_bitfly values(7,7):表示事务1在执行的sql ,不过比较悲伤的事情是show engine innodb status 是查看不到完整的事务的sql 的,通常显示当前正在等待锁的sql;
(1) WAITING FOR THIS LOCK TO BE GRANTED:此处表示当前事务1等待获取行锁;
(2) TRANSACTION:此处表示事务2开始 ;
insert into t_bitfly values(5,5):表示事务2在执行的sql
(2) HOLDS THE LOCK(S):此处表示当前事务2持有的行锁;
(2) WAITING FOR THIS LOCK TO BE GRANTED:此处表示当前事务2等待获取行锁;
Typora是大家写博客、记笔记、写文档等日常使用场景下都会使用的一个MarkDown语法的软件,对于熟悉markdown语法和喜欢markdown简洁性的朋友来说,typora是不可或缺的工具。但是,对于图片处理,我们需要图床去将我们的本地图片(截图、流程图之类的)上传到第三方的对象存储上(当然自己的服务器也是可以的)。
本文基于一个typora在windows下的小插件windows下typora图床 来实现实时的粘贴图片到typora即将你的图片上传到阿里云OSS上,并且替换的实现过程,github上已经其实写的比较明白了,但是还是想把自己接入的过程和踩得坑记录一下。
对于typora的使用、阿里云OSS的使用(我记得一年只要个位数的钱)、markdown语法等网上有很多介绍和例子,下面是几个传送门:
如果你没有图床,那么在你写博客的过程中如果要使用阿里云图片的外链,得是这样的操作。
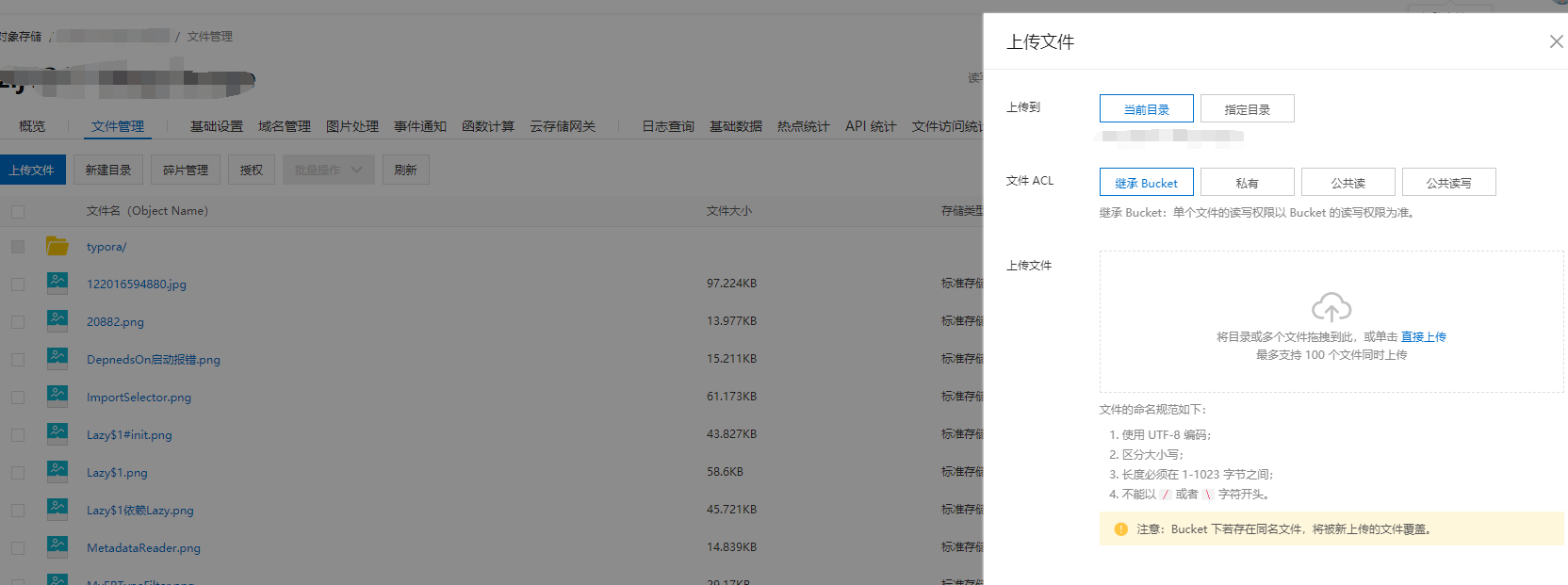
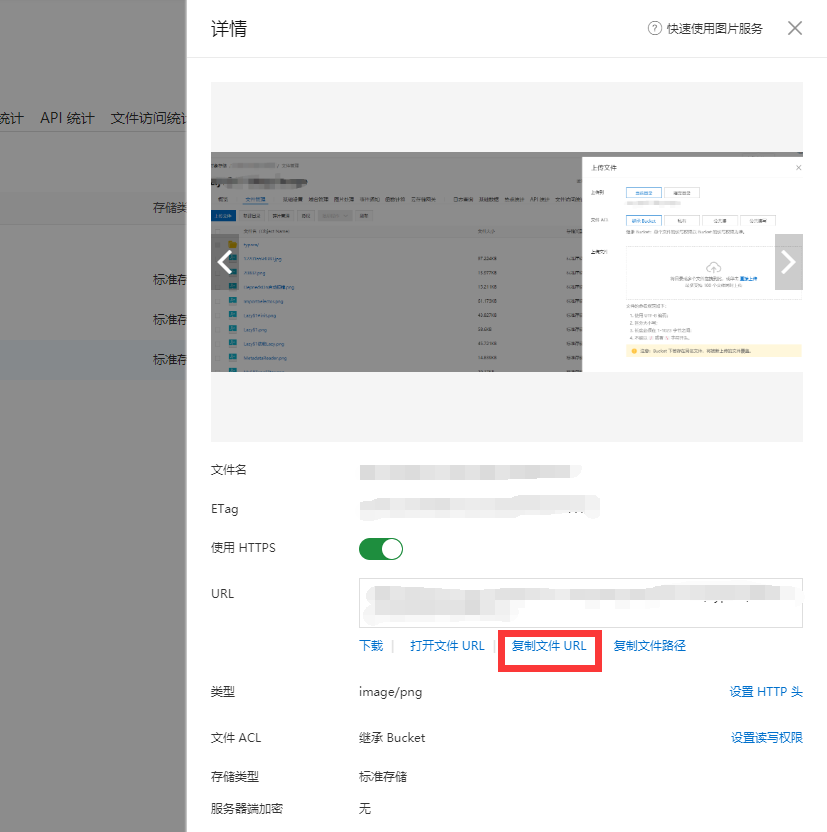

这真的真的相当麻烦。(:з」∠)
所以图床就是用来解决这个问题,但是之前用的图床(之前用过chrome的一个图床插件)都是也只是省去了你登录对象存储在页面上上传的这一步,最后就还是要复制生成的url然后到typora的文章中。
这里就在网上搜了下typora的图床,看看有没有符合自己偷懒的想法的做法,一键截图之后复制到typora中然后就可以了。
然后就是Google搜了下,发现第一条就是日常学(划)习(水)的网站——知乎。
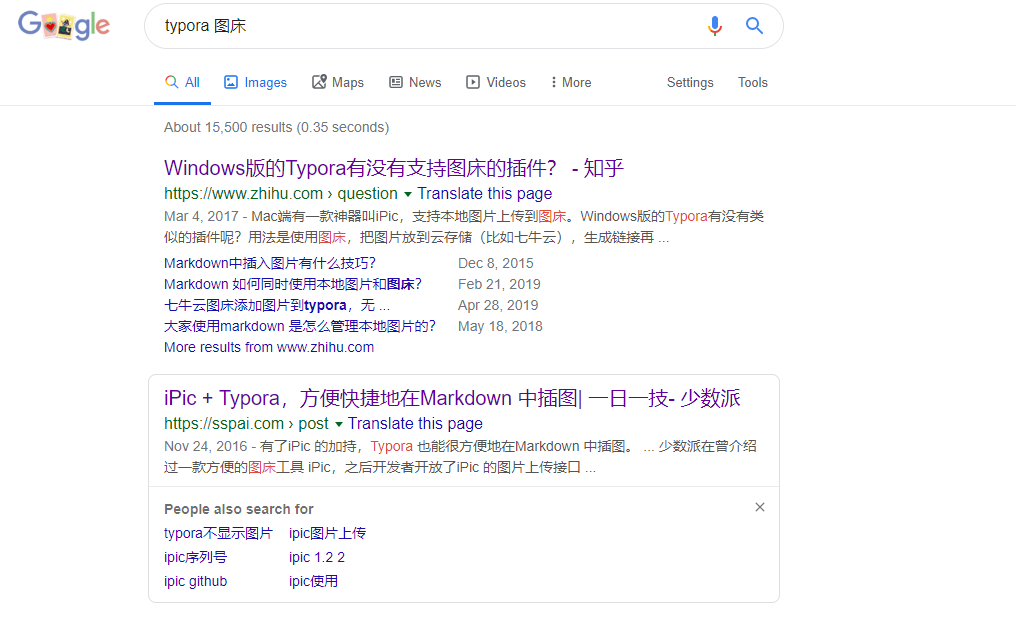
于是就点开之后看到了typora的这个插件,进而有了这个文章
首先贴一下这个插件的地址:github
这个文档中和知乎的回答差不多,我们可以直接来到使用这里开始:

下载插件的代码到本地,这里不熟悉的github的同学可以直接点击图中的download zip即可。
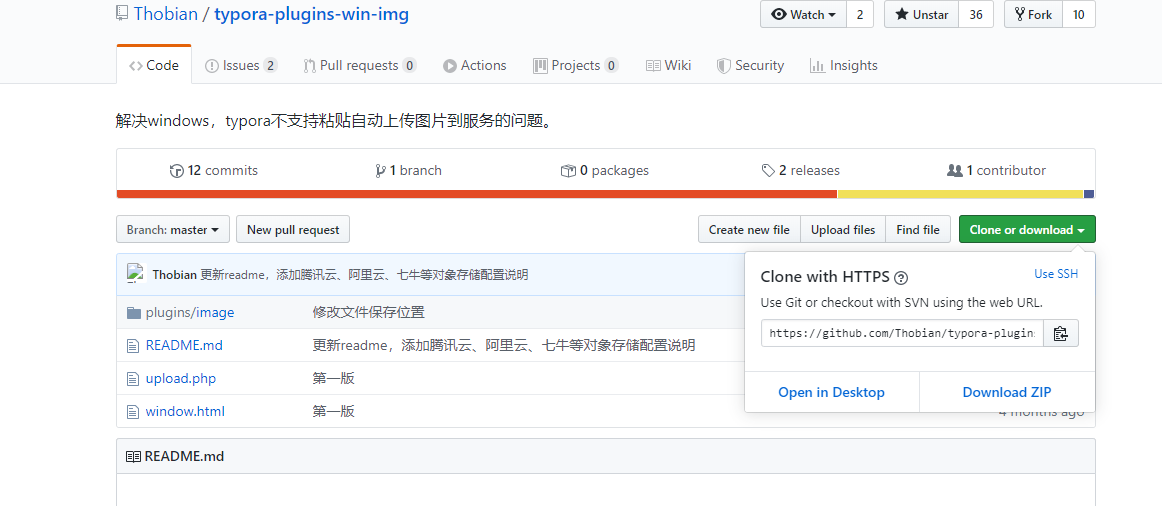
解压之后可以看到有这些文件,和github上的目录对应
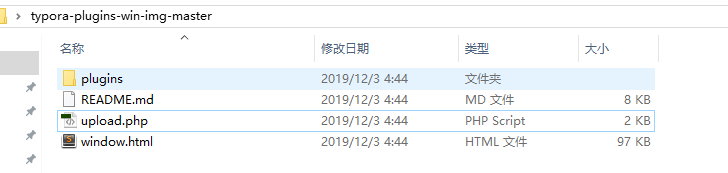
然后按照文档上的教程手工替换(复制plugins目录、替换window.html)到对应的typora安装目录下的resource\app目录下。替换完成之后的目录长这个样子。
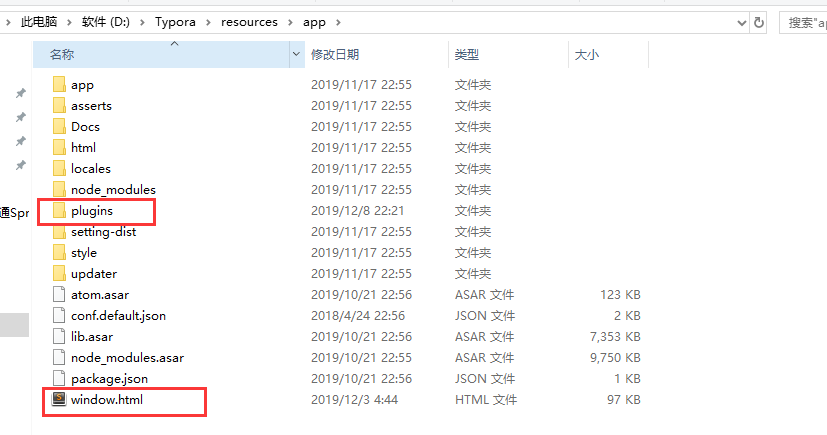
然后就是对里面的代码进行自己OSS的配置了。
打开plugins–>image–>upload.js文件(这里可以直接用记事本打开js文件,当然程序员自动sublime或者vscode。),拉到底就可以看到文档中说的init相关的代码。

然后复制文档上的阿里云这段配置,把整个473行替换掉。
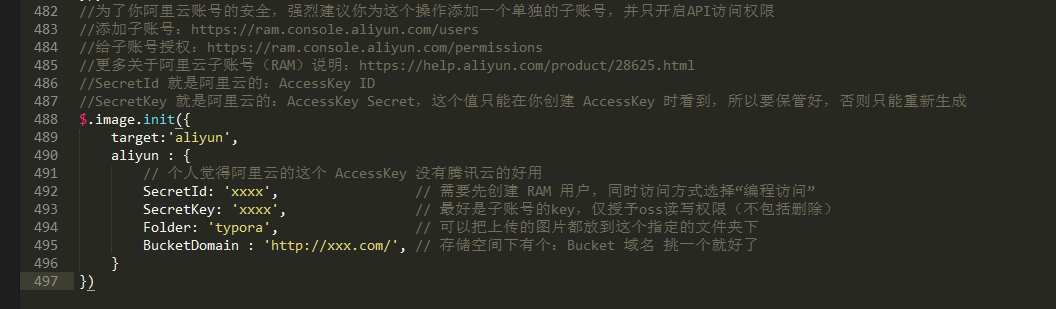
接下来就按照注释(“//“后面的东西)来操作即可。
首先插件作者建议你添加一个子账号来单独操作你的OSS,这里简单理解下就是在你的阿里云上你可以建立多个用户组,而每个用户组中可以建立多个子用户,通过对用户组或者用户来设置权限达到一定操作。插件其实是用代码去调用阿里云提供的API来操作上传图片的,所以你肯定要在本地的typora的配置代码里填上一个关联你OSS的账号并且配置对应的权限才能成功上传图片;同时,出于安全考虑,你的这个账号应该只对你的OSS有写入和读的操作权限,所以建议来个子账号专门搞这个事情。
作者其实这里写的也很明白了,包括申请子用户的地址:https://ram.console.aliyun.com/users
打开之后点击新建用户,即可看到让你填用户账户信息。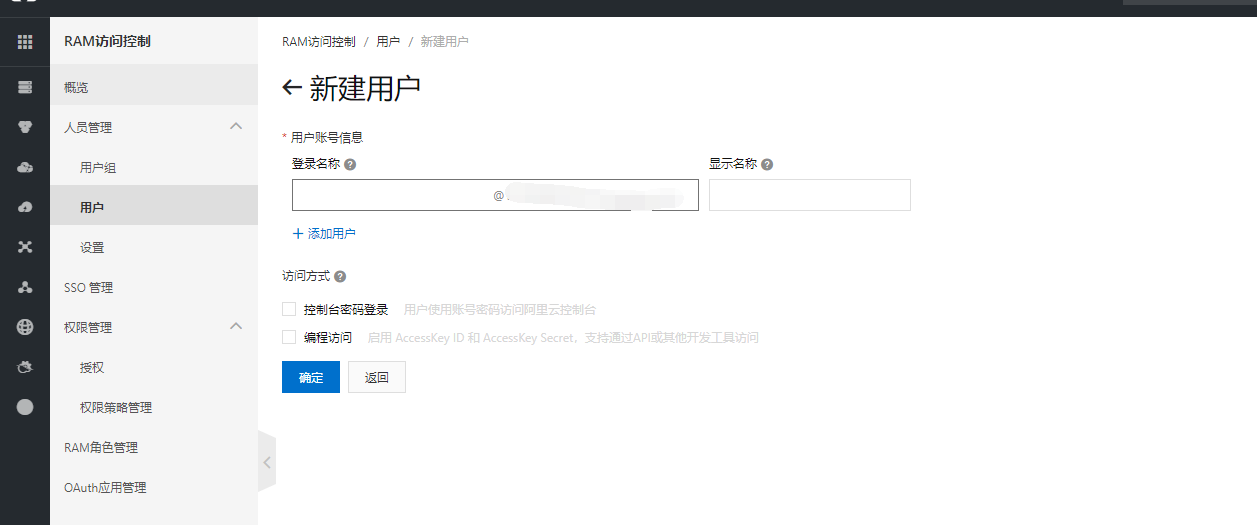
当然这里也可以直接添加用户组,然后在组下面添加用户。
填写你想要的登录名称(复杂点也没关系,在后面配置一般是关键字搜索选择的)、显示名称和勾选上编程访问。这里的编程访问我们也可以清楚看到是通过assess信息来支持开发者调用API访问的用户。
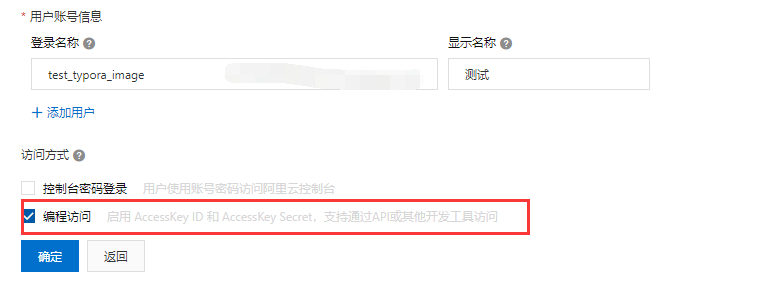
点击确定,这时要收一个验证码:
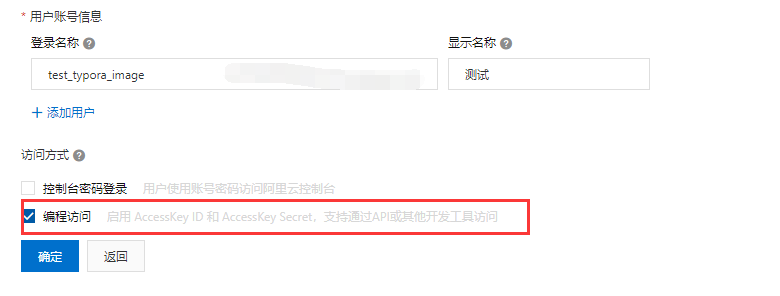
填写完之后这步很关键,可以看到会在页面上告知你一个accessKeyId和accessKeySercret,但是坑的地方是这个授权key的值只有在创建的这个页面才能看到,之后就看不到了,所以这里一定要进行复制或者保存这两个值。可以看到页面上也提供了对这两个值的复制功能。

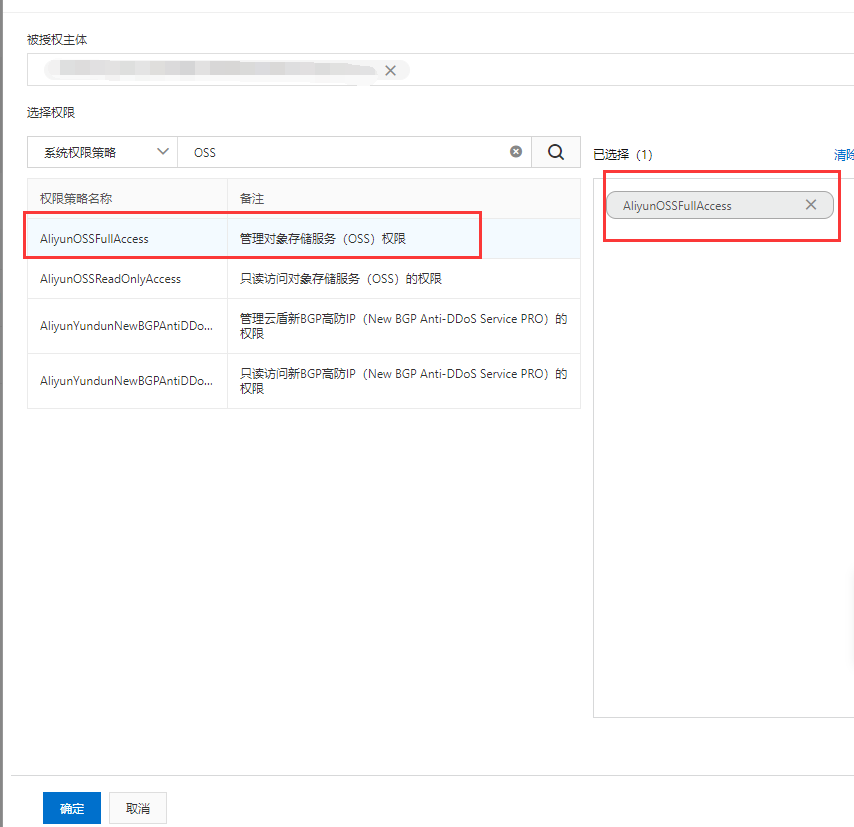
这时候就要给这个用户去设置权限。刚创建的子用户是没有任何权限的,这里你既然要对OSS进行上传写入的操作,肯定要给这个账户权限,可以看到在用户界面有拟刚才创建的子用户,并且可以配置权限

这里在权限搜索框内输入OSS,就可以看到我们要配置的权限(管理OSS的权限),点击确定即可。
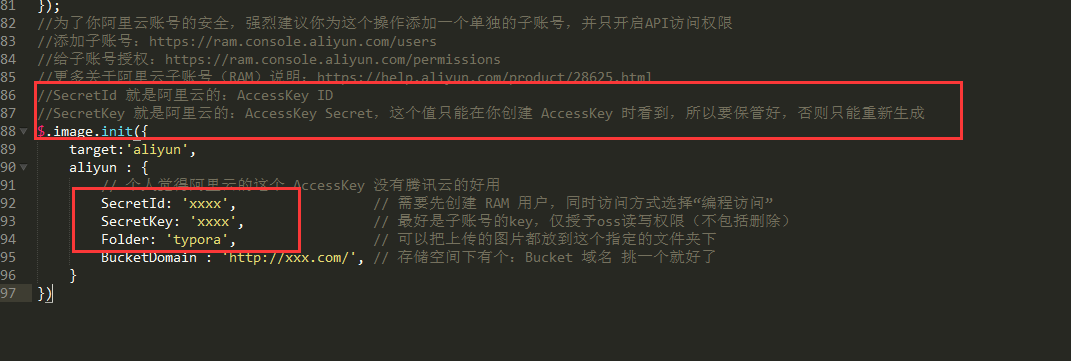
到这里,init代码中需要的前三项就都有了。
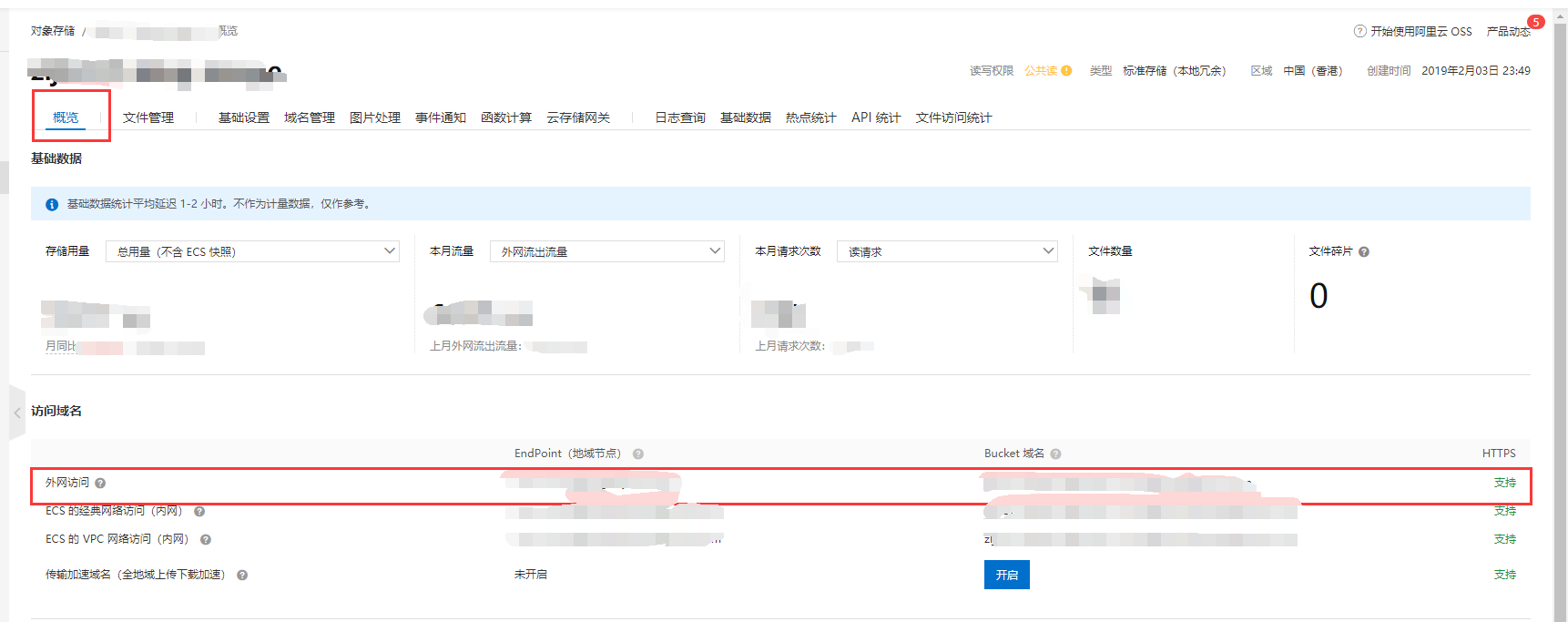
还剩个bucketDomain,这里作者其实也说的很明白了,在你的OSS概览页面上,会有对应的bucket域名,这里挑选一个即可,我挑选的是外网访问的这个bucket域名
其实文档到这步也就没有了,我就以为是OK了,然后就很有自信的去保存了修改后的js文件去试了下。果然,不行(:з」∠)。
一直在提示我服务响应解析失败,错误。之后又对了遍文档发现也没漏啥。最后还是选择去看了upload代码。
首先这个错误肯定是作者定义的,然后就在upload.js中看到了这个错误。
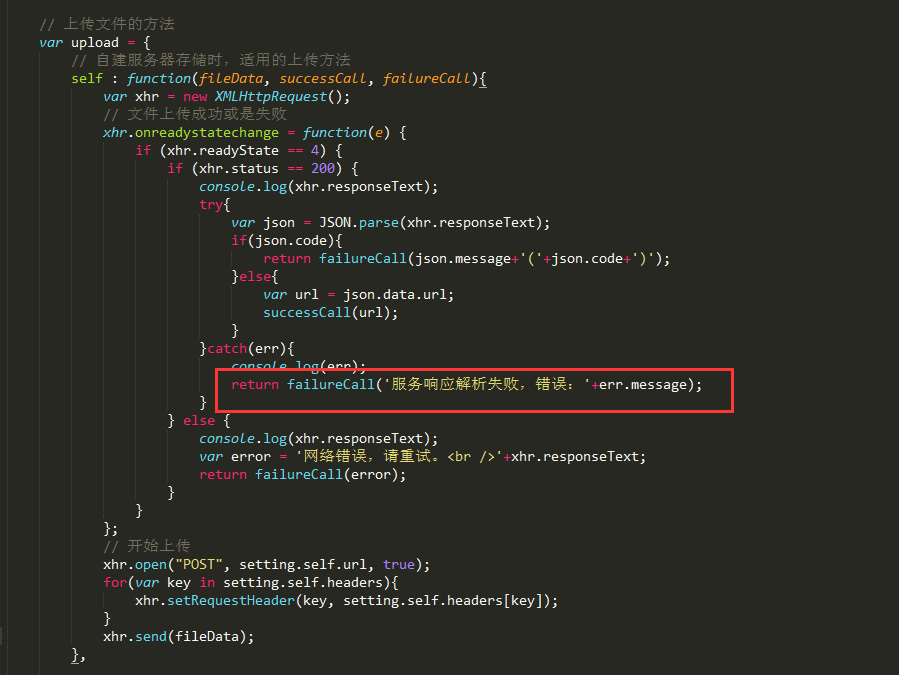
这里可以看到其实是调用接口异常了,所以返回的这个错误,所以大概率是刚才配置的问题,再往上翻才看到原来除了文件底部的init方法之外,还要去配置下代码中的setting信息,这里稍微吐槽下为啥文档里没有写(没有,就是我前端不熟就没看代码,菜是原罪= =)。
在setting配置里有这段代码: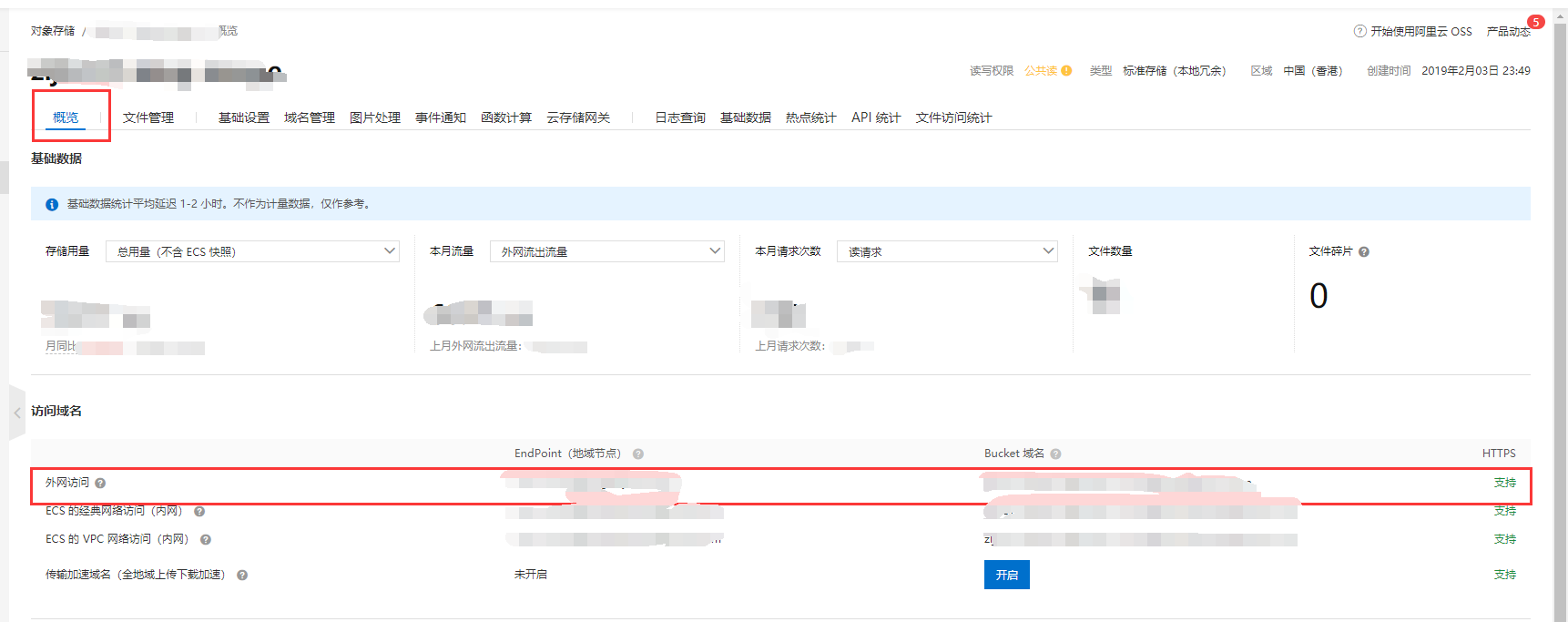
可以看到请求的域名和API访问是从这里解析的,所以你不配置这里,默认会用作者写死的jiebianjin去访问接口,当然调不通了(因为阿里云上并没有这个子用户)。这里还是刚才的accessKey信息和bucket信息。这里看到了设置了过期时间和上传的大小限制,进而手工改了下大小限制,默认是512k,我这里放大到了5M。
之后保存之后,又信心满满的去试了下,卧槽,居然还是报错。然后又对了下文档中的配置。
无奈打开了调试,typora其实就是个浏览器= =。windows下shift+f12是调试工具。这里没有把当时报错的接口的截图贴上,当时忘记截图了,这里是我在写这篇博客的时候调试截图的。通过一顿分析发现自己在配置BucketDomain的时候,忘记在最后加上一个反斜杠。这里大家在配置的过程中也可以注意下。

首先感谢插件作者 @Thobian 大佬写了这个插件,真的在typora下很方便,应该以后会比较重度使用。这里提几个建议。
ctrl+s保存,这个好像也会把我的图片再重新上传一次(不太确定),也会造成大量的相同文件。方法引用是java8引入lambda表达式之后的一个特性,在日常的开发工作中经常使用,可以看做是一种函数指针(function pointer),也可以简单看做lambda表达式的一种语法糖。
最近遇到了一个启动失败的问题,原因是在bean初始化完成之后的钩子方法中使用获取容器中bean的工具类,(对应工具类之前的一篇博客 获取springbean))。
这里具体的场景是我想实现一个bean在钩子方法中往一个策略map中注册自己作为一个策略使用,但是在启动的时候报错:

第33行代码如下:
1 | public static <T> T getBean(@NotNull Class<T> tClass) { |
可以看到可能为空的是context,这个是通过在项目中启动时注入到ApplicationContextUtil中的静态变量context,很明显是在当前这个bean启动的时候,其钩子方法去调用这个变量还没实现context的注入。
1 |
|
这里主要是一个场景,其实在bean启动的时候是依赖ApplicationContextUtil这个bean的,但是因为getBean方法都static方法,在平常业务代码中调用都是容器启动完毕的时候,所以没有问题,但是这里是想实现在bean初始化时自动通过钩子往一个map工厂中注册bean实例,且该bean没有显示的@Resource依赖ApplicationContextUtil,所以在注册的时候applicationContextutil这个bean还没初始化好,这里在这些具体策略的类上加了@DependsOn(“applicationContextUtil”)
1 |
|
这表示这个bean的初始化是依赖 applicationContextUtil 这个bean初始化完成之后(也就是静态变量上下文被注入)才去初始化的,这样启动就不会报NPE了。
如果锁具有可重入性,则称为可重入锁。synchronized和ReentrantLock都是可重入锁。其实可重入锁实际上表明了锁的分配机制:是基于线程的分配还是基于方法调用的分配。
比如代码: