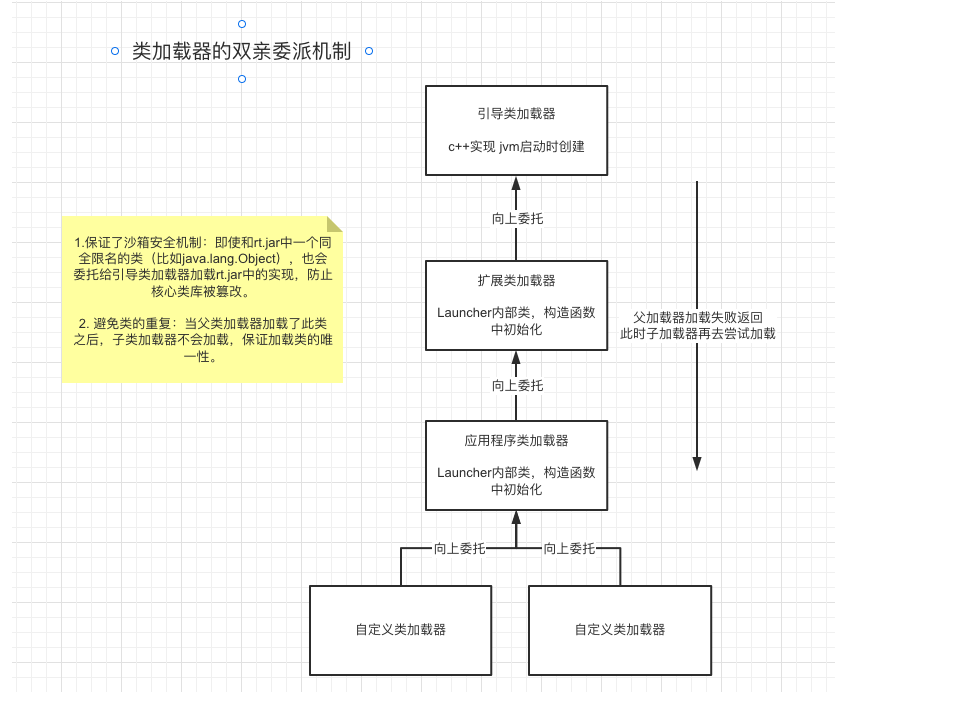
前言
dubbo内部有比较多定时任务的管理功能,JDK也提供了Timer和DelayedQueue等工具类,可以实现简单的定时任务管理,其底层实现就是使用的堆这种数据结构,存取的时间复杂度是O(nlogN),无法支持大量的定时任务。dubbo内部采用了时间轮的方式来管理定时任务。应用场景比如:dubbo的心跳机制、dubbo客户端超时检测等。
时间轮是一种高效的、批量管理的定时任务的调度模型。时间轮一般会实现一个环形结构,类似于时钟,分为很多槽,每个槽代表一个时间间隔,每个槽使用双向链表来存储定时任务;指针周期性地跳动,跳动到一个槽位,执行对应的定时任务。
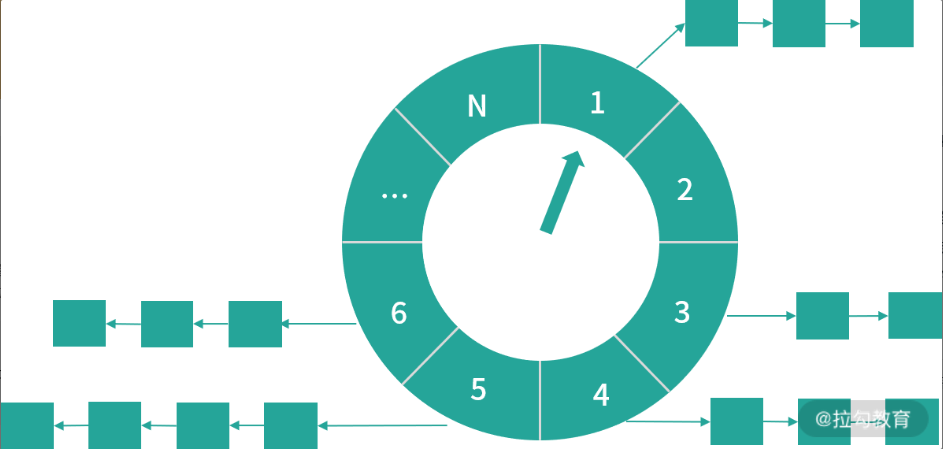
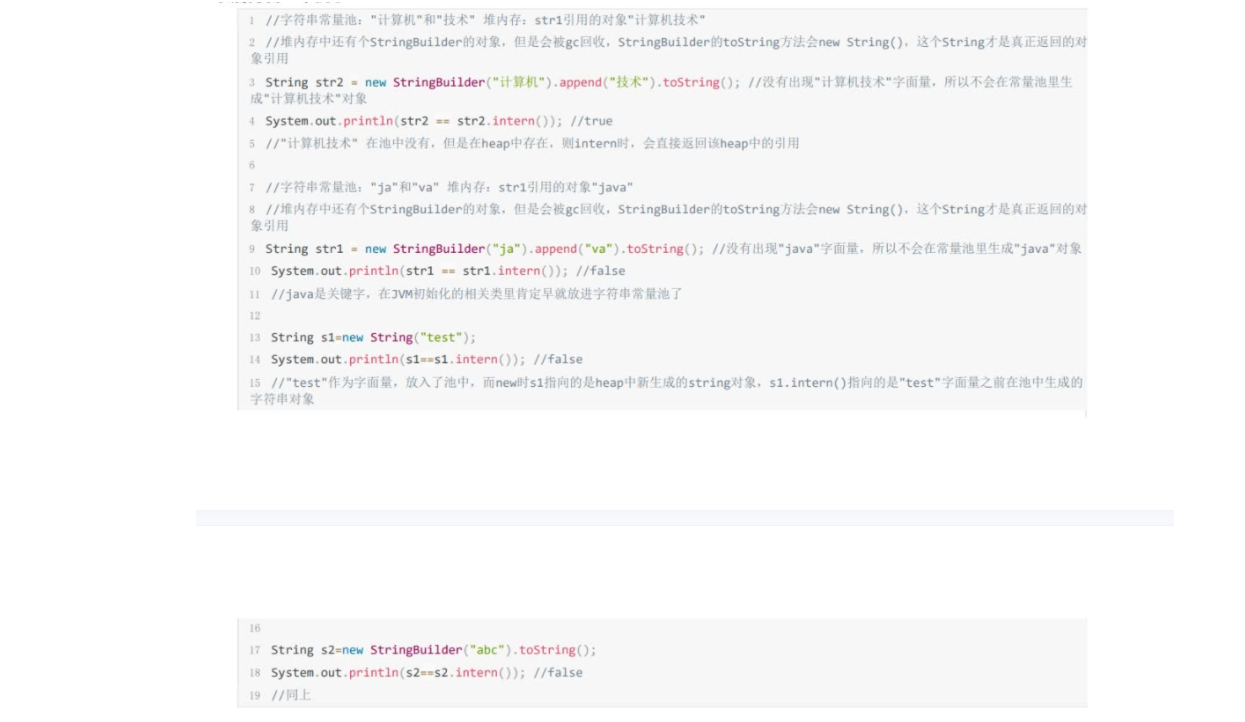
注意下单层时间轮的容量和精度是有限的,如果时间跨度特比大,精度要求很高,或者海量定时任务需要调度的场景,通常会使用多级时间轮以及持久化存储的方案。
比如多级时间轮以及持久化存储与时间轮结合,每级时间轮的时钟周期不一样,比如年级别时间轮、月级别时间轮、日级别时间轮、毫秒级别时间轮,定时任务在创建时先持久化,在时钟指针接近时预读到内存,并且需要定期清理磁盘上的过期任务。
Dubbo中,时间轮的实现方式是主要在dubbo-common的org.apache.dubbo.common.timer包中。dubbo和netty的实现基本一致,netty时间轮一个应用场景简单提下,Redisson实现分布式锁提供了watchdog锁续期的功能,为了避免每加锁一次起一个线程去扫描是否需要续期以及执行续期逻辑带来的压力,采用了netty的时间轮来注册续期任务,只用一个线程和合适的时间周期完成了续期逻辑。
核心接口
Timer接口:定义了定时器的基本行为。核心方法是newTimeout方法,提交一个定时任务(TimerTask)返回关联的Timeout对象。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36/**
* 定义了定时器的基本行为
* 核心方法是newTimeout方法:提交一个定时任务(TimerTask)并且返回关联的Timeout对象,类似于线程池中提交任务
* Schedules {@link TimerTask}s for one-time future execution in a background
* thread.
*/
public interface Timer {
/**
* Schedules the specified {@link TimerTask} for one-time execution after
* the specified delay.
* 向时间轮中提交一个定时任务
*
* @return a handle which is associated with the specified task
* @throws IllegalStateException if this timer has been {@linkplain #stop() stopped} already
* @throws RejectedExecutionException if the pending timeouts are too many and creating new timeout
* can cause instability in the system.
*/
Timeout newTimeout(TimerTask task, long delay, TimeUnit unit);
/**
* Releases all resources acquired by this {@link Timer} and cancels all
* tasks which were scheduled but not executed yet.
*
* @return the handles associated with the tasks which were canceled by
* this method
*/
Set<Timeout> stop();
/**
* the timer is stop
*
* @return true for stop
*/
boolean isStop();
}
HashedWheelTimer实现类:Timer接口的实现类。通过时间轮算法实现了一个定时器。执行过程为:
- 根据当前时间轮指针选定对应的槽。
- 遍历槽上的定时任务(HashedWheelTimeout),对每个定时任务进行计算,是当前时钟周期则去除,如果不是则将任务中的剩余时钟周期-1,代表距离执行又接近了一圈。
TimerTask接口:所有定时任务都要继承TimerTask接口。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15/**
* 所有定时任务都需要继承的接口
* A task which is executed after the delay specified with
* {@link Timer#newTimeout(TimerTask, long, TimeUnit)} (TimerTask, long, TimeUnit)}.
*/
public interface TimerTask {
/**
* Executed after the delay specified with
* {@link Timer#newTimeout(TimerTask, long, TimeUnit)}.
*
* @param timeout a handle which is associated with this task
*/
void run(Timeout timeout) throws Exception;
}
Timeout接口:TimerTask中run()方法的参数,可以查看定时任务的状态,还可以操作取消定时任务
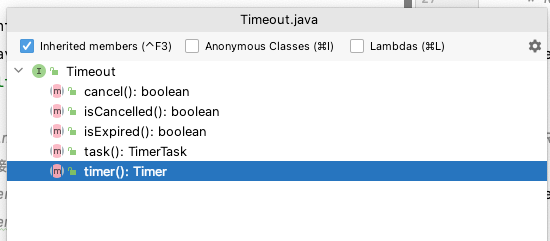
HashedWheelTimeout:Timeout接口的唯一实现,是HashedWheelTimer的内部类。扮演两个角色:
- 第一个,时间轮中双向链表的节点,即定时任务TimerTask在HashedWheelTimer中的容器
- 第二个,定时任务TimerTask提交到HashedWheelTimer之后的句柄,用于在时间轮外查看和控制定时任务。
HashedWheelTimeout的核心字段
1 | /** |
HashedWheelTimeout的核心方法
- isCancelled()、isExpired()、state()方法:主要用来检查HashedWheelTimeout的状态。
- cancel()方法:将当前HashedWheelTimeout状态设置为CANCELLED,将当前HashedWheelTimeout添加到canceledTimeouts队列等待销毁。
- expire()方法:当任务到期时,会调用该方法将当前HashedWheelTimeout设置为Expired状态,然后调用其中的TimerTask的run()方法执行定时任务。
- remove()方法:将当前的HashedWheelTimeout从时间轮中删除。
HashedWheelTimer 时间轮
上面有提到HashedWheelTimer实现类是时间轮的具体实现,工作原理是根据当前时间轮的指针选定对应的槽(HashedWheelBucket),从双向链表的头节点开始迭代,对每个HashedWheelTimeout进行计算,属于当前时钟周期则取出运行,不属于则将其时钟周期-1,等待下一圈的判断。
核心字段
1 | // 实现了Timer接口 通过时间轮算法实现了一个定时器 |
newTimeout方法提交定时任务
1 | // 时间轮 去加入一个新的任务 |
newTimeout主要做了几件事:
- 维护了时间轮中剩余定时任务数量字段
- start()方法
- 计算了时间轮的startTime方法,且修改时间轮的状态
- worker线程调用start()方法,开启执行扫描时间轮的线程。
- 根据startTime来计算定时任务要调度的deadline,当前时间+延时时间 - 启动时间。
- 封装task为HashedWheelTimeout添加到timeouts执行队列中。
worker线程扫描时间轮并执行任务
在worker线程的run()方法中:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87private final class Worker implements Runnable {
private final Set<Timeout> unprocessedTimeouts = new HashSet<Timeout>();
// tick周期
private long tick;
public void run() {
// Initialize the startTime.
startTime = System.nanoTime();
if (startTime == 0) {
// We use 0 as an indicator for the uninitialized value here, so make sure it's not 0 when initialized.
startTime = 1;
}
// Notify the other threads waiting for the initialization at start().唤醒外边的线程
startTimeInitialized.countDown();
do {
// 等待下一个执行周期 即槽之间的时间间隔 比如每个槽之间是1s执行一次
final long deadline = waitForNextTick();
if (deadline > 0) {
// 确认索引
int idx = (int) (tick & mask);
// 清理已取消的定时任务
processCancelledTasks();
// 对应的槽
HashedWheelBucket bucket =
wheel[idx];
// 转移缓存在timeouts队列中的已提交定时任务到时间轮对应的槽中
transferTimeoutsToBuckets();
// 处理当前槽中的定时任务
bucket.expireTimeouts(deadline);
tick++;
}
} while (WORKER_STATE_UPDATER.get(HashedWheelTimer.this) == WORKER_STATE_STARTED); // 模拟时间轮转动
// Fill the unprocessedTimeouts so we can return them from stop() method.
for (HashedWheelBucket bucket : wheel) {
bucket.clearTimeouts(unprocessedTimeouts);
}
for (; ; ) {
HashedWheelTimeout timeout = timeouts.poll();
if (timeout == null) {
break;
}
if (!timeout.isCancelled()) {
// 状态变更之后 未被加入到槽中的未取消任务加入到unprocessedTimeouts队列
unprocessedTimeouts.add(timeout);
}
}
processCancelledTasks();
}
// bucket.expireTimeouts 执行定时任务
/**
* Expire all {@link HashedWheelTimeout}s for the given {@code deadline}.
* 遍历双向链表中的全部 HashedWheelTimeout 节点。 在处理到期的定时任务时,会通过 remove() 方法取出,
* 并调用其 expire() 方法执行;对于已取消的任务,通过 remove() 方法取出后直接丢弃;对于未到期的任务,
* 会将 remainingRounds 字段(剩余时钟周期数)减一。
*/
void expireTimeouts(long deadline) {
HashedWheelTimeout timeout = head;
// process all timeouts
while (timeout != null) {
HashedWheelTimeout next = timeout.next;
if (timeout.remainingRounds <= 0) {
next = remove(timeout);
if (timeout.deadline <= deadline) {
// 调用expire 内部会执行定时任务的run方法
timeout.expire();
} else {
// The timeout was placed into a wrong slot. This should never happen.
throw new IllegalStateException(String.format(
"timeout.deadline (%d) > deadline (%d)", timeout.deadline, deadline));
}
} else if (timeout.isCancelled()) {
// 取消直接remove
next = remove(timeout);
} else {
// 未到期任务的remainingRounds - 1
timeout.remainingRounds--;
}
timeout = next;
}
}
时间轮一次转动的流程:
- 时间轮转动,时间周期开始
- 清理用户主动取消的任务,会记录在cancelledTimeouts队列中,在每次指针转动的时候,时间轮也会清理该队列。
- 将缓存在timeouts队列中的定时任务转移到时间轮对应的槽中。
- 根据当前指针定位槽,遍历双向链表,来执行对应的任务,方法实现在HashedWheelBucket.expireTimeouts方法中:
- 循环遍历双向链表,当定时任务的remainingRounds小于等于0,则说明是当前时钟周期内的任务,判断是否达到了deadline(满足时间的触发,兜底判断,一般在时钟周期内都会满足),如果满足调用expire()方法执行任务,内部会调用TimerTask的run方法,即真正的定时任务的逻辑。
- 如果用户取消,则直接remove()从链表上摘除。
- 继续遍历下一个Timeout节点。
- 时间轮一直是运行状态,则重复上述轮询的操作;如果时间轮为停止状态,则遍历每个槽位,来清除注册的定时任务。最后再清理cancelledTimeouts队列中用户取消的任务。
Dubbo中时间轮的应用
客户端的超时检查
客户端发起调用时会创建一个DefaultFuture,用于发起远程调用且阻塞同步等待结果。
1 | // DefaultFuture的newFuture方法 |
可以看到timeoutCheck方法中创建了一个TimeoutCheckTask(实现了TimerTask接口),然后利用时间轮调用newTimeout加入了一个定时任务。
客户端检查超时公用的时间轮:1
2
3
4public static final Timer TIME_OUT_TIMER = new HashedWheelTimer(
new NamedThreadFactory("dubbo-future-timeout", true),
30,
TimeUnit.MILLISECONDS);
TimeoutCheckTask的逻辑:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41// 超时检查的任务
private static class TimeoutCheckTask implements TimerTask {
private final Long requestID;
TimeoutCheckTask(Long requestID) {
this.requestID = requestID;
}
// 超时检查的逻辑 在达到对应的超时时间触发
public void run(Timeout timeout) {
// 根据requestId从Future缓存中获取future
DefaultFuture future = DefaultFuture.getFuture(requestID);
//
if (future == null || future.isDone()) {
// 完成正常返回
return;
}
// 否则响应超时 isSent区分是客户端执行超时,还是服务端的超时。
if (future.getExecutor() != null) {
future.getExecutor().execute(() -> notifyTimeout(future));
} else {
notifyTimeout(future);
}
}
private void notifyTimeout(DefaultFuture future) {
// create exception response.
// 客户端在超时之后创建一个超时的返回
Response timeoutResponse = new Response(future.getId());
// set timeout status.
// 根据future的isSent确定状态是客户端响应超时 还是 服务端响应超时
timeoutResponse.setStatus(future.isSent() ? Response.SERVER_TIMEOUT : Response.CLIENT_TIMEOUT);
timeoutResponse.setErrorMessage(future.getTimeoutMessage(true));
// handle response.
// 响应超时
DefaultFuture.received(future.getChannel(), timeoutResponse, true);
}
}
与注册中心交互的失败重试
1 | private void addFailedRegistered(URL url) { |
其中FailedRegisteredTask是TimerTask的实现,代表一个失败重新注册到注册中心的任务,内部就是调用了注册服务的逻辑(比如zk去创建临时节点);retryTimer是一个时间轮,30毫秒去转动指针扫描槽来执行任务。
1 | // Timer for failure retry, regular check if there is a request for failure, and if there is, an unlimited retry |