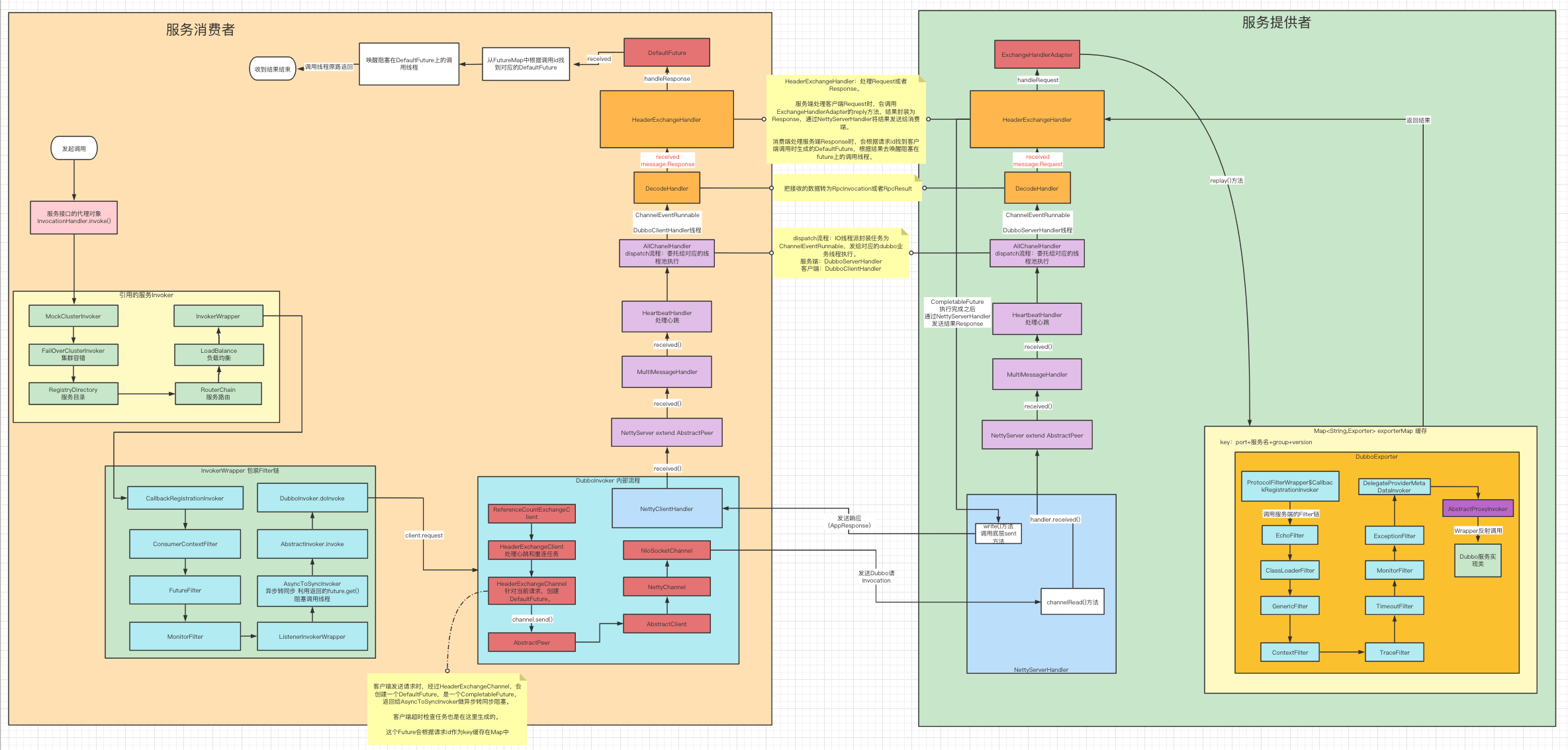
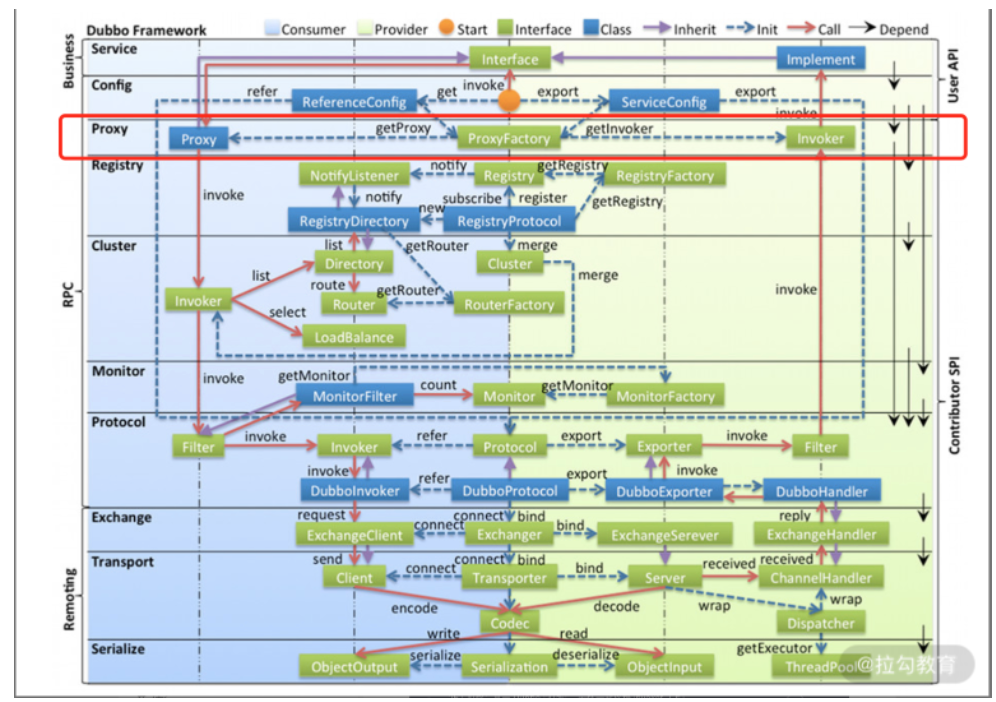
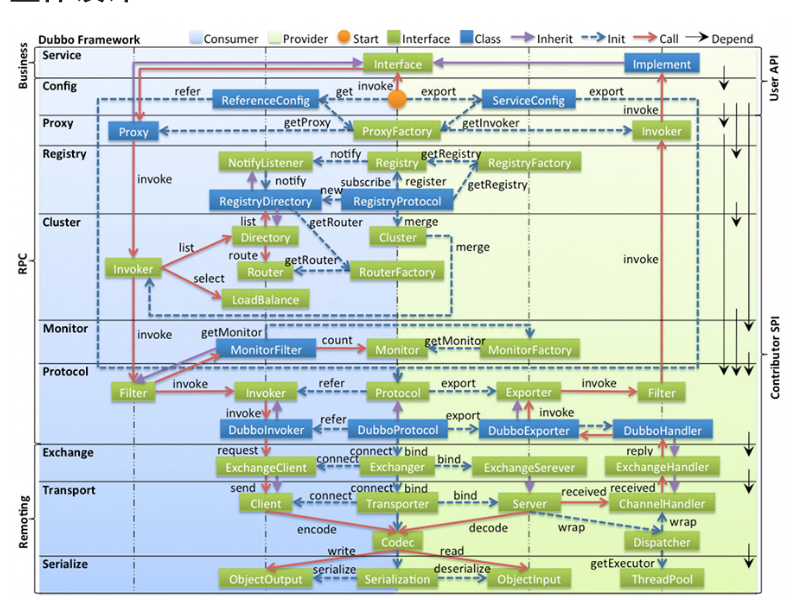
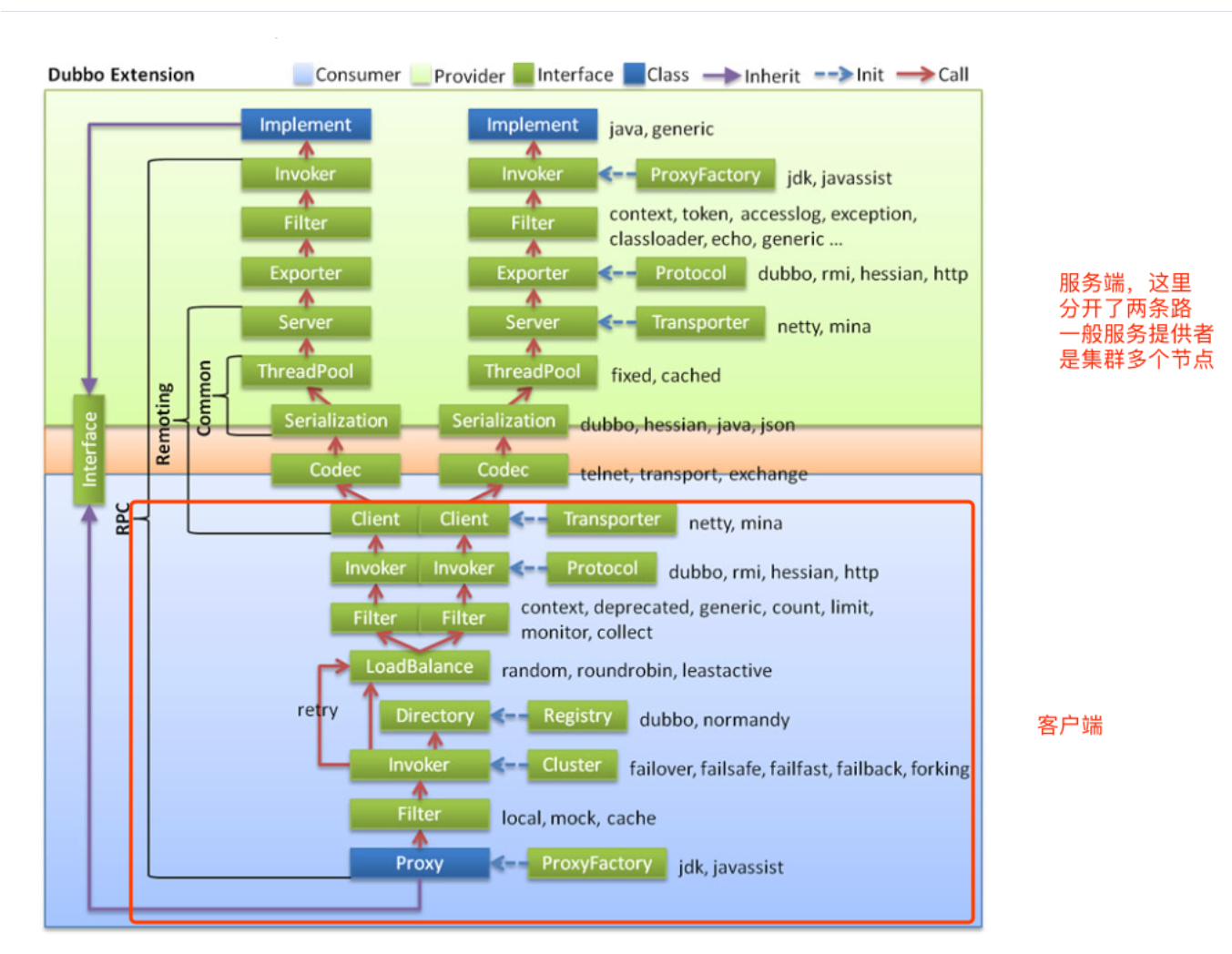
基本原则
对于秒杀商品的库存设计应该遵守的几个原则:
- 渠道隔离:秒杀活动中使用的库存应当按照渠道进行隔离,这样既能保证不对正常售卖渠道产生影响,又有利于精细化运作库存管理。比如,根据用户群体或平台支持的力度不同,我们可能需要在不同渠道透出不同的库存数量,并且它们与正常售卖渠道分离,这种场景下就需要渠道隔离;
- 防止超卖:业务来说,超卖可能意味着资损;对技术来说,超卖意味着架构的失败。试想,原价999元商品的秒杀价为599,库存100件却卖出了10000件,那么我们就会面临严重的客诉或资损;
- 防止重复扣减:与超卖相对的是没有卖出去,其同样不可小觑。比如,10000件的库存仅有10人成单,库存明明还在却显示已经售罄,活动未到达预期,前期准备和推广的资金投入都打了水漂,而由系统设计缺陷造成的重复扣减 就会导致这种糟糕的情况发生;也就是同时也防止少卖。
- 高性能:在前面的文章我们谈到了如何通过缓存提高秒杀架构中的”读“性能,殊不知”写“性能也是秒杀架构的重要指标之一。举例来说,10000比订单,每秒写入300单和每秒写入3000单在用户体验上有着显著的差异。
常用库存扣减方案
基于数据库的库存扣减方案
顾名思义,基于数据库的库存扣减方案指的是利用数据库的特性在数据库层面完成库存扣减。这种方式实现起来比较简单,对于并发量低或库存低的场景,推荐使用这种方案。所谓库存低,指的是当库存很少时,我们只要把大流量拦截在应用之外或数据库之外即可,确保数据库的并发量处于低位。否则,在高并发写入的场景下,这种方案是不合适的
基于缓存的库存扣减方案
既然数据库方案无法满足高并发写入场景,那么缓存是否可以呢?答案是看情况。对于Redis这种缓存,虽然速度较快,但是存在数据丢失的可能,这是我们无法接受的。所以,当我们决定使用基于缓存的扣减方案时,我们就必须考虑如何保证缓存不丢失的稳定,比如使用LevelDB等。另外,相较于数据库方案,缓存方案需要更高的实现复杂度。
分库分表库存扣减方案
解决数据库高并发的写入问题,除了使用缓存方案外,还可以采用分库分表的库存扣减方案,将库存分散到不同的库中。比如,单台数据库每秒能支撑300的库存更新,那么10台数据库即可支撑3000的并发写入。
当然,相较于前两种方案,虽然分库分表的优势明显,但具有更高的复杂性和实现成本。
常用库存扣减方式
- 下单扣库存:优势在于简单,链路短,性能好,缺点在于容易被恶意下单。活动刚开始,可能即被恶意下单清空库存;
- 支付扣库存:优势在于可以控制恶意下单,最后得到库存的都是有效订单。当然,其缺点也较为明显,无法控制下单人数,用户需要在支付时再次确认库存;
- 下单预扣库存,超时取消:相较于前两种方式,这种方式较为折中且有效,对于正常下单的用户来说抢单即是得到,对于恶意下单的来说,占据的库存会超时自动释放。