
redis底层存储数据结构
RedisKV设计原理
Redis底层数据结构
Redis底层有SDS(简单动态字符串)、链表(list)、字典(ht-hashtable)、跳跃表(SkipList)、整数集合(intset)、压缩链表(ziplist)、quicklist等数据结构。Redis使用这些底层数据结构实现key、value的存储。
Redis数据库的key和value是怎么存储的
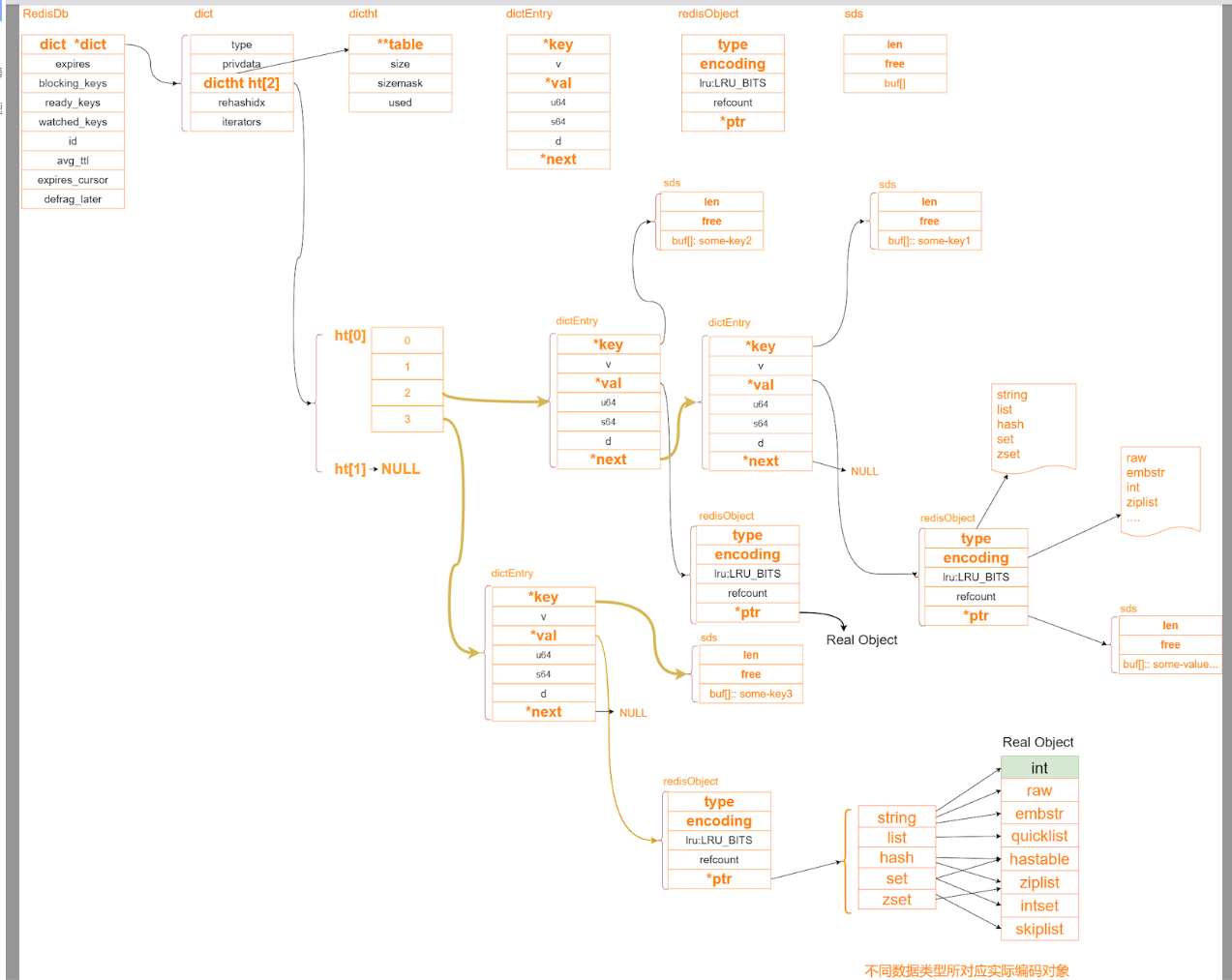
整个Redis中所有的key和value组成了一个全局字典,存储在RedisDb数据结构中。

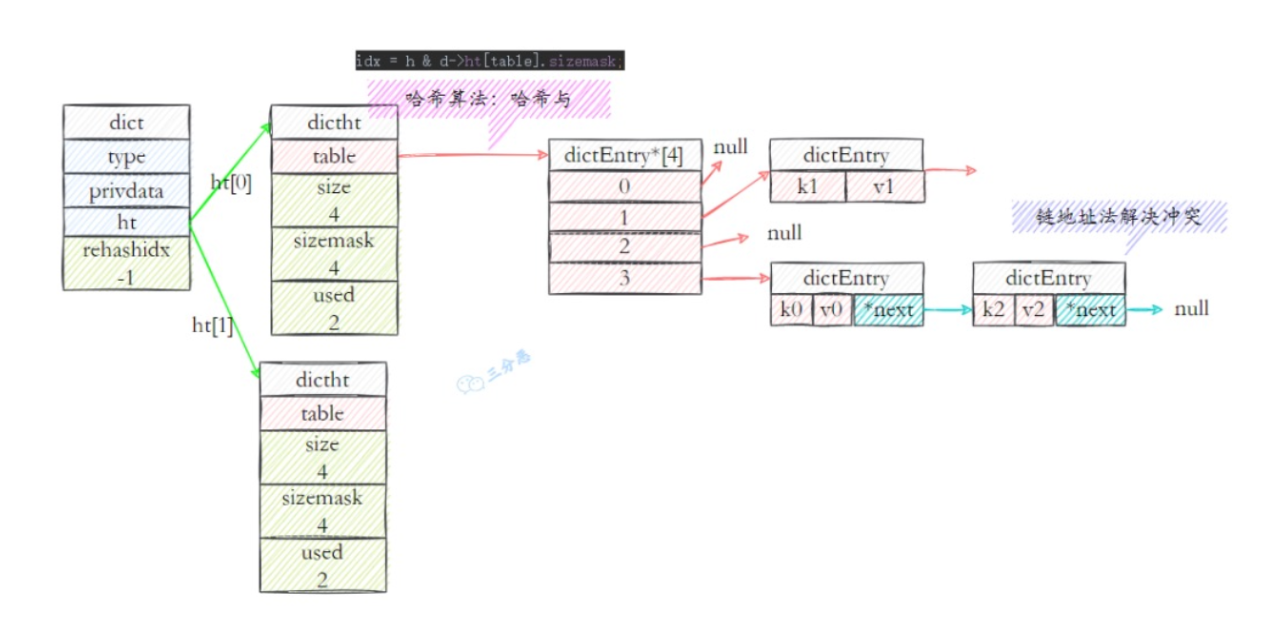
- RedisDb:结构包含一个字典dict,还包含一些过期键值对等dict字典值。
- dict:dict是字典结构,保存键值的抽象数据结构,包含两个hash表,供平时和rehash时候使用。hash表使用链地址法来解决键冲突,对hash表进行扩容或者缩容的时候,为了服务的可用性,rehash的过程不是一次性完成的,而是渐进式的。
- dictht:即字典的dict的hashtable结构,包含多个dictEntry节点的数组。
- dicEntry:真正包装key、value的抽象存储结构,包含key(key都是string类型的)和value结构。value即可以通过RedisObject包装为不同的基础数据类型。
Redis中的字典是怎么扩容的。(什么是redis的渐进式rehash)
存放dictEntry的数组在容量不足时,肯定需要扩容,上看可以看到dict中持有两个dictht 哈希表,即ht[0]和ht[1]。在扩容的时候,把ht[0]里的值rehash到ht[1],这是一个渐进式hash的过程。
- 渐进式hash:是rehash过程并不是一次性、集中式的完成的,而是分多次、渐进式的完成的。
全部rehash完成之后,h[1]就取代h[0]存储字典中的元素。
Redis中的value存储结构
value支持很多数据类型。比如String、list、hash、set、sorted set等。在redis中value(dictEntry中的val指针)是使用RedisObject表示的。
1 | typedef struct redisObejct{ |
Redis底层数据结构
常用的value基础数据类型和底层数据结构的映射关系: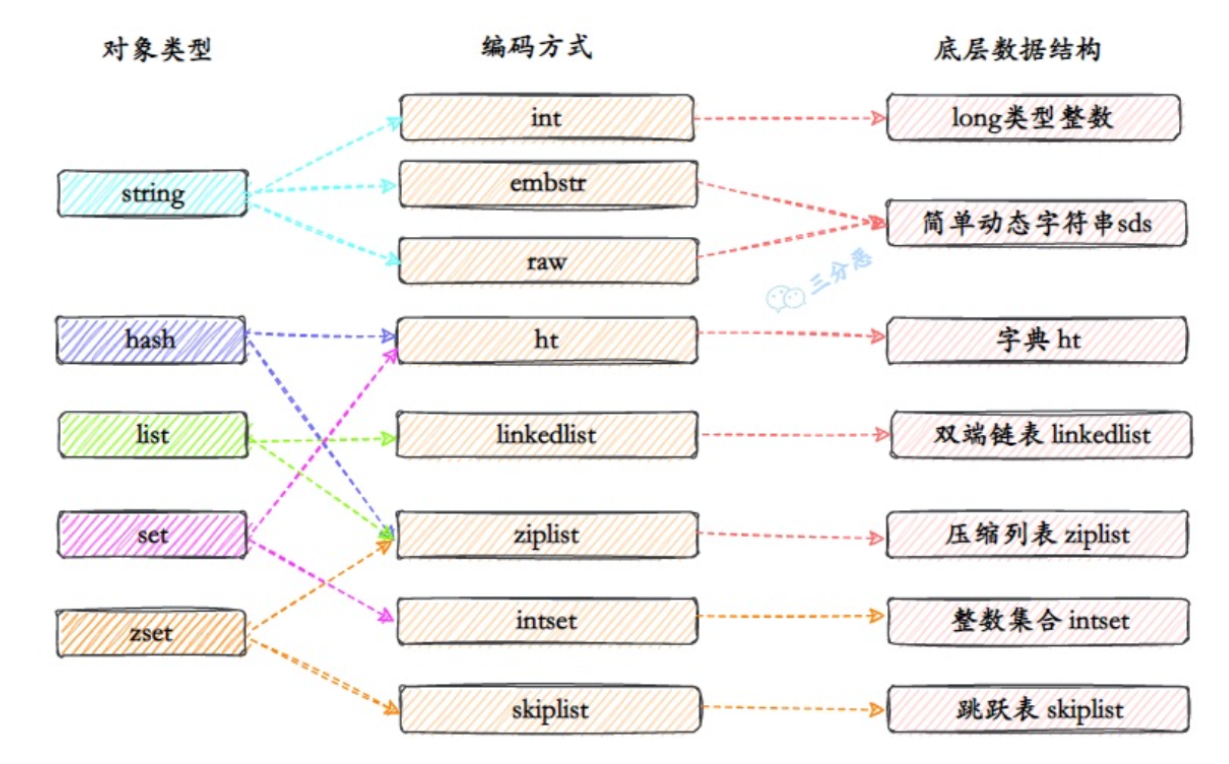
Redis中的字符串
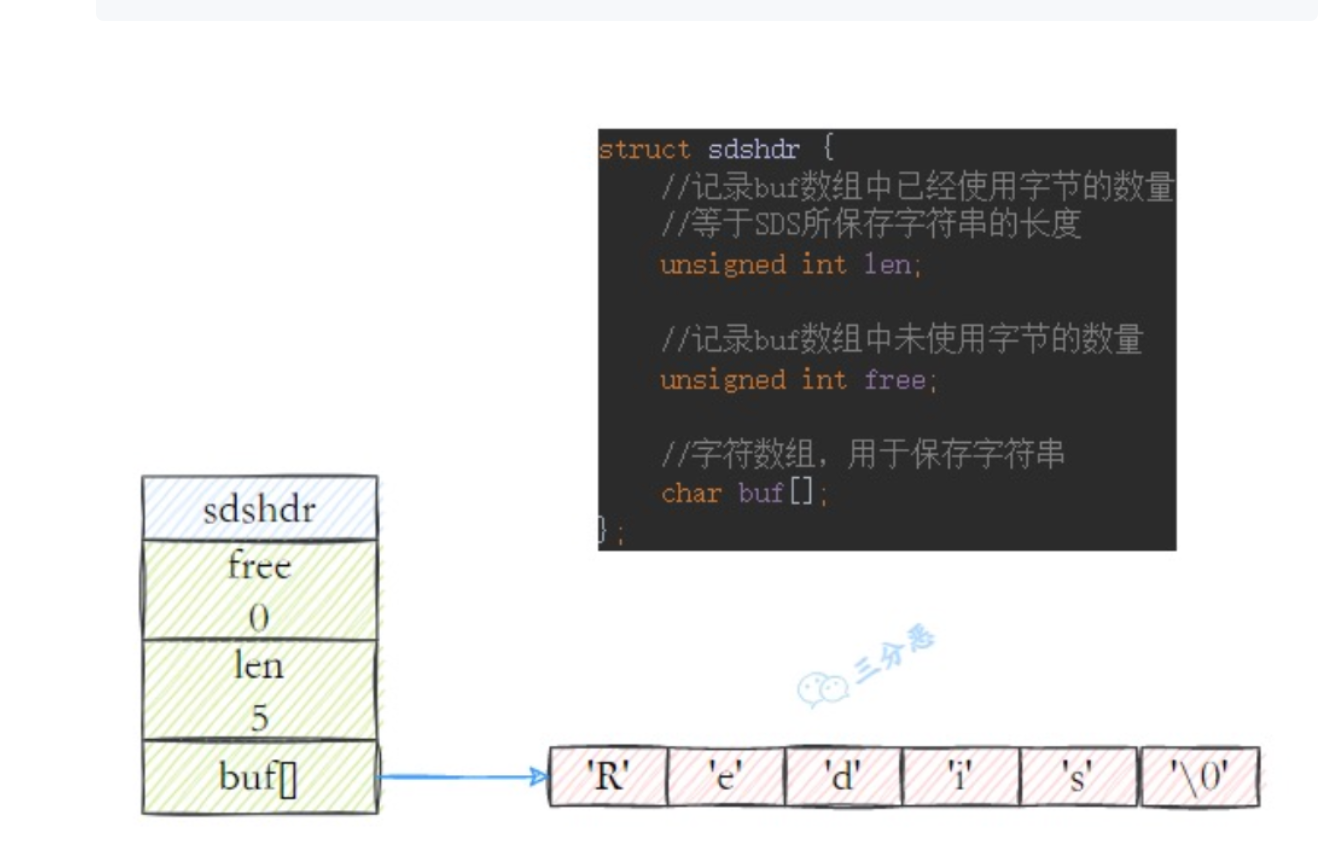
redis中所有的key都是用字符串存储的,而且redis没有直接使用c语言中的字符串。而是使用自己实现的简单动态字符串(sds)。
1 | struct sdshdr { |
Redis为什么不使用c语言字符串进行存储
C语言中的字符串使用了长度为N+1的字符数组来存储表示长度为N的字符串,并且字符数组最后一个元素总是\0。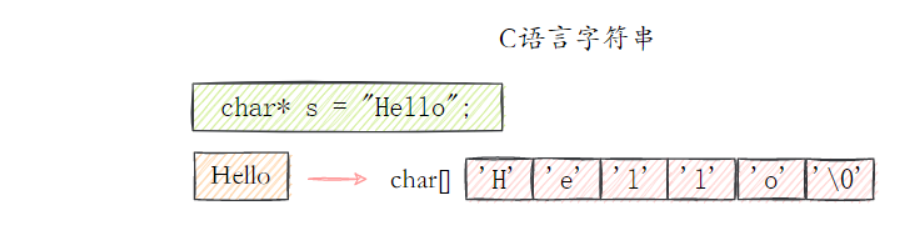
存在的问题:
- 获取字符串的效率复杂度高:C不保存字符串数组的长度,要获取长度要遍历数组。
- 不能杜绝 缓冲区溢出/内存泄漏的问题:C语言一个问题可能造成缓冲区溢出的问题,从而导致内存泄漏。
- C只能保存文本数据:C中的字符串不是二进制安全的,redis某些场景也要存储音视频文件,如果遇到字符 ‘\0’会截断不安全。
Redis的sds怎么解决的
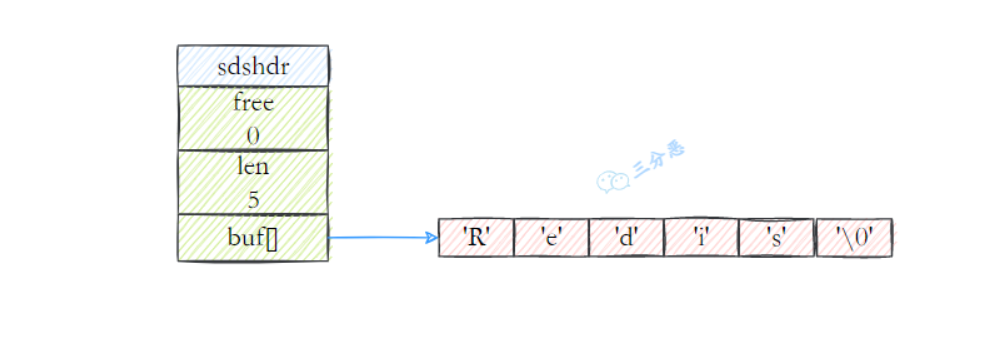
- 在sds中增加了数组长度len,获取长度直接获取。时间复杂度O(1)。
- 自动扩展空间:SDS对字符串修改时,根据free能检查是否满足修改所需的空间,不够的话SDS会自动扩容,避免了C语言存在的字符串溢出的问题。
- 预分配内存有效降低内存分配次数,避免频繁扩容分配内存。SDS在扩容时是成倍的扩容的,这种预分配的机制避免了字符数组频繁扩容。
- 二进制安全:C语言字符串只能保存ASCII码,对于图片、视频等是二进制不安全的。SDS除了兼容了C语言的字符串,同时对写入、读取不做过滤、分割,是二进制安全的。
Redis中的双端链表(linkedlist)
redis的数组结构的value可以通过list结构来实现。(list底层数据结构还有ziplist压缩列表实现)
Redis中的list是一个双向无环链表结构,每个链表的节点用listNode结构,每个节点有前驱节点和后置节点方便遍历。
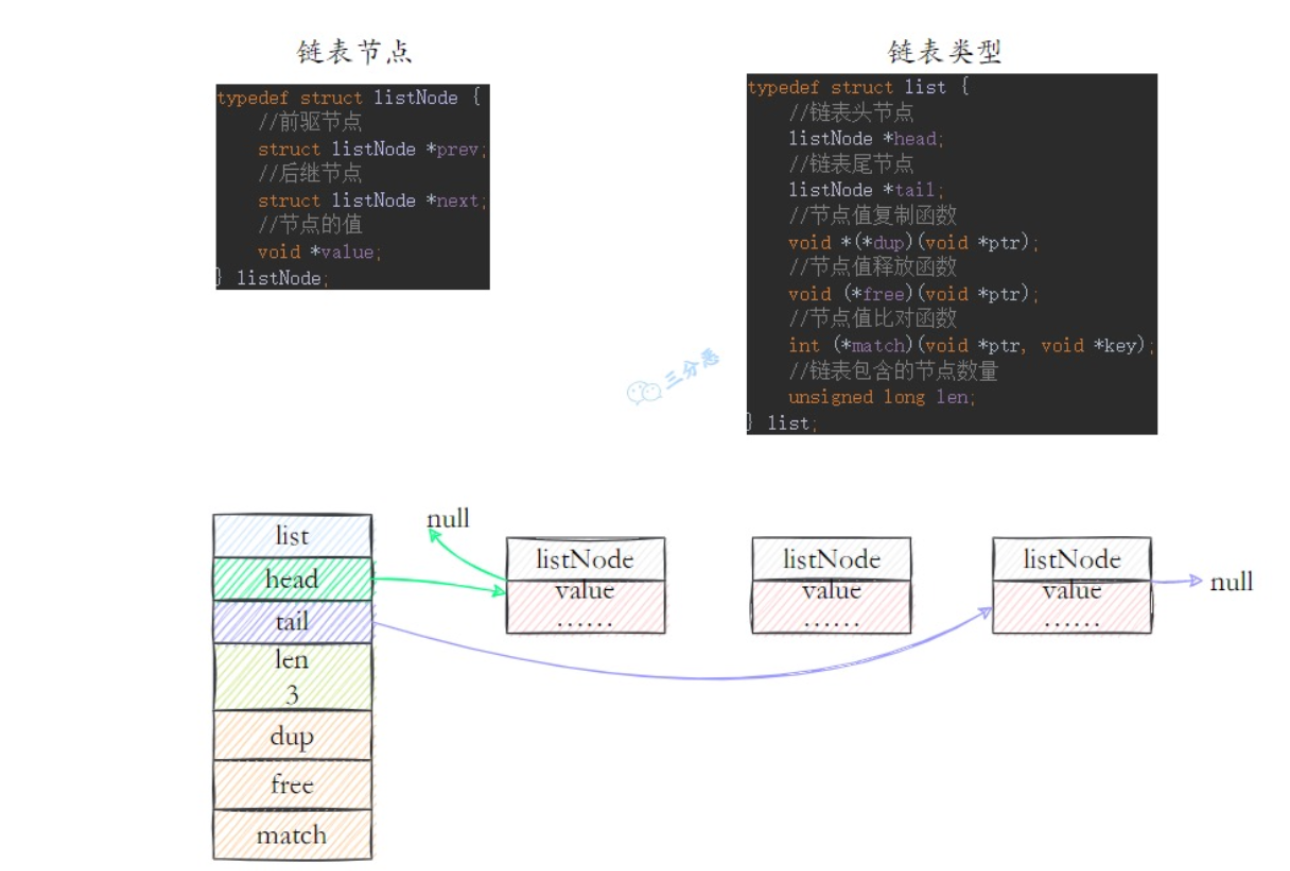
- listNode:list中的一个节点,包含value(值)和前驱和后置节点。
- list:list结构,包含head和tail节点,是维护节点。持有了链表头尾的指针。
Redis中的ziplist
压缩列表是为了节约内存而开发的线性顺序数据结构,可以包含多个节点,每个节点可以保留一个字节数组或者整数值。
ziplist是一个为Redis专门提供的底层数据结构之一,本身可以有序也可以无序。当作为list和hash的底层实现时,节点之间没有顺序;当作为zset的底层实现时,节点之间会按照大小顺序排列。

Redis中的quicklist
Redis早期版本list列表是通过压缩列表和普通的linkedlist来实现的,当元素少的时候用linkedlist,元素多的时候用ziplist。
而链表的附加空间比较高(prev和next指针),且链表内存中不连续,会有内存碎片化的问题。
在Redis 3.2版本之后对list结构的数据进行了改造,使用quicklist代替了ziplist和linkedlist。结合了空间和时间效率的考量。
quicklist其实也是由ziplist和linkedlist组成: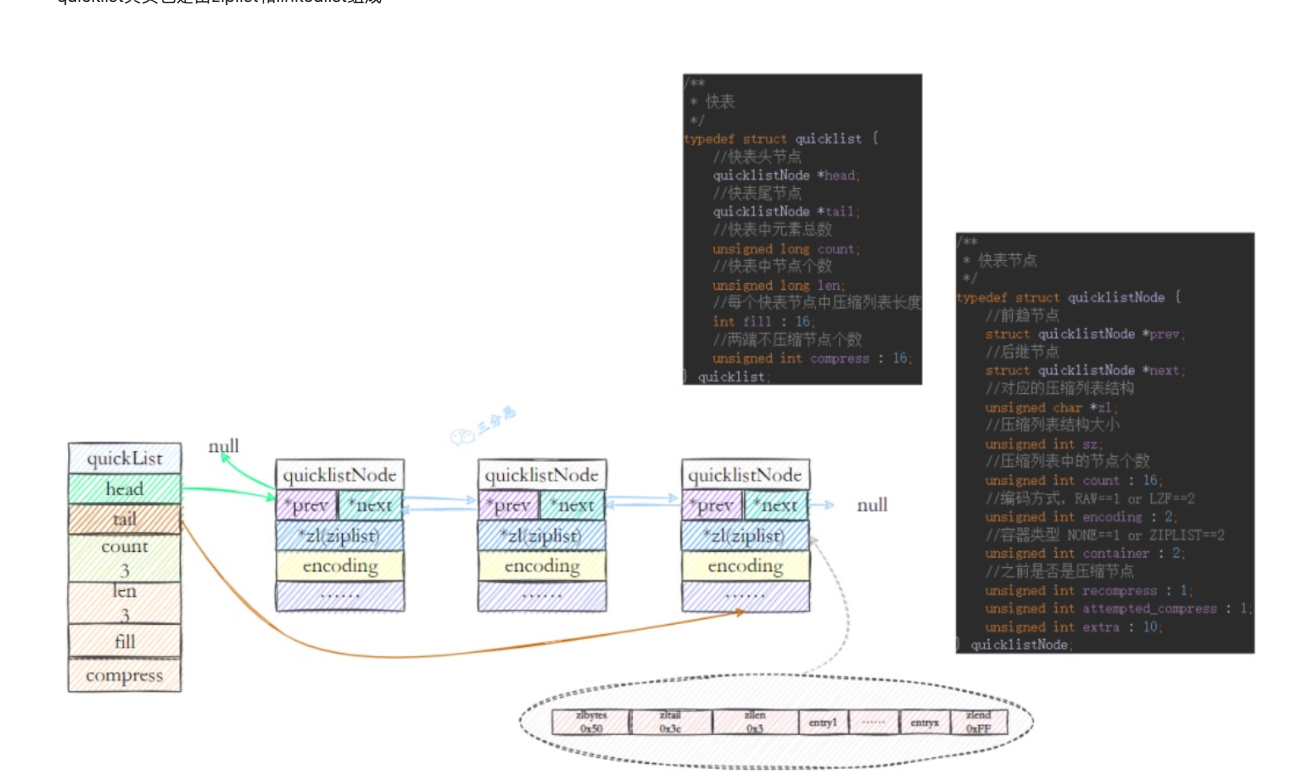
- quickList:本质还是一个linkedlist的维护节点,有头尾节点,连接的节点都是quicklistNode
- quickListNode:有前驱和后继节点,但真正的内容不再是list中的一个值,而是一个ziplist。
这样两种数据结构的优点都能使用到。
Redis中的字典table结构
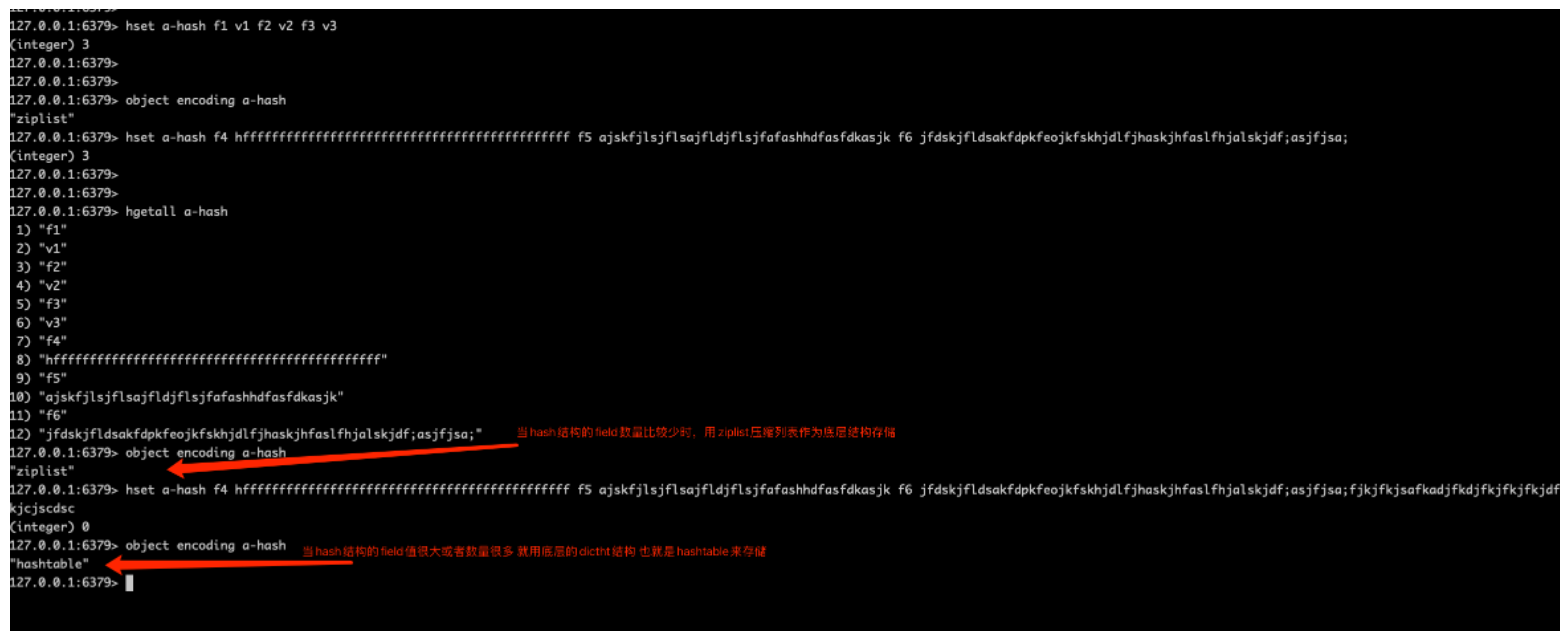
Redis中的hashtable就是dictht结构,和整体Redis kv数据存储是一个数据结构。当value是hash结构即代表value也是类型是dictht,内部每个dictEntry结构存储。
当hash结构的value元素比较少时,底层用ziplist存储(ziplist是有序的 dictht是无序的),元素数量比较大的时候会由字典来实现。由元素个数和元素大小的阈值来控制是否转变为字典结构。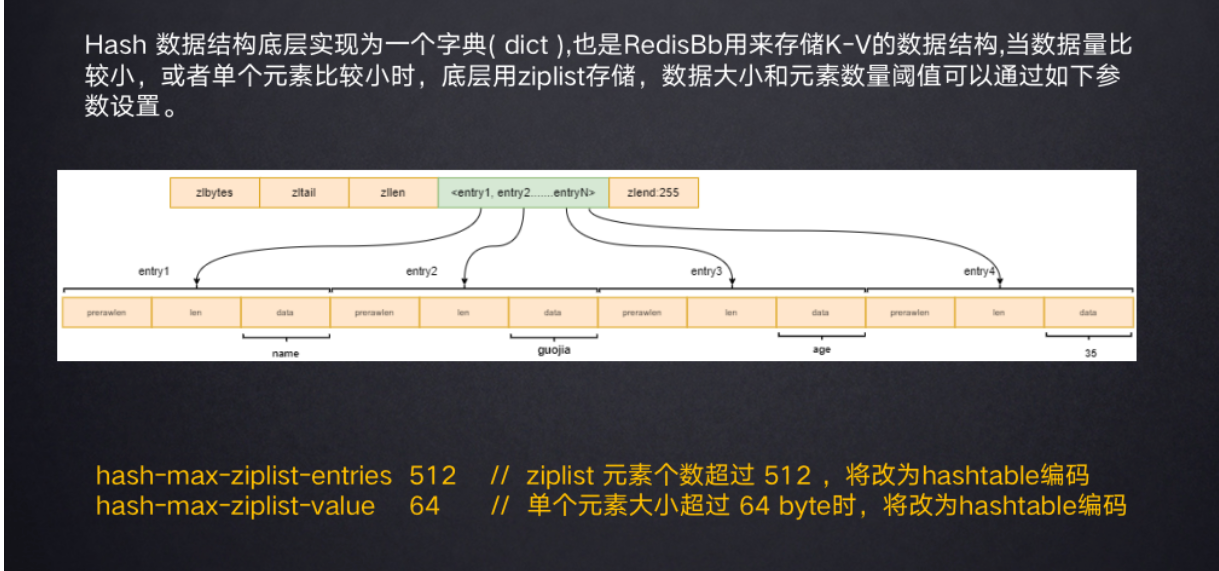
Redis中的skiplist跳表
Redis中实现有序集合,底层选用的是hashtable和跳表作为数据结构。
和hash基础数据结构一样,当数据量小的时候,zset也可以用ziplist数据结构实现,当数据量大之后采用hashtabel+skiplist。
当zset满足:
- 元素个数小于128
- 所有成员的长度都小于64字节
这两个条件时候,会采用ziplist作为底层存储结构。
当不满足任一条件时,会采用dict(hashtable) + skiplist来实现:1
2
3
4
5
6
7/* zset结构体 */
typedef struct zset {
// 字典,维护元素值和分值的映射关系
dict *dict;
// 按分值对元素值排序,支持O(logN)数量级的查找操作
zskiplist *zsl;
} zset;
- hashtable:支持zrank、zscore等直接根据key查找的命令。但hash结构无序,不能很好支持快速排序。
- skiplist:支持zrange、zrevrange等范围查找。跳表可以简单理解为简单的多层级排序链表,搜索的时间复杂度是O(LogN)。
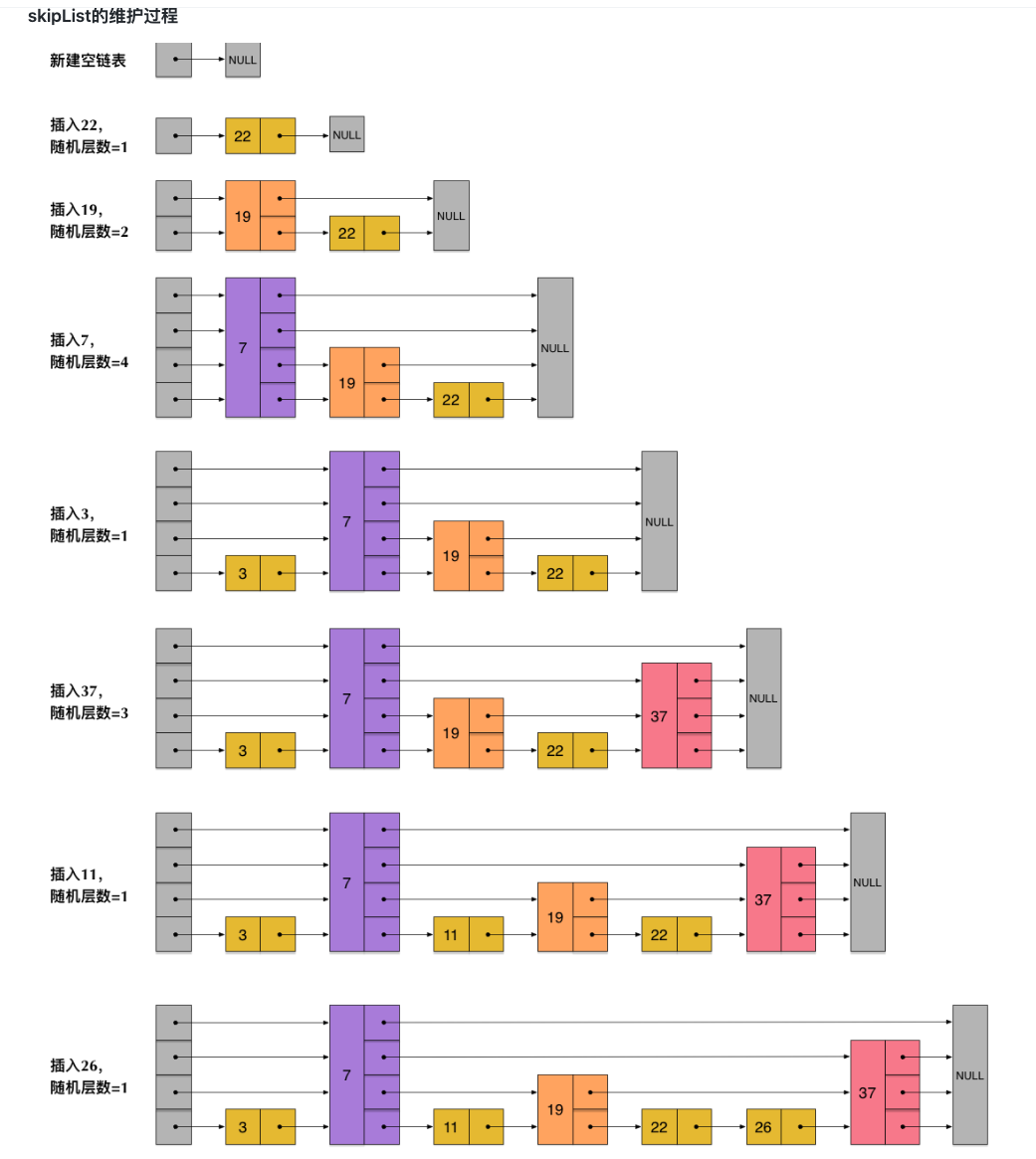
skipList在Redis中的应用:在链表增加、删除节点O(1)的时间复杂度基础上,能加入多层级的索引节点,来实现近似二分查找的时间复杂度O(LogN)数据结构。
为什么选用skiplist,而不去选择其他结构
- 有序和无序:skipList和各种平衡树(AVL、红黑树)都是有序排列的,而hash不是有序的。在hash表上只能做单key的查找,不适合范围查询。
- 范围查找:在进行范围查找的时候,树结构比跳表的操作更复杂。虽然平衡树中序遍历能找到指定范围的小指,但需要再次中序遍历才能查找到范围的大值。而跳表只需要按照上层索引节点跳到第一层(原始链表)再次遍历即可。
- 插入和删除:平衡树可能涉及到树的转换,子树的调整,实现复杂。而skiplist多层级都是链表,只需要维护对应的指针即可。
skipList的维护过程
跳表的时间复杂度和优缺点
跳表是空间换时间的一种链表基础上优化的数据结构。
链表查找的时间复杂度是O(N),借鉴数据库索引的思想,提取出关键节点(索引),先在关键节点上查找,然后下层链表继续查找。
跳表的时间复杂度是O(logN)。空间复杂度是O(N)。在新增和删除的节点的过程中,因为要维护上层索引,且排序,时间复杂度也是logN。
优点:在数据量大且读多写少的场景下,能让链表查找的时间复杂度降低,Redis底层的链表是双向链表,很好的支持了zset的范围查询。
缺点:需要更多的空间,每次插入删除都要维护上层索引,写多的场景下效率存在折中。
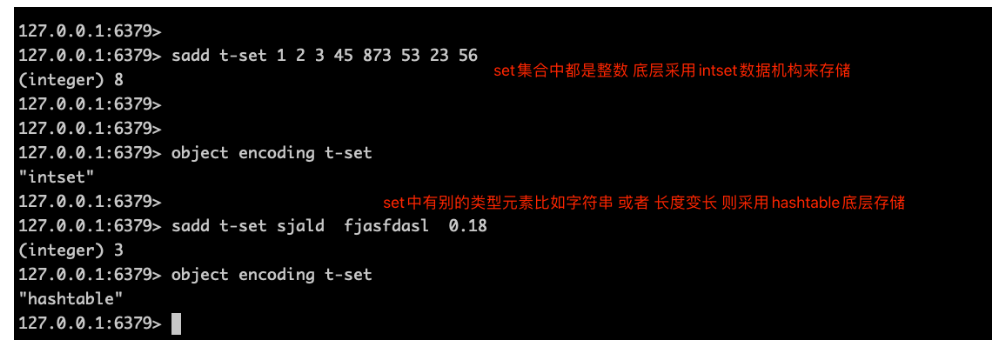
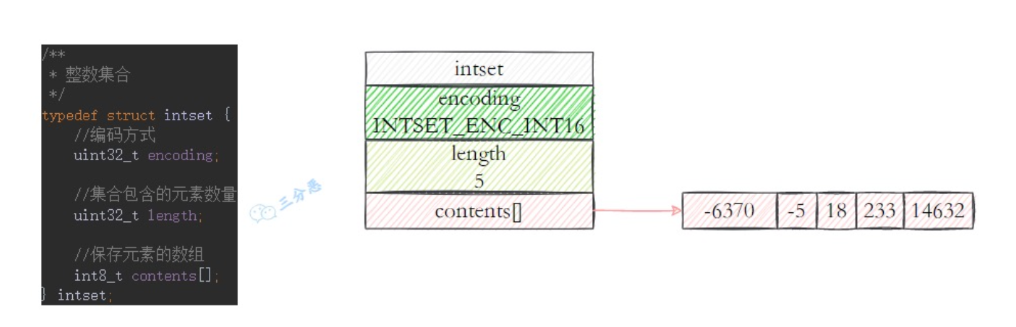
Redis中的整数集合intset
用于保存整数值的抽象数据结构,不会出现重复元素。
Redis中的set value默认是用值为null的字典ht实现的。(和java中HashMap、HashSet很像),当值元素都是整数时,使用此intset结构来存储value。
1
2
3
4
5
6
7
8
9
10typedef struct intset {
//编码方式
uint32_t encoding;
// 数组长度
uint32_t length;
// 保存元素的数组
int8_t contents[]
}
dubbo超时机制
预备知识
- 针对服务端超时,dubb之后在Filter中进行超时的日志输出,但不会阻碍执行。
- 针对客户端超时,会创建DefaultFuture的时候创建一个基于时间轮的定时任务,在客户端扫描,如果超过了超时时间,则构建一个超时异常让Future返回。
客户端如何知道请求失败?
RPC采用Netty作为底层通讯框架,非阻塞通信方式更高效,非阻塞的特性导致发送数据和接收数据是一个异步的过程,当存在服务端异常、网络问题时(比如超时)客户端是收不到响应的,如何判断一次RPC调用是失败的?
误区一:Dubbo是同步调用的吗?
dubbo在通讯层面因为采用Netty是异步的,呈现给调用者错觉是内部做了阻塞等待,实现了异步转同步。
误区二:channel.writeAndFlush返回一个channelFuture,channelFuture.isSuccess能判断请求成功了。
writeAndFlush只能表示网络缓存区写入成功,不代表发送成功。
那么Dubbo客户端感知到请求失败得自己去造了。
客户端的超时感知
客户端发起一个RPC请求时,会设置一个超时时间,发起调用的时候会开启一个定时器:
- 如果收到正常响应,删除这个定时器。
- 定时器倒计时完毕,会被认为超时,在客户端构造一个失败的返回。
Dubbo中的超时判定逻辑:
1 | public static DefaultFuture newFuture(Channel channel, Request request, int timeout, ExecutorService executor) { |
超时即调用失败,一次 RPC 调用的失败,必须以客户端收到失败响应为准。
这里关键信息在dubbo发送请求相关代码中。
1 | 发起RPC调用 |
服务端的超时判断
在服务端,超时是通过Filter机制来完成的。具体代码是在TimeoutFilter中:
1 | (group = CommonConstants.PROVIDER) |
Filter.Listener接口中的onResponse方法可以认为是在执行完此filter中的invoke方法之后,获取到的Result提供了回调机制,能触发正常返回和异常的两个回调函数。(代码在ProtocolFilterWrapper中)
可以看到这里就是在调用正常返回之后触发了一个检查,如果服务端执行超时,则会打印一个warn日志。
redis的单线程和io多路复用
redis是全部只有一个线程吗?
Redis是单线程,主要是指Redis的网络IO和键值读写是一个线程完成的,这也是Redis对外提供键值存储服务的主要流程。但Redis的其他功能,比如持久化、异步删除、集群数据同步等,是由额外的线程执行的(Redis 4.0增加功能)。
Redisson分布式限流组件RRateLimiter使用
RRateLimiter的使用Demo
1 | public class RRateLimiterDemo { |
RRateLimiter的基本原理
setRate设置速率
会向Redis中设计速率、时间间隔、和对应的模式。整个为hash结构,1
2
3redis.call('hsetnx', KEYS[1], 'rate', ARGV[1]); -- 速率 比如1s产生2个令牌 速率就是2
redis.call('hsetnx', KEYS[1], 'interval', ARGV[2]); -- 时间间隔为1s
return redis.call('hsetnx', KEYS[1], 'type', ARGV[3]); -- 模式这里忽略 分布式环境下都是集群
尝试获取一个许可
1 | -- 速率 |
总结一下,redisson用了zset来记录请求的信息,这样可以非常巧妙的通过比较score,也就是请求的时间戳,来判断当前请求距离上一个请求有没有超过一个令牌生产周期。如果超过了,则说明令牌桶中的令牌需要生产,之前用掉了多少个就生产多少个,而之前用掉了多少个令牌的信息也在zset中保存了。
LUA脚本返回后的处理
1 | private void tryAcquireAsync(long permits, RPromise<Boolean> promise, long timeoutInMillis) { |
再次总结一下,Java客户端拿到redis返回的下一个令牌生产完成还需要多少时间,也就是delay字段。如果这个delay为null,则表示成功获得令牌,如果没拿到,则过delay时间后通过异步线程再次发起拿令牌的动作。这里也可以看到,redisson的RateLimiter是非公平的,多个线程同时拿不到令牌的话并不保证先请求的会先拿到令牌。
实现LRU算法
LRU算法概述
LRU:Least Recently Read (最近最少访问),是一种常见的缓存淘汰算法,当容量不够时淘汰最近最少访问的元素。
使用示例
1 | /* 缓存容量为 2 */ |
一些特点
- 查找效率高。尽量O(1)的查找效率
- 插入、删除要求效率高,容量满的时候要淘汰最近最少访问的元素。
- 元素之间是有顺序的,因为区分最近使用和久未使用的数据。
实现LRU核心数据结构
- hash表:快速查找,但是各个节点的数据不是有顺序的。
- 链表:插入删除快,有序但是查找速度不快。
最终结合两种数据结构。哈希链表
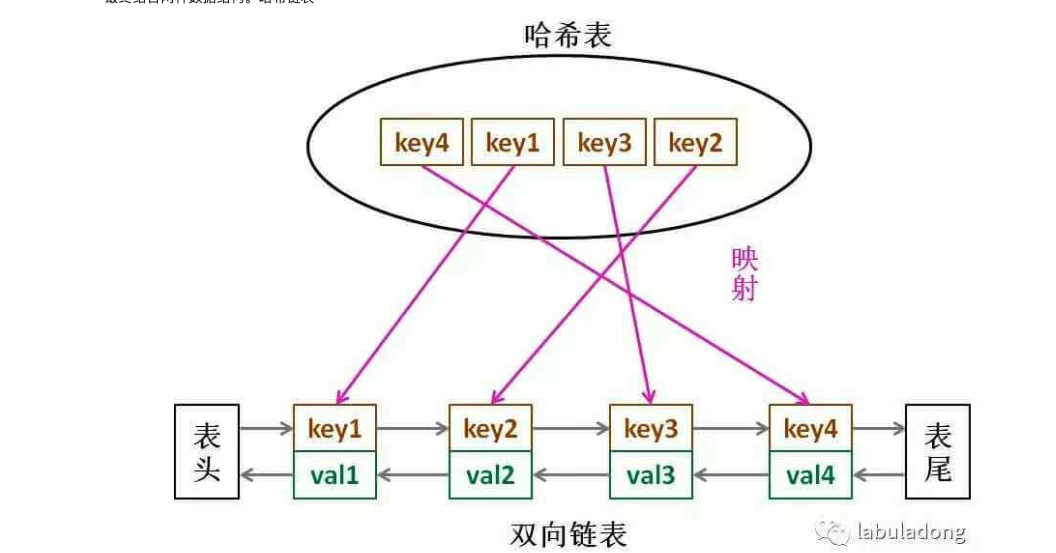
这里的两个问题:
为什么链表是双向链表?
因为在容量满足了之后需要对链表尾部的节点删除,这时候要断开上一个节点和其的链,这就需要找到上一个节点。为什么链表中也是key和value,不能直接放value吗?
因为在删除尾部节点的时候需要同时删除hash表中的元素,这时候需要根据key来删除,索引链表里也要冗余key。
java代码实现
使用HashMap和LinkedList来实现
1 | class LRUCache { |
使用HashMap和自定义的双向链表实现
- 自定义双向链表的节点和双向链表
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23/**
* 双向链表节点
*/
public class DeListNode <Key, Value>{
private Key key;
private Value value;
// 前驱节点
private DeListNode<Key, Value> prev;
// 后继节点
private DeListNode<Key, Value> next;
public DeListNode(Key key, Value value)
{
this.key = key;
this.value = value;
}
public String toString() {
return String.format(" (key:%s,value:%s) ", key, value);
}
}
1 | /** |
- 实现LRUCache
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97public class 实现LRU {
/**
* 简单双端队列
* @param <Key>
* @param <Value>
*/
public static class LRUCache <Key, Value>{
// 容量
private int cap;
// hash表
private HashMap<Key, DeListNode<Key, Value>> map;
// 双向链表缓存
private DeLinkedList<Key, Value> cache;
// 初始化函数
public LRUCache(int cap) {
this.cap = cap;
map = new HashMap<>(cap);
cache = new DeLinkedList<>();
}
/**
* 根据key获取value
* 逻辑:
* 1. 如果缓存中不存在 则返回null
* 2. 如果存在,将命中的元素移动到队头(LRU的逻辑) 返回元素
* @param key
* @return
*/
public synchronized Value get(Key key) {
if (!map.containsKey(key)) {
return null;
} else {
// 移动元素到队尾 采用先删除再插入的方式
DeListNode<Key, Value> keyValueDeListNode = map.get(key);
cache.remove(keyValueDeListNode);
cache.addLast(keyValueDeListNode);
return keyValueDeListNode.getValue();
}
}
/**
* 添加一个元素到LRU缓存中
* 逻辑:
* 1. LRUCache中是否存在key 如果存在替换对应的node 即map.put 然后维护双向链表(插入再删除)
* 2. 如果不存在 需要根基cap判断是否需要淘汰队头元素。 队列尾部添加节点 map中添加然后删除淘汰的key
*
* @param key
* @param value
*/
public synchronized void put(Key key, Value value) {
// 构造新节点
DeListNode<Key, Value> node = new DeListNode<>(key, value);
if (map.containsKey(key)){
// 存在key 则去替换map中的节点 且维护双端队列(删除再添加)
cache.remove(map.get(key));
cache.addLast(node);
map.put(key, node);
} else {
// 不存在要去判断是否触发淘汰
if (cap == cache.size()) {
// 双端队列队头淘汰(LRU逻辑)
DeListNode<Key, Value> first = cache.removeFirst();
// map中remove
map.remove(first.getKey());
}
// 直接添加到尾部即可
cache.addLast(node);
// map中添加
map.put(key, node);
}
}
public void printf() {
System.out.println("cachhe 队列" + cache.toString());
}
}
public static void main(String[] args) {
// 初始化为2的lruCache
LRUCache<Integer, Integer> lruCache = new LRUCache<>(2);
lruCache.put(1, 1);
lruCache.put(2, 2); // 新 [(2,2), (1,1)] 旧
lruCache.printf();
Integer integer = lruCache.get(1); // 新 [(1,1), (2,2)] 旧
lruCache.printf();
lruCache.put(2,3); // 新 [(2,3), (1,1)] 旧
lruCache.printf();
// 再添加 淘汰的是1
lruCache.put(4, 4); // 新 [(4,4), (2,3)] 旧
lruCache.printf();
}
}
mybatis-spring-boot-starter自动装配实现
Mybatis-spring-boot-starter的入口
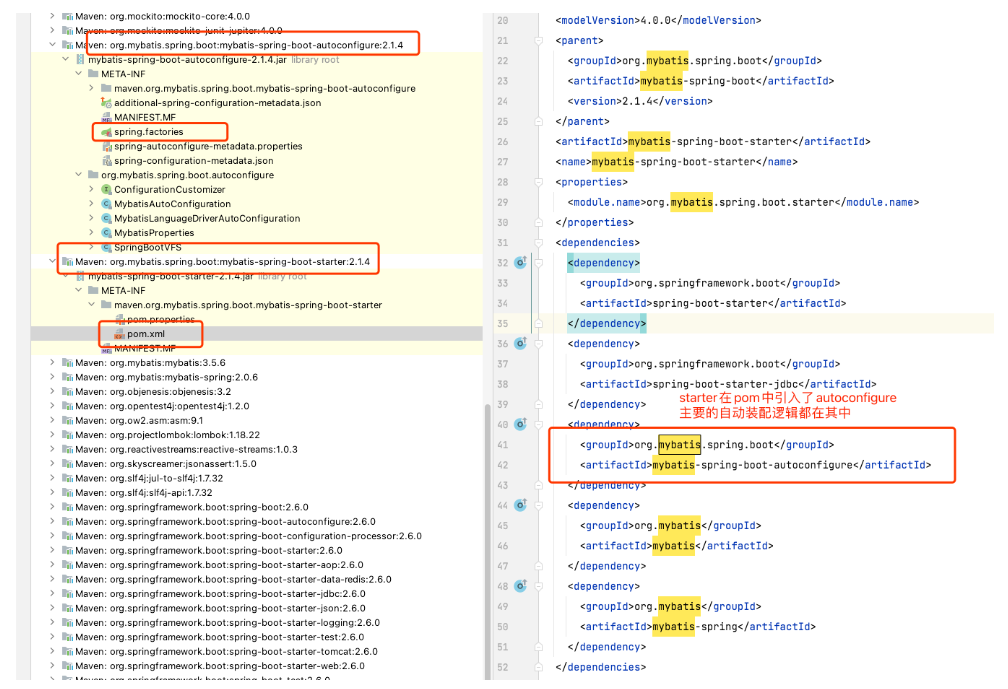
会在springboot启动的时候加载autoconfigure模块定义的自动装配类:MybatisAutoConfiguration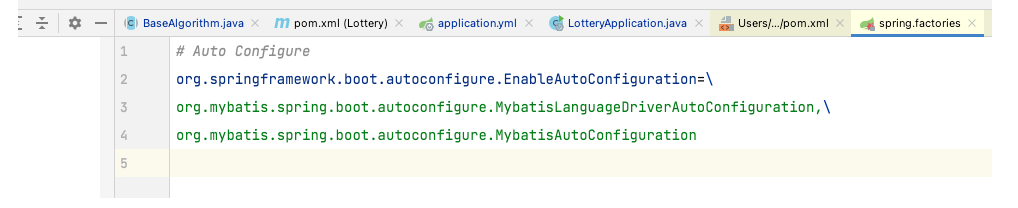
MybatisAutoConfiguration中装配Mybatis的逻辑
SqlSessionFactory的构造
1 |
|
SqlSessionFactory的实例化是通过SqlSessionFactoryBean.getObject()实现的,该类会被注入DataSource对象(负责管理数据库连接池,Session指的是一次会话,而这个会话是在DataSource提供的Connection上进行的)。
在factory.getObject()中,最核心还是调用了buildSqlSessionFactory 去创建了sqlSessionFactory实例。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31protected SqlSessionFactory buildSqlSessionFactory() throws IOException {
Configuration configuration;
XMLConfigBuilder xmlConfigBuilder = null;
if (this.configLocation != null) {
// 创建XMLConfigBuilder对象,读取指定的配置文件
xmlConfigBuilder = new XMLConfigBuilder(this.configLocation.getInputStream(),
null, this.configurationProperties);
configuration = xmlConfigBuilder.getConfiguration();
} else {
// 其他方式初始化Configuration全局配置对象
}
// 初始化MyBatis的相关配置和对象,其中包括:
// 扫描typeAliasesPackage配置指定的包,并为其中的类注册别名
// 注册plugins集合中指定的插件
// 扫描typeHandlersPackage指定的包,并注册其中的TypeHandler
// 配置缓存、配置数据源、设置Environment等一系列操作
// ...... 省略配置代码
if (this.transactionFactory == null) {
// 默认使用的事务工厂类
this.transactionFactory = new SpringManagedTransactionFactory();
}
// 根据mapperLocations配置,加载Mapper.xml映射配置文件以及对应的Mapper接口
for (Resource mapperLocation : this.mapperLocations) {
XMLMapperBuilder xmlMapperBuilder = new XMLMapperBuilder(...);
xmlMapperBuilder.parse();
}
// 最后根据前面创建的Configuration全局配置对象创建SqlSessionFactory对象
return this.sqlSessionFactoryBuilder.build(configuration);
}
SqlSessionFactory.getObject()方法里会根据我们mybatis相关配置(比如上面的mybatis.mapper-locations配置)找到并解析我们的mapper文件,解析出sql与dao方法里的映射、ResultMap与具体实体类的映射等,并放到SqlSessionFactory的Configuration中缓存下来,在后续调用过程中会通过这些信息来匹配jdbc操作。这个过程中会生成Mapper的代理类,执行sql时会走代理拦截方法执行,则不需要实现类就可以直接调用到具体的sql。
SqlSessionTemplate
如果使用手写java代码的方式去操作数据库,则使用的为sqlSessionTemplate,SqlSessionTemplate 是线程安全的,可以在多个线程之间共享使用。SqlSessionTemplate 内部持有一个 SqlSession 的代理对象(sqlSessionProxy 字段),这个代理对象是通过 JDK 动态代理方式生成的;使用的 InvocationHandler 接口是 SqlSessionInterceptor,其 invoke() 方法会拦截 SqlSession 的全部方法,并检测当前事务是否由 Spring 管理。
在MybatisAutoConfiguration自动配置中也去生成了SqlSessionTemplate这个bean对象。
1 |
|
MapperFactoryBean和MapperScannerConfigurer
在MybatisAutoConfiguration中注册了AutoConfiguredMapperScannerRegistrar,其实ImportBeanDefinitionRegistrar的实现类,Spring中可以通过 @Import 注解导入的 ImportBeanDefinitionRegistrar 实现类往 BeanDefinitionRegistry 注册 BeanDefinition。这里其实就是去注册了MapperScannerConfigurer 这个BeanDefinitionRegistryPostProcessor的实现。
BeanDefinitionRegistryPostProcessor是一个特殊的接口,继承了BeanFactoryPostProcessor接口,提供了注册bean定义的能力,这里MapperScannerConfigurer扫描所有的@Mapper注解的Maapper类,在扩展点方法中去注册bean定义都为MapperFactoryBean接口,这些Bean在实例化时会因为是FactoryBean,而调用getObject方法寻找Mapper接口的动态代理缓存。
1 | public void postProcessBeanDefinitionRegistry(BeanDefinitionRegistry registry) { |
MapperFactoryBean的getObject()方法是从Configuration配置对象中寻找对应Mapper接口的代理类缓存,没有的话会创建。 这个SpringBean在注入的时候就是对应的代理类了。内部会转发到sqlSession、SqlExecutor去执行sql。
1 |
|