Redisson实现分布式锁的基本原理
锁实例代码
1 | static int count = 0; |
lock操作加锁
关键代码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19<T> RFuture<T> tryLockInnerAsync(long leaseTime, TimeUnit unit, long threadId, RedisStrictCommand<T> command) {
internalLockLeaseTime = unit.toMillis(leaseTime);
// 运用lua脚本完成加锁逻辑
return commandExecutor.evalWriteAsync(getName(), LongCodec.INSTANCE, command,
"if (redis.call('exists', KEYS[1]) == 0) then " +
"redis.call('hset', KEYS[1], ARGV[2], 1); " +
"redis.call('pexpire', KEYS[1], ARGV[1]); " +
"return nil; " +
"end; " +
"if (redis.call('hexists', KEYS[1], ARGV[2]) == 1) then " +
"redis.call('hincrby', KEYS[1], ARGV[2], 1); " +
"redis.call('pexpire', KEYS[1], ARGV[1]); " +
"return nil; " +
"end; " +
"return redis.call('pttl', KEYS[1]);",
// 传入lua脚本的参数
Collections.<Object>singletonList(getName()), internalLockLeaseTime, getLockName(threadId));
}
逻辑是运用了redis的lua脚本去完成加锁逻辑。可以分开看:
第一段
1 | "if (redis.call('exists', KEYS[1]) == 0) then " + |
- 这里KEYS[1]就是锁的key,即redissonClient.getLock(“distribute-lock-key”)中的distribute-lock-key。
- AVG[2]是field的值,Redisson使用的是redis的hash结构。这里是 uuid:threadId。因为存在多台机器,所以会加上一个uuid。
- AVG[1]是设置key的过期时间。
这段逻辑流程是:
- 判断distribute-lock-key 在redis中是否存在,结果为0是不存在、
- 不存在调用hset key uuid:threadId 1 设置key、uuid:threadId是field、value是1。
- 设置过期时间
- 返回null代表成功。
第二段
1 | "if (redis.call('hexists', KEYS[1], ARGV[2]) == 1) then " + |
- 如果存在key、field hash值
- 此时就是重入场景,把对应的value加一即可。 命令是hincrby
- 再次设置下过期时间,这里相当于完成了一次锁续期。pexpire
- 返回null表示成功。
第三段
1 | redis.call('pttl', KEYS[1]); |
- 这里的场景是redis中存在key这把锁,但持有锁的不是当前线程,即锁被别的线程持有。这时候调用 pttl命令返回key的过期时间。
这里知道了加锁场景下,如果返回了null说明加锁成功,返回过期时间说明锁被占用。 拿到结果之后,可以根据ttl进行重试加锁。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
public void lockInterruptibly(long leaseTime, TimeUnit unit) throws InterruptedException {
long threadId = Thread.currentThread().getId();
// 内部调用了lua加锁逻辑
Long ttl = tryAcquire(leaseTime, unit, threadId);
// lock acquired
if (ttl == null) {
// 为null 加锁成功返回
return;
}
// 如果ttl不是null 订阅对应key等待锁删除时的通知
// 释放锁的时候会订阅key的客户端可以收到通知
RFuture<RedissonLockEntry> future = subscribe(threadId);
commandExecutor.syncSubscription(future);
try {
while (true) {
// 再次尝试获取
ttl = tryAcquire(leaseTime, unit, threadId);
// lock acquired
if (ttl == null) {
// 获取到跳出循环
break;
}
// waiting for message
if (ttl >= 0) {
// ttl大于0 去利用semaphore的tryAcquire去阻塞获取 内部是Semaphore(0)
getEntry(threadId).getLatch().tryAcquire(ttl, TimeUnit.MILLISECONDS);
} else {
// 小于0去调用 Semaphore的acquire()获取
getEntry(threadId).getLatch().acquire();
}
}
} finally {
unsubscribe(future, threadId);
}
// get(lockAsync(leaseTime, unit));
}
Redisson加锁流程总结: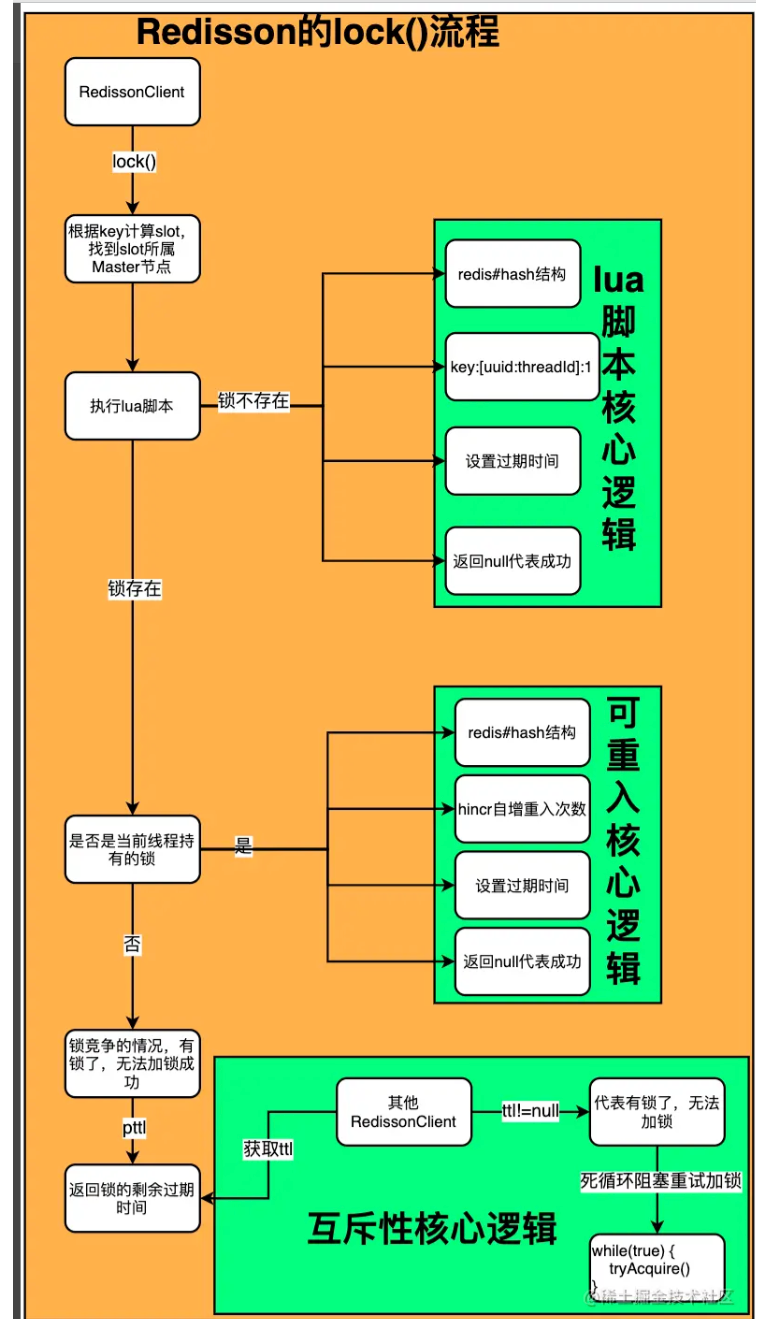
unlock解锁流程
1 | rotected RFuture<Boolean> unlockInnerAsync(long threadId) { |
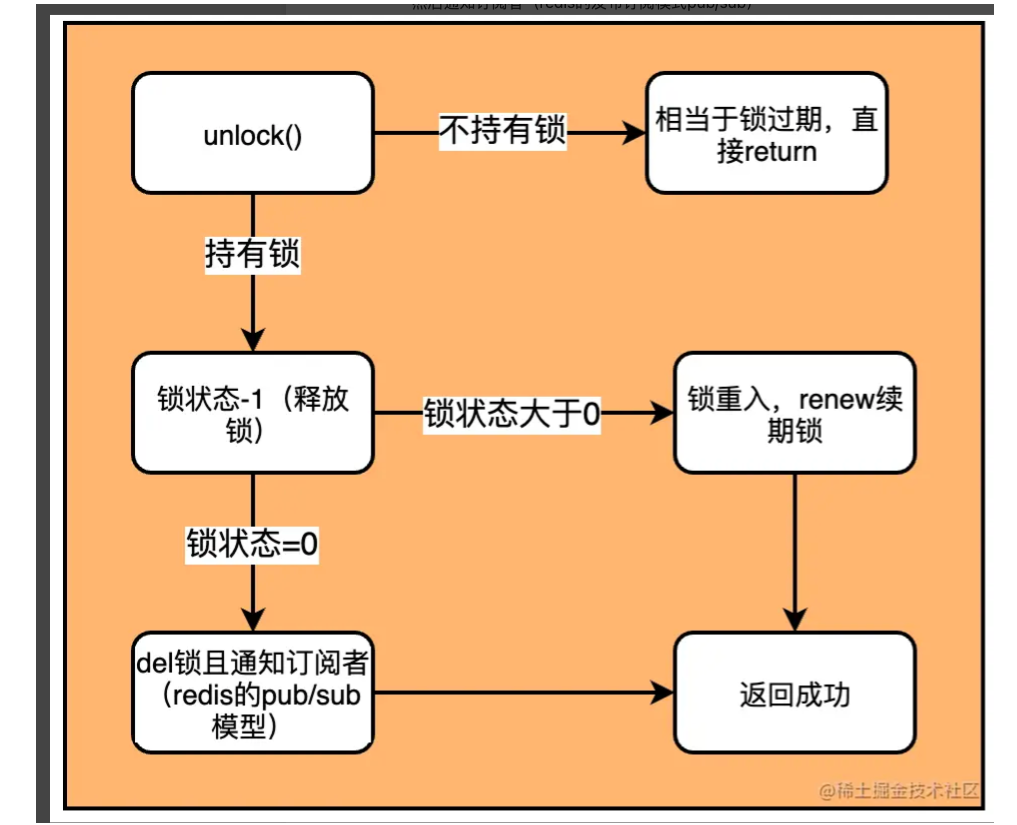
这段lua脚本的逻辑:
- 如果hexists命令调用之后发现key、field的hash结构不存在,(lock(leaseTime)没有watchDog机制续约锁),那就是锁超时过期释放了,无需释放直接返回。
- 如果当前线程持有锁(也就是key、field的hash结构存在)
- 给锁的的value-1。hincrby key uuid:tid -1命令。 返回null
- 判断减1之后的值,如果还大于0,说明是锁重入场景的解锁。这里去锁续期一下(默认30s)。返回0
- 减1之后为0,去删除key,然后发布删除key通知。(redis的发布订阅模式 pub/sub)
- 返回1代表解锁成功。