
1. SQL造成大对象JVM频繁full gc
哪些场景会频繁full gc?
- 内存泄漏(对象没有及时被回收,某些代码问题导致)
- 死循环一直创建对象
- 一直创建大对象
主要看下大对象的场景:
- 可能来源于数据库,查询的结果集太大。
- 第三方接口传输的对象
- 消息队列的消息太大
一个排查步骤
- 是否有吻合时间点的发布?机器的CPU、网络IO、带宽是否正常?如果有先回滚和隔离机器。
- 观察内存监控,是否有逐渐上升的内存占用,且触发GC之后没办法释放内存(内存泄漏)
- 如果无内存泄漏(内存在每次fullgc之后能降下来)
- jmap -histo工具查看存活对象
- jmap -dump:format=b,file=file [pid]命令dump内存快照。利用mat工具分析
- dump内存占用很小,考虑堆外内存的占用。
- dump分析占用最多的对象和相关调用栈,查看可疑代码。
- 比如:sql查出来的大对象一般伴随着网络IO变大,时间点吻合可以重点欢迎是不是sql的原因。
案例原因
- 一个in list查找,参数没有判空,导致条件没有带上,查询命中很多记录。
- sql一般会复用mybatis模板,某个sql模板如果参数没校验,可能产生大量记录的查询。
2. 内存泄漏案例
- 内存溢出:程序没有足够的内存分配对象,会发生内存溢出。
- 内存泄漏:对象没有及时释放,导致内存逐渐增加,就是内存泄漏。内存泄漏一般不会造成程序无法运行,但是会不断的累计造成内存不足,明显现象:触发了GC之后内存占用率不下降,且缓慢上升。
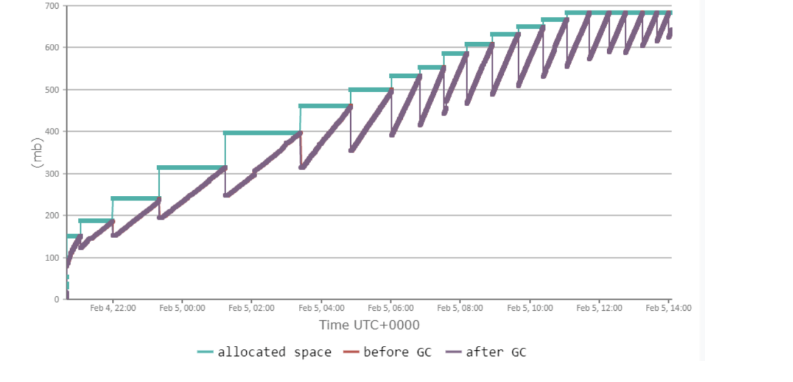
案例及原因
- 本地内存存放商品数据,如果只存放热点商品,内存占用不会太大。但是如果全量商品加载到内存中,那么内存会不够。
- 每个缓存记录加了7天的失效时间,保证淘汰掉不是热点访问的商品数据。
- 经过一次重构之后,过期时间功能失效,没有过期时间淘汰,本地缓存越来越大。
- 在一定时间之后,报警内存不足。dump内存之后发现缓存了大量的商品数据,造成内存泄漏,且因为本地缓存的引用一直没办法被GC清除。
3. 磁盘IO导致线程阻塞
- 日常的CPU高的问题可以通过标准步骤:
- top -H - p pid来查看cpu使用率高的线程id
- 线程id转换16进制
- jstack -l pid | grep ‘线程id16进制’
- 但是有时候cpu突刺可能是在一个很短的时间内发生,此时可以采用shell脚本自动执行jstack,比如5s执行一次stack,每次执行完成之后放到不同的日志文件中。只保留2000个日志文件。
1 | !/bin/bash |
下一次响应变慢的时候,找到对应时间点的jstack日志文件,里面有很多线程阻塞在logback输出日志的过程,后来精简了log + 配置日志异步输出,则问题得以解决。
4. 死锁案例
1. update顺序导致的死锁
一个关单定时任务和人工后台关单的死锁案例
背景: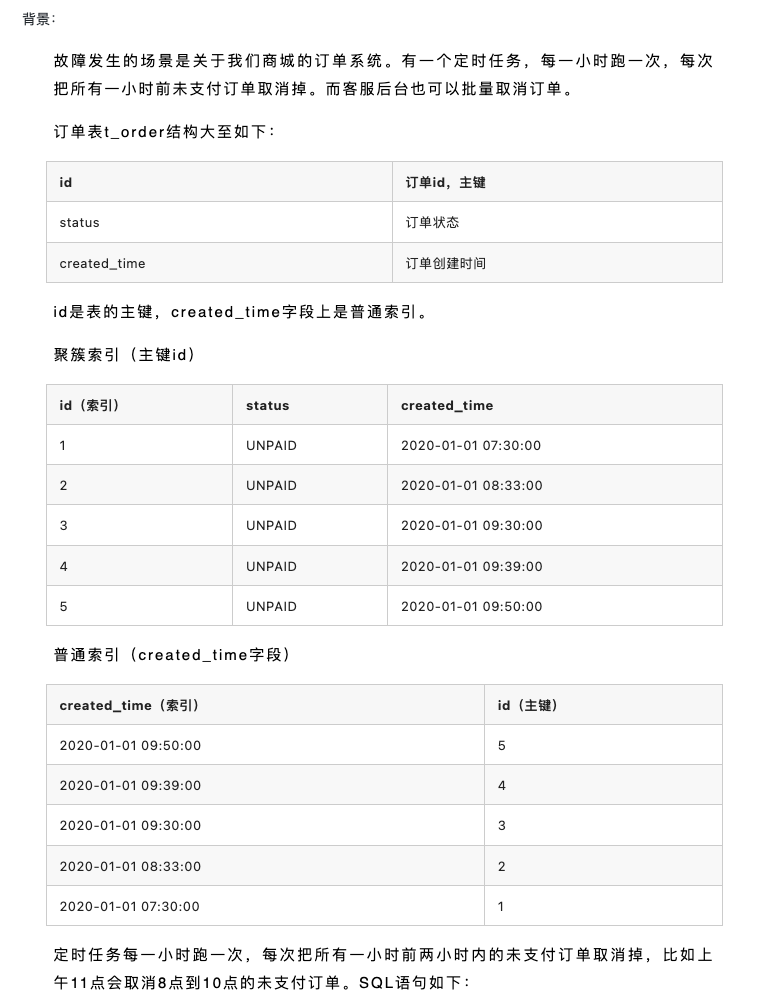
- 定时关单的sql及加锁分析。
1
update order set status = 'canceled' where created_time > '2020-01-01 08:00:00' and created_time < '2020-01-01 08:00:00' and status = 'UNPAID';
因为created_time是二级索引,会先给二级索引加锁,再给对应的聚簇索引加锁。(加锁步骤如下所示)
- 后台关单的sql及加锁分析
1 | update t_order set status = 'CANCELLED' where id in (2, 3, 5) and status = 'UNPAID' |
直接在聚簇索引的记录上加锁: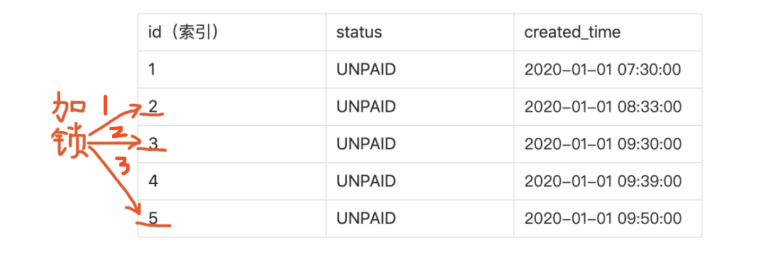
可以看到定时任务的sql对主键索引加锁顺序是5,4,3,2。而后台的sql对主键加锁顺序是2,3,5。
比如第一个sql对3加锁之后,尝试对2加锁时发现后台取消的sql事务已经对2加锁,而此时第二个sql又尝试对3加锁,两个sql互相等待对方的锁,也就发生了死锁。
解决办法:
- sql从语句上0保证加锁顺序一致。也就是都按照id排序加锁防止死锁。
- 或者让批量操作,变为单个执行,减少锁占用的粒度和时间。
- 取消订单都加一个分布式锁排队执行。
5. 后台导出数据引发的OOM
问题描述:公司的后台系统,导出功能之后偶发性的发生OOM。
排查步骤
- 因为是偶发性的,所以认为是后台系统的内存不足,单方面加大了内存。
- 但是没有解决问题,只是降低了OOM的频率。加入参数-XX:+HeapDumpOnOutOfMemoryError参数,来触发OOM时自动dump内存。
- dump内存之后进行分析,确认了大量string对象,跟其引用都是导出excel处服务。
- 结合Arthas查看,导出执行时间比较长,但是会在短时间内执行导出很多次,且用户session和参数是一致的。
- 现象总结就是短时间内多次导出相同的数据,且操作人是一个,产生大量的string对象。未能及时在年轻代清除(比如空间担保机制、比如超过了对象的阈值、比如创建对象速度过快未进行标记就晋升到老年代)。
- 最后排查是点击导出按钮没有在点击时置灰,导出交互会引导操作人多次点击,每次点击都会去读数据库的几万数据且导出excel,方法执行比较慢,对象无法回收,导致内存溢出。
- 最后解决:前端导出之后置灰,响应了之后才可以继续点击,且减少了查询订单信息的非必字段来瘦身对象,且分批次查询数据库改为了多线程。之后没有出现OOM。
6. 网站流量暴增后,网站反应出现卡顿
问题描述:在测试环境的页面速度很快,但到生产会变慢。推测访问量增大之后,对象创建变多,频繁的GC导致STW。
- 定位:使用jstat -gc pid指令观察JVM的GC次数,且观察Eden区增长的速度,来观察到触发MinorGC频率特别高,FullGC的触发频率次数和MinorGC几乎一致,甚至更多,这样导致STW业务线程,造成网页出现卡顿。
- 猜想是触发了老年代的空间担保机制,新生代在minorGC之前发现老年代可用连续空间比新生代所有对象小(或者是历次晋升的平均大小),就会触发空间担保机制,进而触发一次fullGC。
- 调大内存,老年代内存变大,且新生代的内存也变大,对象触发MinorGC的频次减少。
- 但是还是会发生卡顿,且卡顿时间比之前更长,发生卡顿频率降低。
- 继续jstat -gc pid观察,发现GC的次数不多,但是每次GC的时间变大,推测是因为内存调整变大,GC时间被拉长了。
- jinfo看到使用的是parallel垃圾回收器的组合,想到特点是多线程进行回收,但是整个回收过程会STW,造成GC期间不能正常使用。
- 这里替换为parNew + CMS垃圾回收器,CMS在垃圾回收阶段可以和用户线程并发执行,能有效的减少STW时间。
- 替换之后要设置合理的触发CMSGC的阈值,如果太大,比如在垃圾回收过程因为内存不足再次因为Concurrent mode failure触发full gc,会导致CMS退化为Serial Old单线程回收,整个回收过程都会STW。 总之使用了CMS要注意GC日志中是否有Concurrent mode failure关键字。
7. 未设置元空间大小应用启动很慢
MetaSpace会存放静态变量和很多类的信息,在启动时如果不设置元空间大小,则默认21M。
- 启动时间很长,且GC日志显示频发触发FullGC metaSpace不足
- 查看启动参数,未设置初始化的metaSpace大小。默认是21m
- 启动时会加载很多类,大量使用MetaSpace,21m很快被用完触发FullGC,然后MetaSpace动态扩容,然后再full gc再扩容的过程,使得启动变慢。
- -XX:MetaspaceSize 参数意思是触发元空间fullgc的阈值。max的参数代表元空间最大值,设置为-1时也受制于直接内存的大小。