
二叉树
什么是二叉树?
- 每个节点至多只有两棵子树,左子树和右子树。左子树和右子树。
- 逻辑上二叉树有五种基本形态,空二叉树、只有一个根节点的二叉树、只有左子树、只有右子树、完全二叉树(满二叉树)
- 遍历二叉树有前序遍历、中序遍历、后续遍历。
数据库的索引是要求排好序的数据结构。引入了二叉查找树。
二叉查找树
- 在二叉树的基础上,加上左子树的节点值总是小于根的节点值,右子树的节点值总是大于跟的节点值,也就是左子树节点值 < 根的节点值 < 右子树节点值。
设计合理的时候可以将一组数据转化为二叉查找树,时间复杂度和二分查找一致。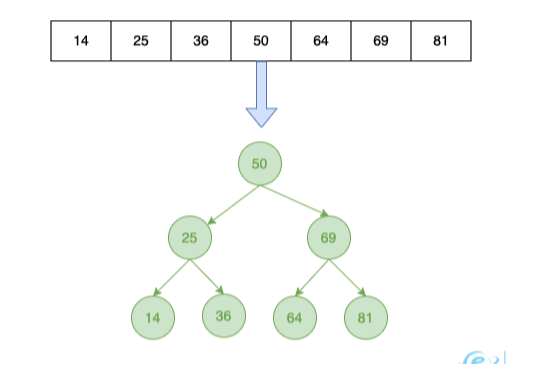
但是存在设计不合理的场景:
当二叉查找树不平衡,可能退化为一个线性的链表,查找时间复杂度高了起来。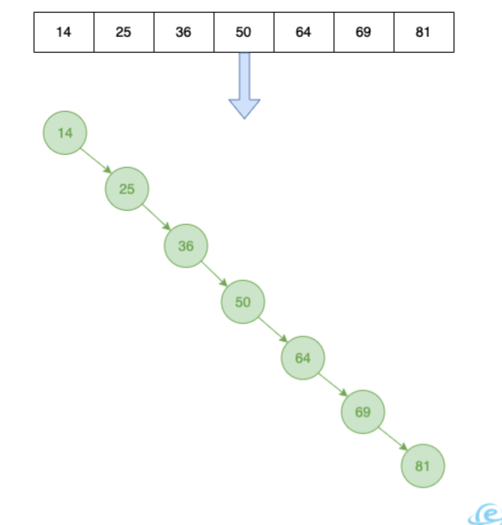
二叉搜索树可能不平衡,所以再看下平衡二叉树
平衡二叉树(AVL树)
- 符合二叉查找树的定义,然后再满足任何节点的两个子树的高度之差的绝对值不超过1。
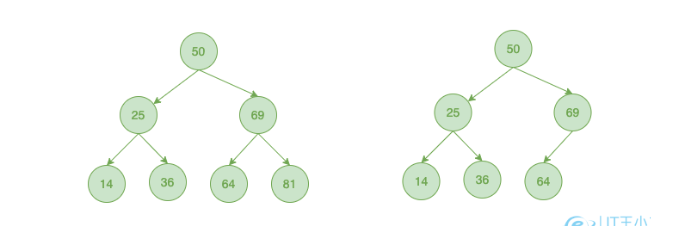
相对于二叉查找树,平衡二叉树查找效率稳定。
但也有缺点:
- 查询速度快,但是插入数据时需要维护平衡二叉树,需要1次或多次左旋或者右旋来完成更改节点之后的平衡性。
- 平衡二叉树随着数据增多,高度会增加,作为索引的数据结构可能查找一个数据可能要好多次IO。
B-tree和B+Tree
平衡二叉树存在树过高导致的IO问题,B-Tree用来解决的思想是在每一个节点上存放多个元素,来降低树的高度,以来减少磁盘IO。
B-Tree
B-Tree是一个多路搜索树,m阶的B-tree有如下特性:
- 每个节点最多有m棵子树。
- 若根节点不是叶子节点,则至少有两个孩子。
- 每个节点上存有关键字(索引值),且节点的子树按照关键字排序。
- 每个节点上的关键字都有一个指针,指针指向子树的所有节点索引值都小于当前索引值,都大于上一个索引值。
- 所有叶子节点都在同一层。
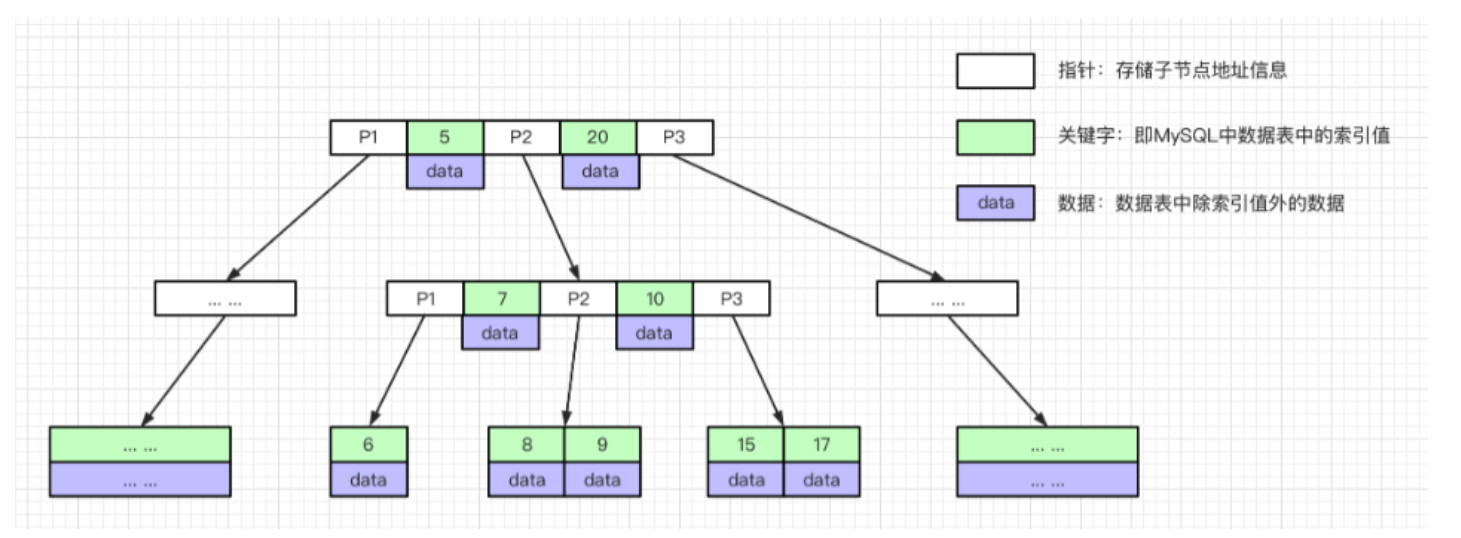
B-Tree中索引和除了索引之外的列是放在一起的,非叶子节点没有冗余索引,同时上层节点中索引关联的指针指向叶子节点,索引节点的左边孩子节点都比索引值小,右边节点都比索引值大。
这样的多路搜索已经降低了树的高度。
但Mysql还是采用了B+Tree。
B+Tree
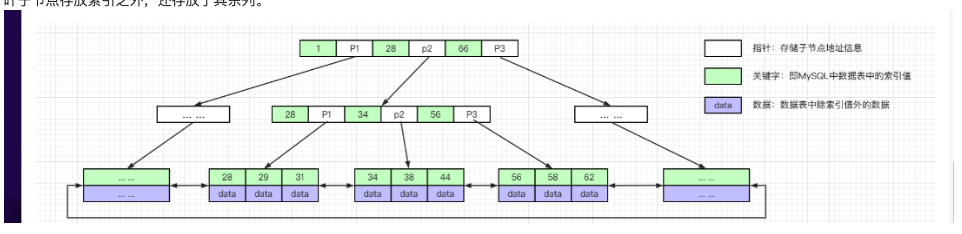
是B-Tree的变种,也是一种多路搜索树,有几点不同:
- 非叶子节点的子树指针与索引个数相同
- 非叶子节点只存储索引信息,不存放其余的列。
- 非叶子节点冗余了索引值。
- 所有叶子节点之间用双向指针连接,形成双向链表。
- 叶子节点存放索引之外,还存放了其余列。
为什么用B+Tree而不用B树?
非叶子节点不存放数据,单个节点能装下更多索引的值,降低了树的高度。

叶子节点双向指针连接,叶子节点中记录项用单向指针连接,提高了区间访问和范围查找的效率。
Hash结构
为什么不使用hash结构来存放索引呢?
- hash碰撞和扩容问题。
- hash数据结构也能快速根据索引列定位数据。hash算法的优点
- hash能支持 = in查询,但对于范围查询不好支持。