
zk实现分布式锁的核心原理
zk实现分布式锁的核心原理是利用临时顺序节点和其监听Watcher机制。临时节点有些特点:
- 生命周期是随着客户端的session周期的,session长时间心跳失败或者客户端关闭session,临时节点会自动删除。
- 临时目录节点不能创建子目录
基本过程:当客户端抢到锁之后为这个客户端分配一个临时节点,只要锁没有释放就一直持有这个临时节点,当锁释放或者服务意外宕机之后,临时节点会删除,其他客户端可以继续抢占锁(创建临时节点)
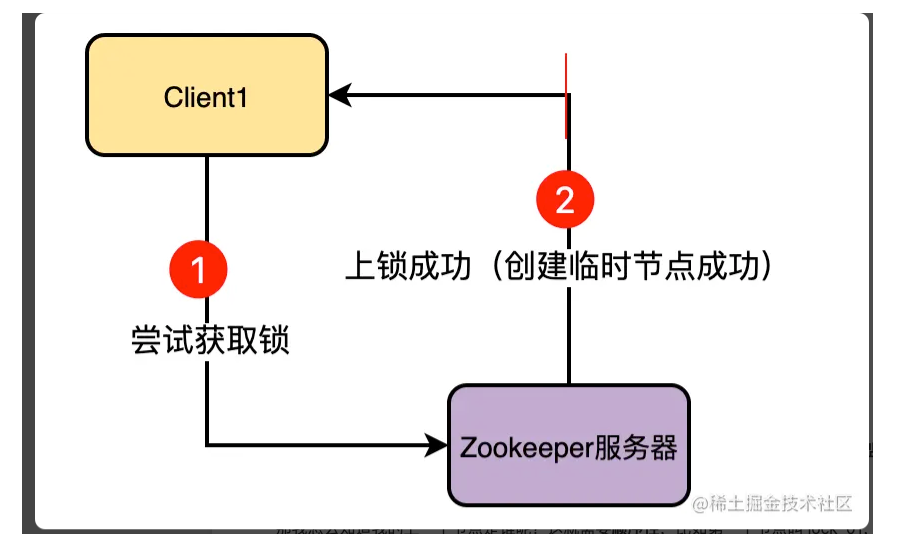
未竞争到锁的客户端会阻塞等待,并会开一个监听器监听上一个节点,如果上一个节点释放了锁,那么立即得到通知去上锁。所以加锁的客户端需要感知到上一个客户端节点是谁,也就需要有顺序编号的临时节点,即临时顺序节点。
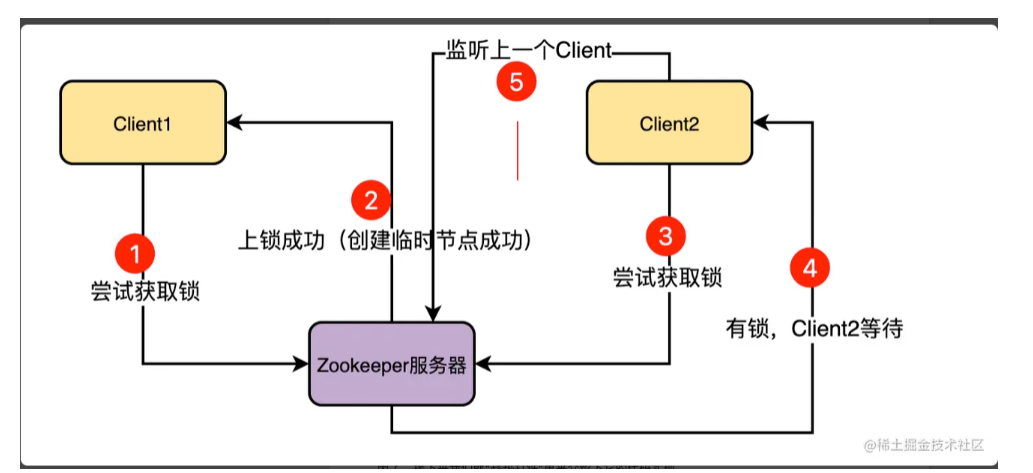
最后的释放锁就是持有锁的节点删除临时顺序节点,注册监听的其他客户端会收到通知,然后去创建自己的临时顺序节点加锁。
zk实现分布式锁的demo
1 | /** |
zk分布式重入锁实现
加锁
客户端加锁入口是:1
2
3
4
5// org.apache.curator.framework.recipes.locks.InterProcessMutex#acquire(long, java.util.concurrent.TimeUnit)
public boolean acquire(long time, TimeUnit unit) throws Exception {
// 直接调用internalLock()方法
return internalLock(time, unit);
}
内部的internalLock方法(删减代码版):1
2
3
4
5
6
7
8
9
10
11
12
13
14// org.apache.curator.framework.recipes.locks.InterProcessMutex#internalLock
private boolean internalLock(long time, TimeUnit unit) throws Exception {
// 获取当前线程
Thread currentThread = Thread.currentThread();
// 尝试加锁
String lockPath = internals.attemptLock(time, unit, getLockNodeBytes());
// 加锁成功的话就放到threadData里 是一个currentHashMap中,缓存在本地是为了锁重入
if ( lockPath != null ) {
LockData newLockData = new LockData(currentThread, lockPath);
threadData.put(currentThread, newLockData);
return true;
}
return false;
}
尝试加锁调用的internals.attemptLock方法1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27// org.apache.curator.framework.recipes.locks.LockInternals#attemptLock
// 下面是删减后的代码
String attemptLock(long time, TimeUnit unit, byte[] lockNodeBytes) throws Exception {
try {
// 创建这个锁
ourPath = driver.createsTheLock(client, path, localLockNodeBytes);
// 多个client抢锁时互斥阻塞等待
hasTheLock = internalLockLoop(startMillis, millisToWait, ourPath);
}
catch ( KeeperException.NoNodeException e ) {
//...
}
return null;
}
// createsTheLock内部逻辑
// org.apache.curator.framework.recipes.locks.StandardLockInternalsDriver#createsTheLock
// 下面代码是删减后的代码
public String createsTheLock(CuratorFramework client, String path, byte[] lockNodeBytes) throws Exception {
return client
.create()
.creatingParentContainersIfNeeded()
.withProtection()
// 就是在对应的目录下创建一个临时顺序节点
.withMode(CreateMode.EPHEMERAL_SEQUENTIAL)
.forPath(path, lockNodeBytes);
}
可以看到加锁就是创建了一个临时顺序节点,加锁成功会构建一个LockData类型的对象,内部维护了线程id、重入次数和锁节点的路径,根据线程id为key缓存在本地的一个ConcurrentHashMap中。
创建的锁临时顺序节点示例:
锁的目录会加一个UUID防止幽灵节点。即创建成功但因为网络原因客户端没拿到成功的结果再次去重试创建对应的节点,会带着UUID去查询,如果存在说明不需要去重试。
整体流程: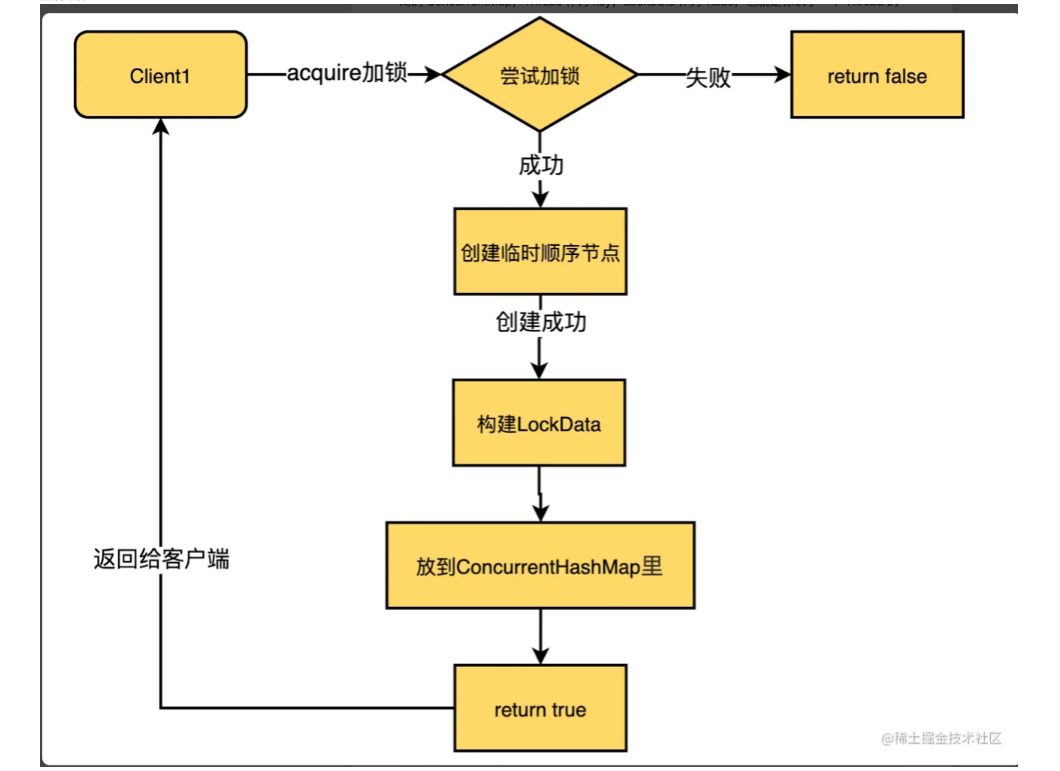
锁重入
锁的重入次数就是维护在本地的一个map中,value是一个LockData结构。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16private final ConcurrentMap<Thread, LockData> threadData = Maps.newConcurrentMap();
// LockData结构
private static class LockData
{
final Thread owningThread;
final String lockPath;
// 锁的重入次数
final AtomicInteger lockCount = new AtomicInteger(1);
private LockData(Thread owningThread, String lockPath)
{
this.owningThread = owningThread;
this.lockPath = lockPath;
}
}
可以看到在加锁流程中,以当前线程为key查询LockData对象如果存在,直接是把其lockCount++,以此来记录锁的重入次数。1
2
3
4
5
6
7
8// 根据当前线程获取锁对象,如果获取到了,那肯定是有锁的,这次是锁重入
LockData lockData = threadData.get(currentThread);
if ( lockData != null ) {
// 锁重入的关键:其实就是我们上面说的那个AtomicInteger原子类自增1
lockData.lockCount.incrementAndGet();
// 加锁直接返回成功
return true;
}
所以锁重入的流程嵌入加锁流程为: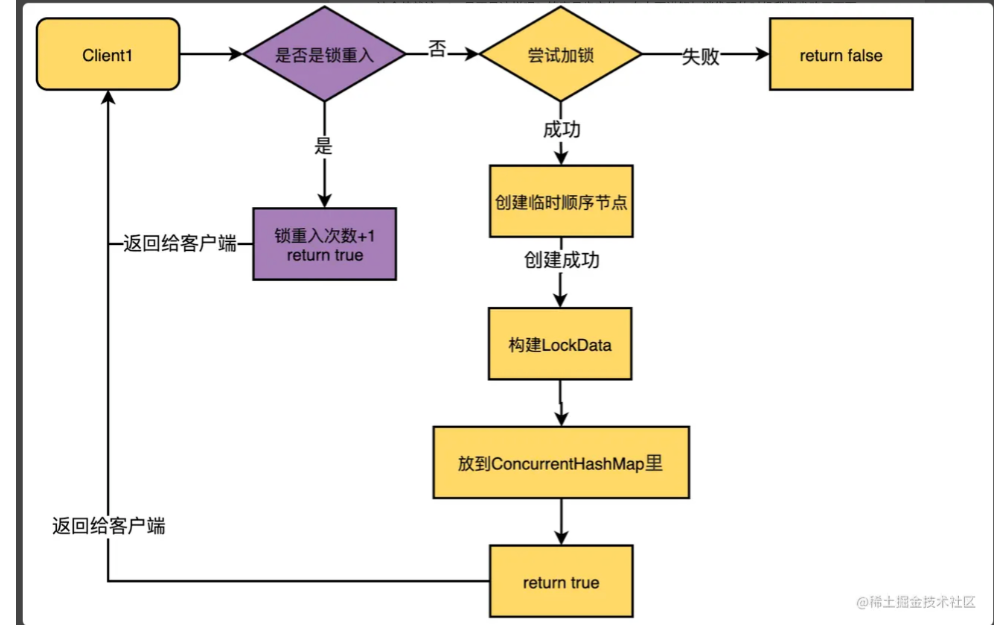
锁互斥等待
当客户端尝试获取锁时,如果发现/lock目录被占用,这里为了满足锁的互斥性,当前客户端要互斥等待Watcher回调通知。
这里互斥等待的逻辑在LockInternals#internalLockLoop方法中1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31// org.apache.curator.framework.recipes.locks.LockInternals#internalLockLoop
// 下面代码是删减后的代码
private boolean internalLockLoop(long startMillis, Long millisToWait, String ourPath) throws Exception {
boolean haveTheLock = false;
try {
while ((client.getState() == CuratorFrameworkState.STARTED) && !haveTheLock) {
// 获取path下对应临时顺序节点,并按编号从小到大排序。底层采取的java.util.Comparator#compare来排序的
List<String> children = getSortedChildren();
// 获取当前线程创建的临时顺序节点名称
String sequenceNodeName = ourPath.substring(basePath.length() + 1);
// 这个方法底层就是判断当前节点编号是不是children里的第一个,是的话就能抢锁,不是的话就计算出上一个节点序号是谁,然后下面监听这个节点。(因为按照编号排序了,所以可以得出上一个节点是谁)
PredicateResults predicateResults = driver.getsTheLock(client, children, sequenceNodeName, maxLeases);
// 如果当前客户端就是持有锁的客户端,直接返回true
if (predicateResults.getsTheLock() ) {
haveTheLock = true;
} else {
// 如果没抢到锁,则监听上一个节点
String previousSequencePath = basePath + "/" + predicateResults.getPathToWatch();
synchronized(this) {
try {
// 监听器,watcher下面分析
client.getData().usingWatcher(watcher).forPath(previousSequencePath);
// 重点在这了,wait(),等待。也就是说没抢到锁的话就开启监听器然后wait()等待。
wait();
} catch ( KeeperException.NoNodeException e ) {}
}
}
}
}
return haveTheLock;
}
逻辑为:
- 查询所有的临时顺序节点(全部抢锁的客户端),按照编号从小到大排序;
- 判断当前客户端的编号是不是第一个,是的话代表加锁成功。不是的话要计算上一个节点序号,注册Watcher监听此节点。(解锁之后删除此节点会收到Watcher的通知回调)
- 调用wait()方法实现阻塞。
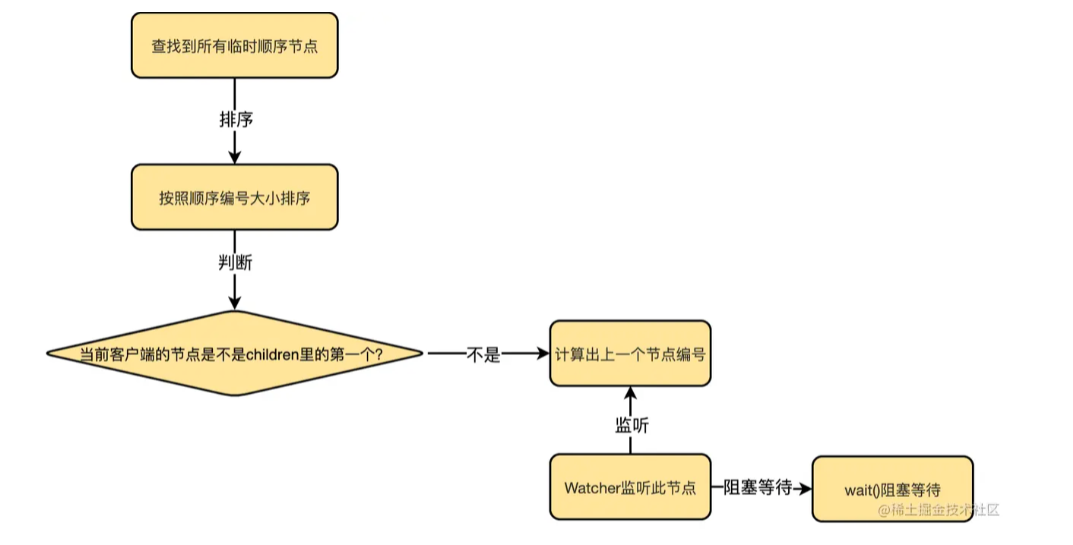
注册的Watcher通知回调逻辑:(其实就是notifyAll来实现)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18// org.apache.curator.framework.recipes.locks.LockInternals#watcher
private final Watcher watcher = new Watcher() {
public void process(WatchedEvent event) {
// 调postSafeNotify方法
client.postSafeNotify(LockInternals.this);
}
};
// org.apache.curator.framework.CuratorFramework#postSafeNotify
default CompletableFuture<Void> postSafeNotify(Object monitorHolder) {
return this.runSafe(() -> {
synchronized(monitorHolder) {
// 重点在这里,notifyAll。通知所有等待(wait)的节点。
monitorHolder.notifyAll();
}
});
}s
锁释放
锁释放调用的是release方法:
1 | // org.apache.curator.framework.recipes.locks.InterProcessMutex#release |
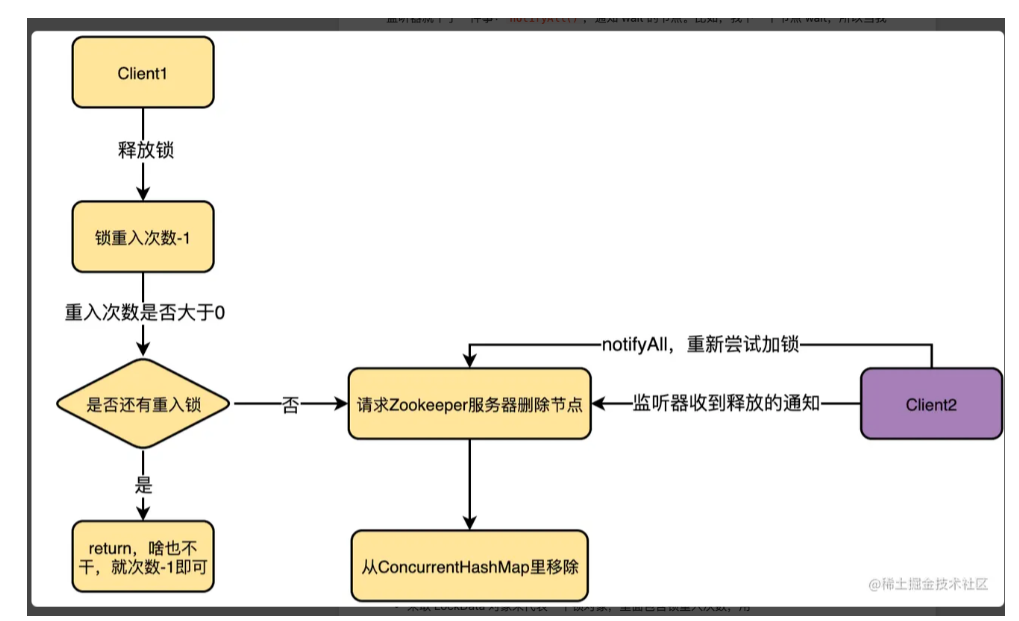
流程为:
- 根据线程对象从锁缓存中获取锁对象,对其中的锁重入 次数-1
- 如果大于0 说明是重入的解锁逻辑,直接返回。
- 如果锁重入次数为0,直接去删除对应的临时顺序节点即可。(删除之后ZK会发送之前阻塞在这个路径节点下Watcher通知,通知逻辑及时notifyall wait在同一锁对象的client线程,让其再去按照序号去竞争锁,可以看到保证了公平性)
- 缓存中remove此锁对象。
zk实现分布式锁小结

一些问题
为什么去设计排队,让被阻塞的客户端去只监听上一个序号的目录节点呢?
最基本的zk分布式锁实现:不考虑临时顺序节点,只去创建一个临时节点/lock。
未竞争到锁的客户端去监听外层的/lock节点的删除事件。
这带来两个问题:
- 非公平。很显然没有顺序,再次抢占锁的客户端是非公平的。
- 羊群效应:比如1000个client被锁节点阻塞,都注册Watcher到/lock节点,当持有锁的节点释放锁时候,会并发去抢占锁,给ZK服务端带来羊群效应。
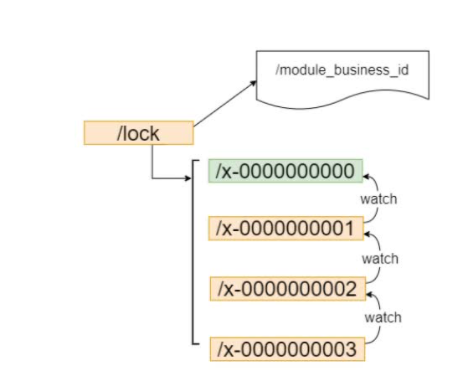
基于这两个问题,利用ZK的临时顺序节点的功能,让被阻塞的节点只监听上一个序号的节点,去注册Watcher,实现了公平排队获取,也避免了羊群效应。