
实现原理
- 利用唯一索引来实现,只要抢占锁就插入了一记录,互斥性体现在其他客户端插入重复数据会报唯一key的异常。
- 具体的步骤:
- 客户端1先来加锁,insert一条记录
- 客户端2来加锁,插入一条数据返回重复key的异常,这时候就进行重试加锁。
- 持有锁的线程执行完逻辑释放锁,即删除数据库中的记录即可。其他客户端可以进行抢锁了。
但是也有一些问题:
- 分布式锁的表怎么设计,一个业务一张表?
- 抢占锁要怎么去做重试
- 释放锁如果安全的释放锁。
表设计和唯一key
- 为了每个业务不去都加这个锁的表,则设计一个能兼容多个业务的锁表,抽象锁的业务id为resource_id;且标识是哪个业务,有project_name、method_name,同时在数据库层可以将唯一索引抽象为lock_id,生成规则可能是project_name下划线method_name下划线resource_id;另外为了实现可重入,要记录一个字段entry_count作为重入次数,同时保留加锁的host_ip和thread_id。
比如表DDL:1
2
3
4
5
6
7
8
9
10DROP TABLE IF EXISTS `common_lock`;
CREATE TABLE `common_lock` (
`id` int NOT NULL,
`lock_key` varchar(100) NOT NULL,
`thread_id` int NOT NULL,
`entry_count` int NOT NULL,
`host_ip` varchar(30) NOT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `lock_key` (`lock_key`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
释放锁
上面提到释放锁就是delete这条记录,但是因为有了重入次数,所以释放锁可能是重入次数-1的过程。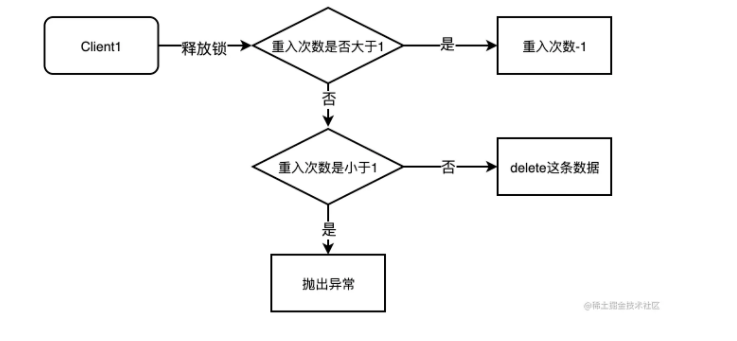
防止死锁
如果加锁之后服务端发生宕机未释放锁,则可能造成死锁。当然这里可以记录下超时时间,然后定时任务去扫描超时未释放的数据,然后将其删除。
但这样还是出现一个问题,就是定时任务不能判断出是否业务逻辑超时,如果业务超时时间内未完成,定时任务删除了锁记录,也可能出现问题,mysql这里不太好解决这个问题。(redis解决可以有watchDog机制和续期的线程)。
MySQL实现分布式锁的优缺点:
优点
- 实现方式简单,加锁是insert记录,重入是重入次数+1,删除锁是update重入次数或者删除记录。
- 不依赖其他中间件,数据库的高可用保障性强。
缺点
- 性能很低,支持并发不高。最简单的不考虑重入场景,也需要和数据库进行两次io操作。
- 线程不安全,为了防止死锁引入定时任务扫描,没办法解决续约的场景。
- 还是依赖了MySQL,没有百分之百高可用的中间件。
- 没办法支持读写锁或者公平锁。