
集群架构
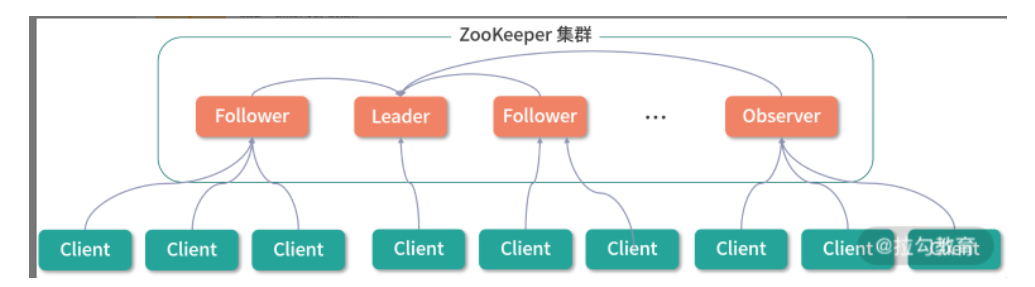
- client节点:从业务角度来看,这是分布式应用中的一个节点,通过长连接和zkServer端建立连接,定时发送心跳。从集群角度来看,是集群的客户端,可以连接集群中的一个节点,进行node添加、删除、更新数据、注册Watcher机制等。
- leader节点:zk的主节点,负责zk集群的写操作,保证集群内部事务处理的顺序性。同时也负责Follower和Observer节点的数据同步。
- follower节点:ZK集群的从节点,可以接受Client的读请求返回数据,并不处理写请求,而是转发到Leader节点去写数据。follower节点也要参与集群内leader节点的选举。
- observer节点:特殊节点,只处理读请求,但不参与集群选举。作用是提高zk的吞吐量,因为一直增加follower节点会带来副作用,leader写数据要半数follower节点都响应ack之后才能commit,follower节点太多会影响写吞吐量。因为Observer节点不参加选举,且能响应读请求,所以可以增加读吞吐量。
ZK的消息广播流程
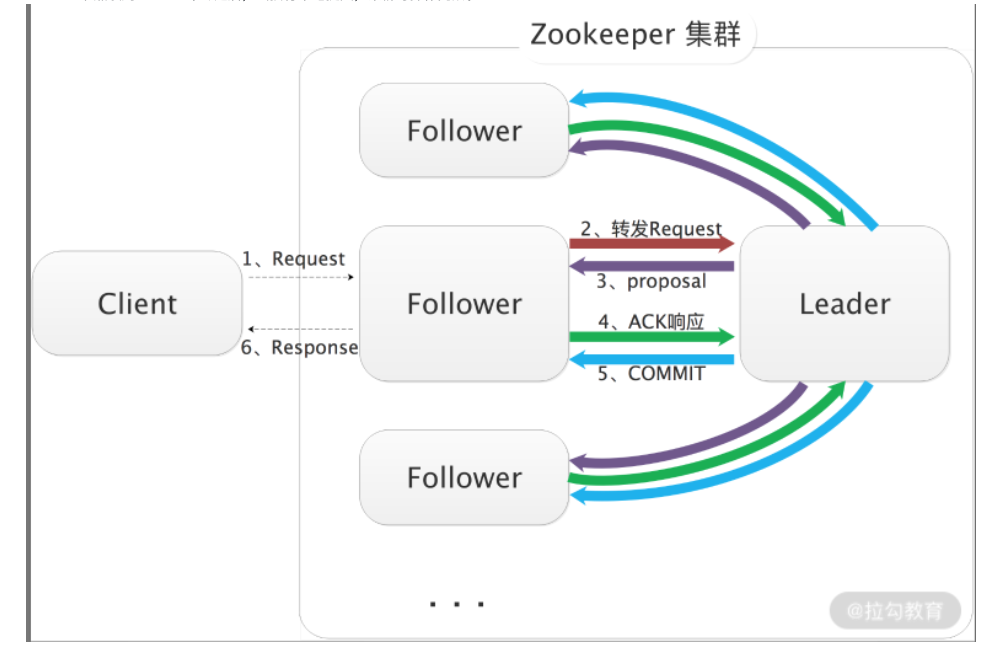
对于写请求,如果Client连接的是Follower节点或者Observer节点,那么会转发给Leader节点进行数据写入和消息广播的流程。Leader节点处理写请求的核心流程:
- Leader节点收到写请求之后,为写请求赋予一个全局唯一的zxid(64位自增id),通过zxid的大小可以实现写操作的顺序一致性。
- Leader会通过先进先出队列(每个Follower节点创建一个队列,保证发送的顺序),将带有zxid消息的作为一个proposal(提案)分发给所有follower节点。
- 当Follower节点收到proposal提案消息之后,将proposal消息写到本地事务日志,写成功后返回给Leader节点 ACK消息。
- 当Leader节点收到过半的Follower节点的ACK消息之后,向所有的follower节点去发送Commit消息,并执行本地提交。
- Follower节点收到Commit命令之后,去执行本地提交,集群写操作完成。
Leader节点的重新选举(崩溃恢复)
写数据的流程中,如果Leader宕机,整个ZK集群可能出现两个状态:
- Leader节点收到半数Follower节点的ack消息,向各个Follower节点广播Commit命令,在各个Follower节点收到Commit命令之前宕机,剩下的服务器没办法执行本地写commit操作,也就是这次写操作数据还没有commit。
- Leader节点在生成proposal之后宕机了,其他Follower没有收到proposal或者未超过半数收到proposal消息,这次写入数据是失败的。
重新选举Leader,ZK集群有两个原则:
- 对于原Leader提交的proposal(到了执行commit阶段),新的Leader能广播并提交,这样可以选择拥有最大zxid的节点作为新的Leader。
- 对于原Leader未广播或者少数节点被广播的proposal消息,新的Leader能通知原Leader和已经同步的Follower删除此proposal消息,保证集群数据一致性。
zk的集群选举采用了ZAB协议,一个示例来解释选举新Leader的过程:
启动时的leader选举
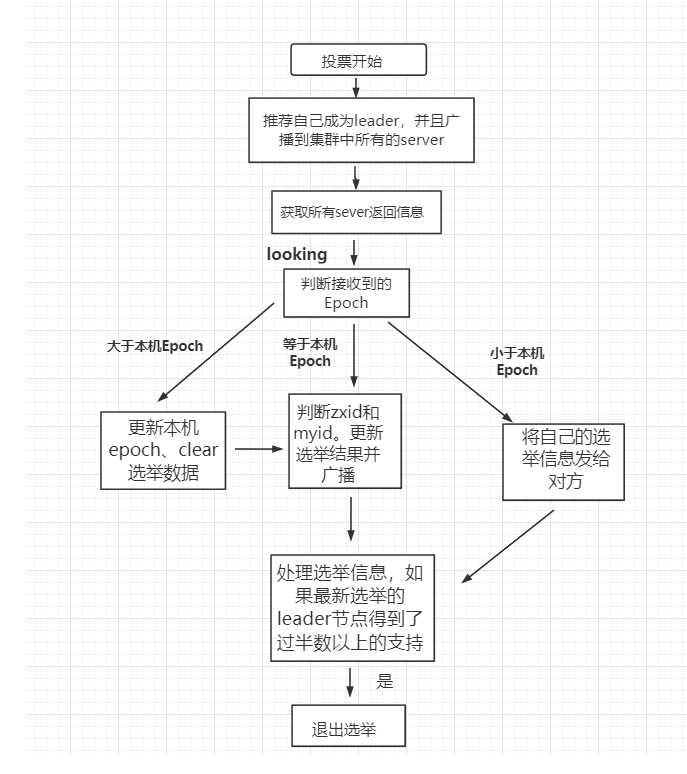
每个节点刚启动时处于Looking状态,然后进行选举流程。
- 每个server发出一个投票,初始状态都对自己投票,投票信息包括epoch、zxid、myid(zk进程号),比如server1代表的票是(myid,zxid)是(1,0)、server2是(2,0),然后发送给集群中参与选举的其他机器。
- 接收各个服务器的投票,集群中每个服务器收到投票之后,去比较和自己的投票信息:
- 优先比较epoch,是同一纪元的选票才有效。
- 再去比较zxid,在启动时都为0。集群选举的时候优先比较
- 如果zxid相同,最后比较myid。
- 比较完成之后,按照比较规则修改自己的投票,并且广播投票信息给其他服务器。
- 超过半数节点统计出相同的票,那么对应节点就是新的leader节点
- 各个服务器响应leader选举成功消息,改变自己服务器状态为follower节点。
ZAB协议
zab协议是在2pc的基础上zk保证数据一致性的协议。(Zookeeper Atomic Broadcast),包含两个最基本的模式:
- 消息广播(保证写入数据的一致性)
- 崩溃恢复(Leader挂了之后的集群恢复)
Zk就在这两个模式之间进行切换。当Leader可用时,就进行消息广播模式;当Leader不可用时进入崩溃恢复模式。