RedisKV设计原理
Redis底层数据结构
Redis底层有SDS(简单动态字符串)、链表(list)、字典(ht-hashtable)、跳跃表(SkipList)、整数集合(intset)、压缩链表(ziplist)、quicklist等数据结构。Redis使用这些底层数据结构实现key、value的存储。
Redis数据库的key和value是怎么存储的
整个Redis中所有的key和value组成了一个全局字典,存储在RedisDb数据结构中。

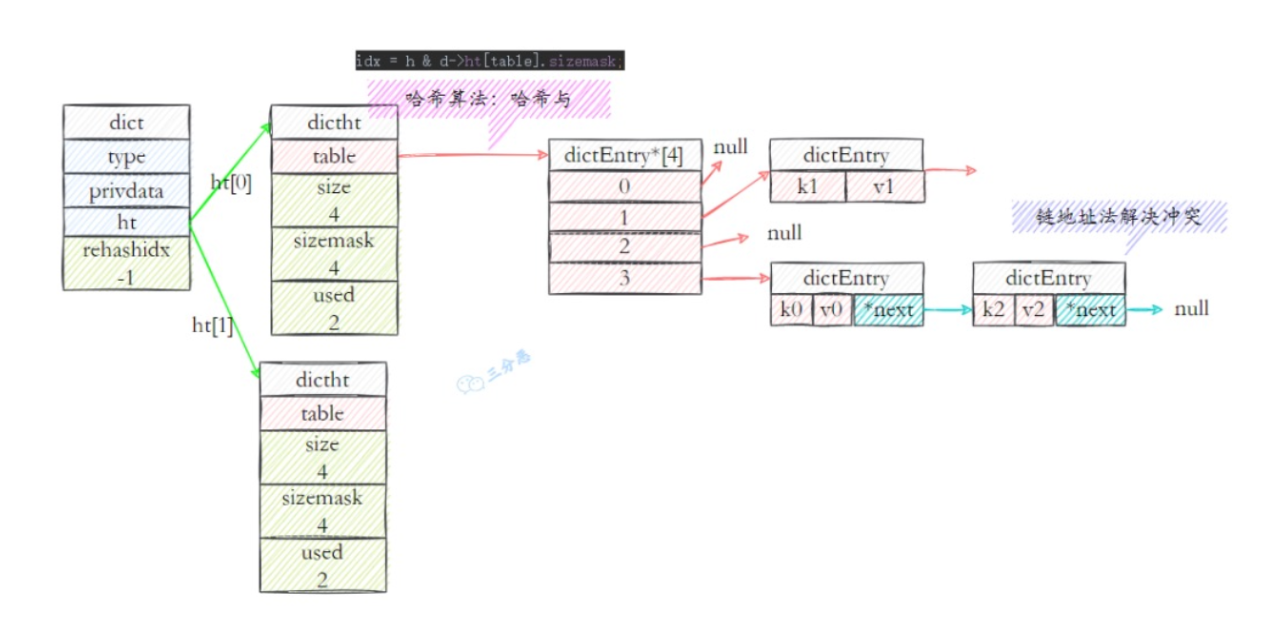
- RedisDb:结构包含一个字典dict,还包含一些过期键值对等dict字典值。
- dict:dict是字典结构,保存键值的抽象数据结构,包含两个hash表,供平时和rehash时候使用。hash表使用链地址法来解决键冲突,对hash表进行扩容或者缩容的时候,为了服务的可用性,rehash的过程不是一次性完成的,而是渐进式的。
- dictht:即字典的dict的hashtable结构,包含多个dictEntry节点的数组。
- dicEntry:真正包装key、value的抽象存储结构,包含key(key都是string类型的)和value结构。value即可以通过RedisObject包装为不同的基础数据类型。
Redis中的字典是怎么扩容的。(什么是redis的渐进式rehash)
存放dictEntry的数组在容量不足时,肯定需要扩容,上看可以看到dict中持有两个dictht 哈希表,即ht[0]和ht[1]。在扩容的时候,把ht[0]里的值rehash到ht[1],这是一个渐进式hash的过程。
- 渐进式hash:是rehash过程并不是一次性、集中式的完成的,而是分多次、渐进式的完成的。
全部rehash完成之后,h[1]就取代h[0]存储字典中的元素。
Redis中的value存储结构
value支持很多数据类型。比如String、list、hash、set、sorted set等。在redis中value(dictEntry中的val指针)是使用RedisObject表示的。
1 | typedef struct redisObejct{ |
Redis底层数据结构
常用的value基础数据类型和底层数据结构的映射关系: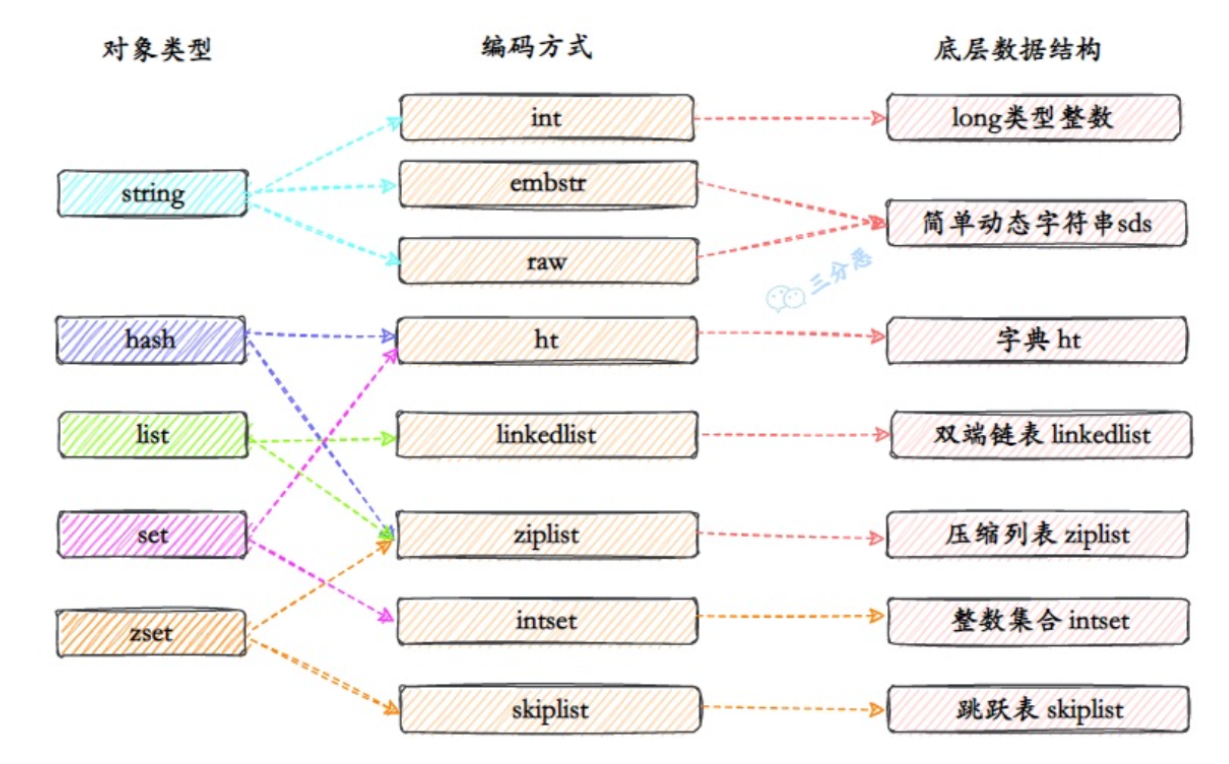
Redis中的字符串
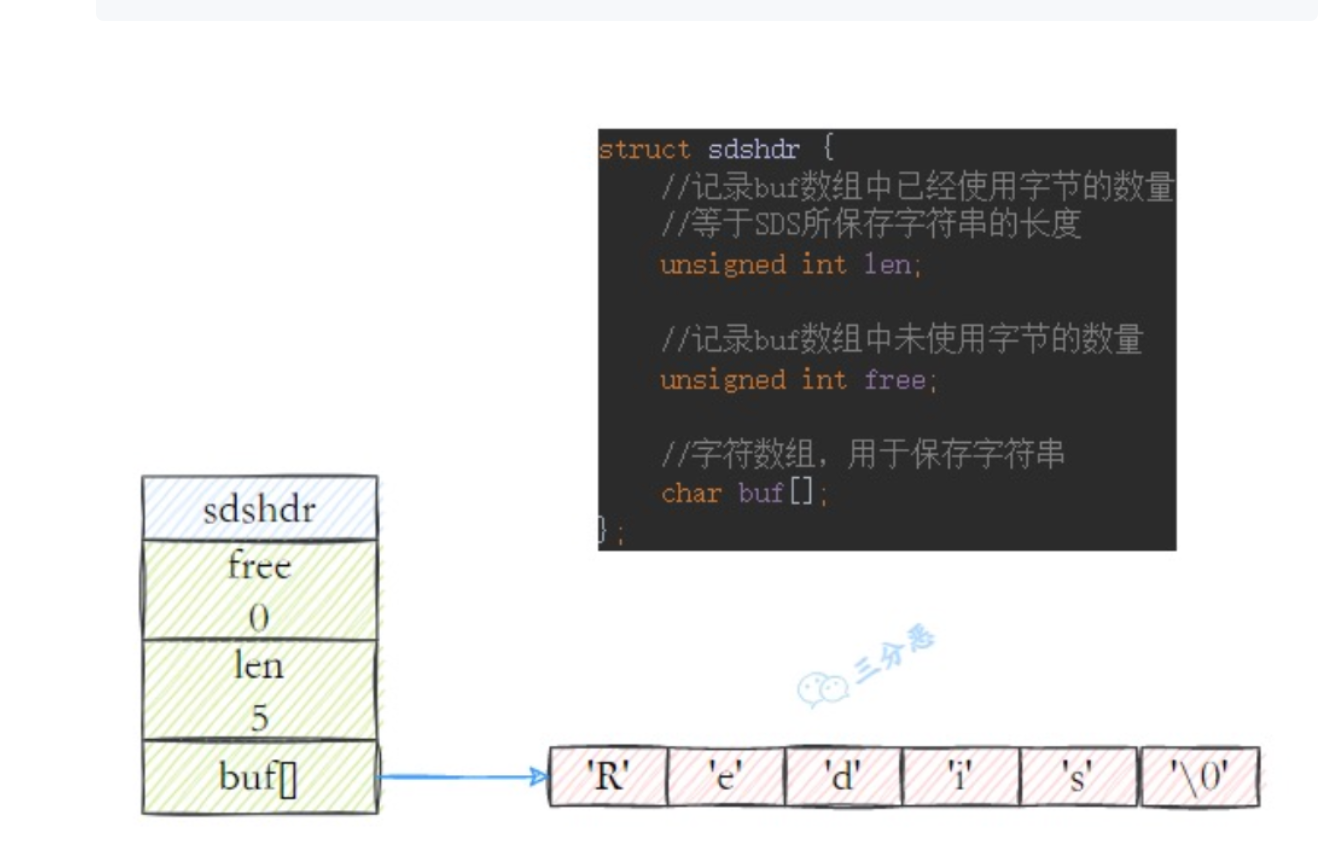
redis中所有的key都是用字符串存储的,而且redis没有直接使用c语言中的字符串。而是使用自己实现的简单动态字符串(sds)。
1 | struct sdshdr { |
Redis为什么不使用c语言字符串进行存储
C语言中的字符串使用了长度为N+1的字符数组来存储表示长度为N的字符串,并且字符数组最后一个元素总是\0。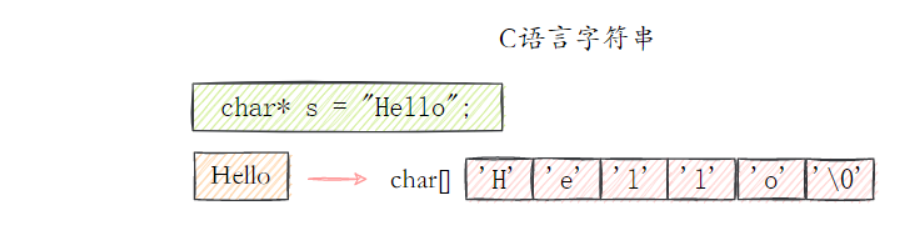
存在的问题:
- 获取字符串的效率复杂度高:C不保存字符串数组的长度,要获取长度要遍历数组。
- 不能杜绝 缓冲区溢出/内存泄漏的问题:C语言一个问题可能造成缓冲区溢出的问题,从而导致内存泄漏。
- C只能保存文本数据:C中的字符串不是二进制安全的,redis某些场景也要存储音视频文件,如果遇到字符 ‘\0’会截断不安全。
Redis的sds怎么解决的
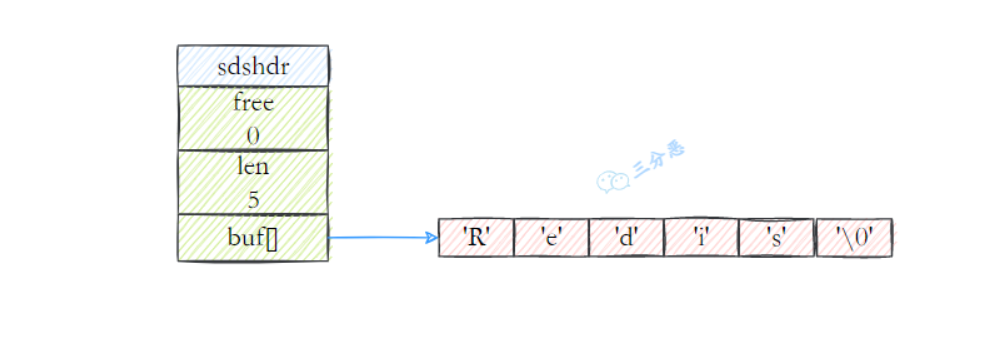
- 在sds中增加了数组长度len,获取长度直接获取。时间复杂度O(1)。
- 自动扩展空间:SDS对字符串修改时,根据free能检查是否满足修改所需的空间,不够的话SDS会自动扩容,避免了C语言存在的字符串溢出的问题。
- 预分配内存有效降低内存分配次数,避免频繁扩容分配内存。SDS在扩容时是成倍的扩容的,这种预分配的机制避免了字符数组频繁扩容。
- 二进制安全:C语言字符串只能保存ASCII码,对于图片、视频等是二进制不安全的。SDS除了兼容了C语言的字符串,同时对写入、读取不做过滤、分割,是二进制安全的。
Redis中的双端链表(linkedlist)
redis的数组结构的value可以通过list结构来实现。(list底层数据结构还有ziplist压缩列表实现)
Redis中的list是一个双向无环链表结构,每个链表的节点用listNode结构,每个节点有前驱节点和后置节点方便遍历。
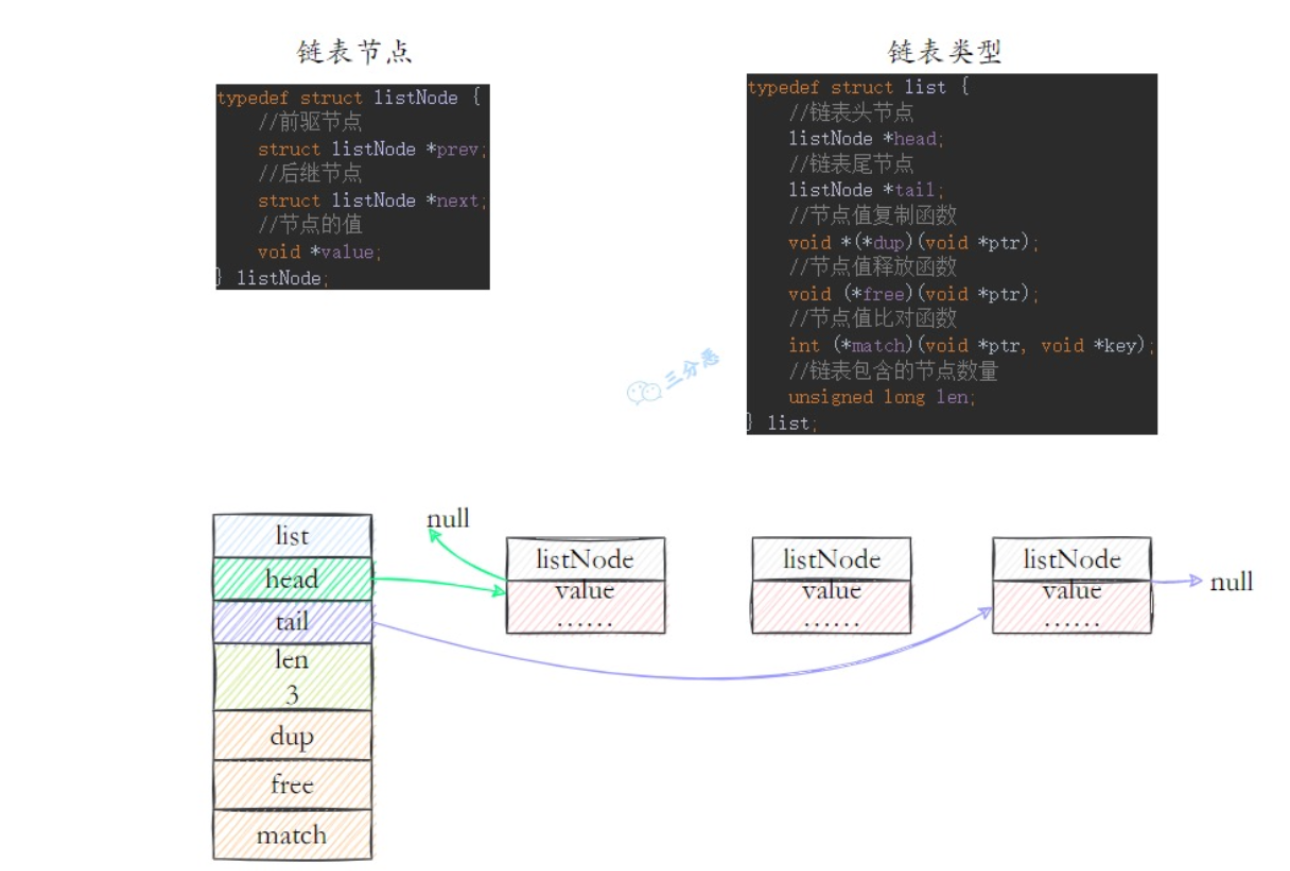
- listNode:list中的一个节点,包含value(值)和前驱和后置节点。
- list:list结构,包含head和tail节点,是维护节点。持有了链表头尾的指针。
Redis中的ziplist
压缩列表是为了节约内存而开发的线性顺序数据结构,可以包含多个节点,每个节点可以保留一个字节数组或者整数值。
ziplist是一个为Redis专门提供的底层数据结构之一,本身可以有序也可以无序。当作为list和hash的底层实现时,节点之间没有顺序;当作为zset的底层实现时,节点之间会按照大小顺序排列。

Redis中的quicklist
Redis早期版本list列表是通过压缩列表和普通的linkedlist来实现的,当元素少的时候用linkedlist,元素多的时候用ziplist。
而链表的附加空间比较高(prev和next指针),且链表内存中不连续,会有内存碎片化的问题。
在Redis 3.2版本之后对list结构的数据进行了改造,使用quicklist代替了ziplist和linkedlist。结合了空间和时间效率的考量。
quicklist其实也是由ziplist和linkedlist组成: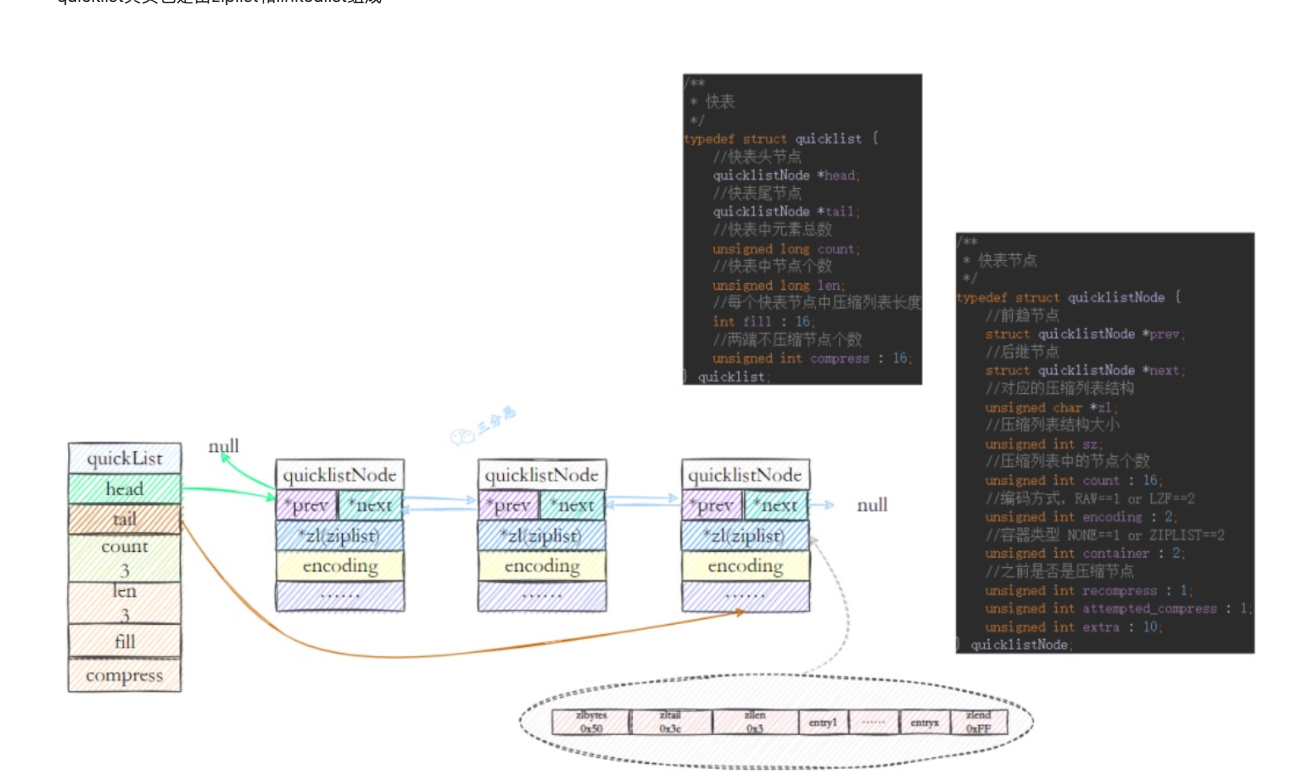
- quickList:本质还是一个linkedlist的维护节点,有头尾节点,连接的节点都是quicklistNode
- quickListNode:有前驱和后继节点,但真正的内容不再是list中的一个值,而是一个ziplist。
这样两种数据结构的优点都能使用到。
Redis中的字典table结构
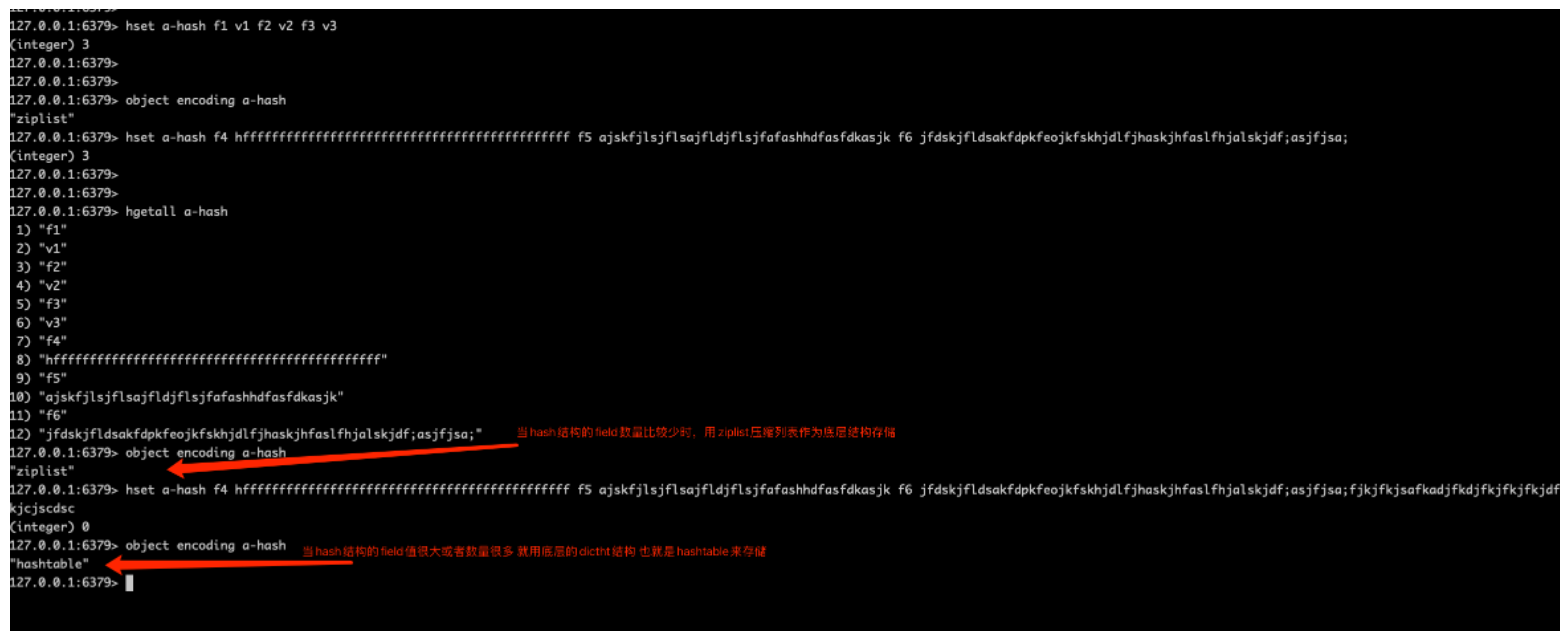
Redis中的hashtable就是dictht结构,和整体Redis kv数据存储是一个数据结构。当value是hash结构即代表value也是类型是dictht,内部每个dictEntry结构存储。
当hash结构的value元素比较少时,底层用ziplist存储(ziplist是有序的 dictht是无序的),元素数量比较大的时候会由字典来实现。由元素个数和元素大小的阈值来控制是否转变为字典结构。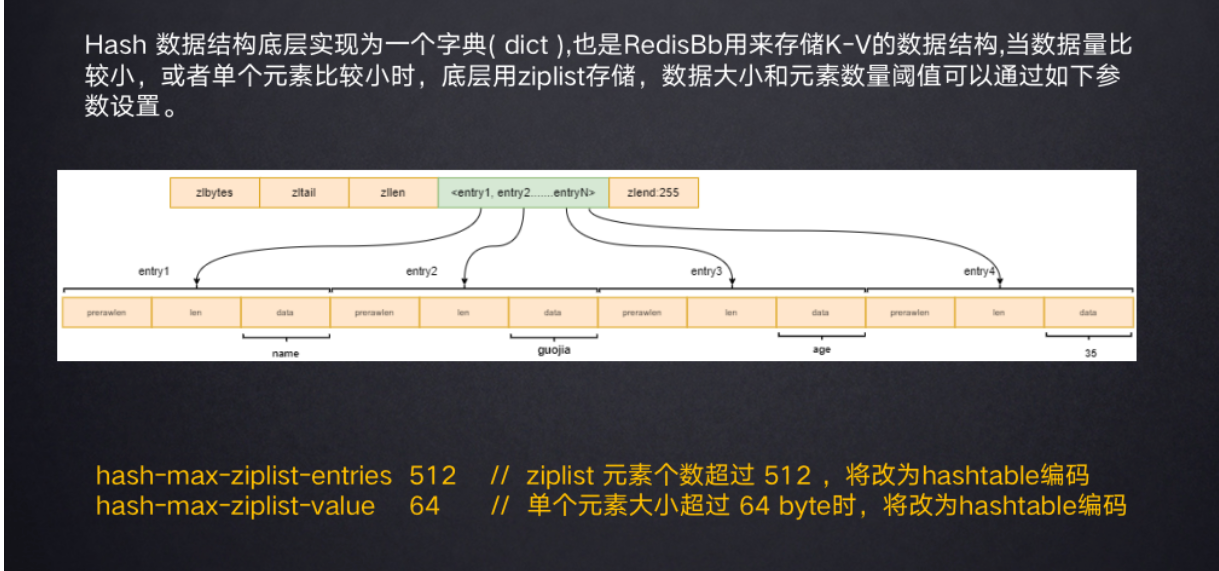
Redis中的skiplist跳表
Redis中实现有序集合,底层选用的是hashtable和跳表作为数据结构。
和hash基础数据结构一样,当数据量小的时候,zset也可以用ziplist数据结构实现,当数据量大之后采用hashtabel+skiplist。
当zset满足:
- 元素个数小于128
- 所有成员的长度都小于64字节
这两个条件时候,会采用ziplist作为底层存储结构。
当不满足任一条件时,会采用dict(hashtable) + skiplist来实现:1
2
3
4
5
6
7/* zset结构体 */
typedef struct zset {
// 字典,维护元素值和分值的映射关系
dict *dict;
// 按分值对元素值排序,支持O(logN)数量级的查找操作
zskiplist *zsl;
} zset;
- hashtable:支持zrank、zscore等直接根据key查找的命令。但hash结构无序,不能很好支持快速排序。
- skiplist:支持zrange、zrevrange等范围查找。跳表可以简单理解为简单的多层级排序链表,搜索的时间复杂度是O(LogN)。
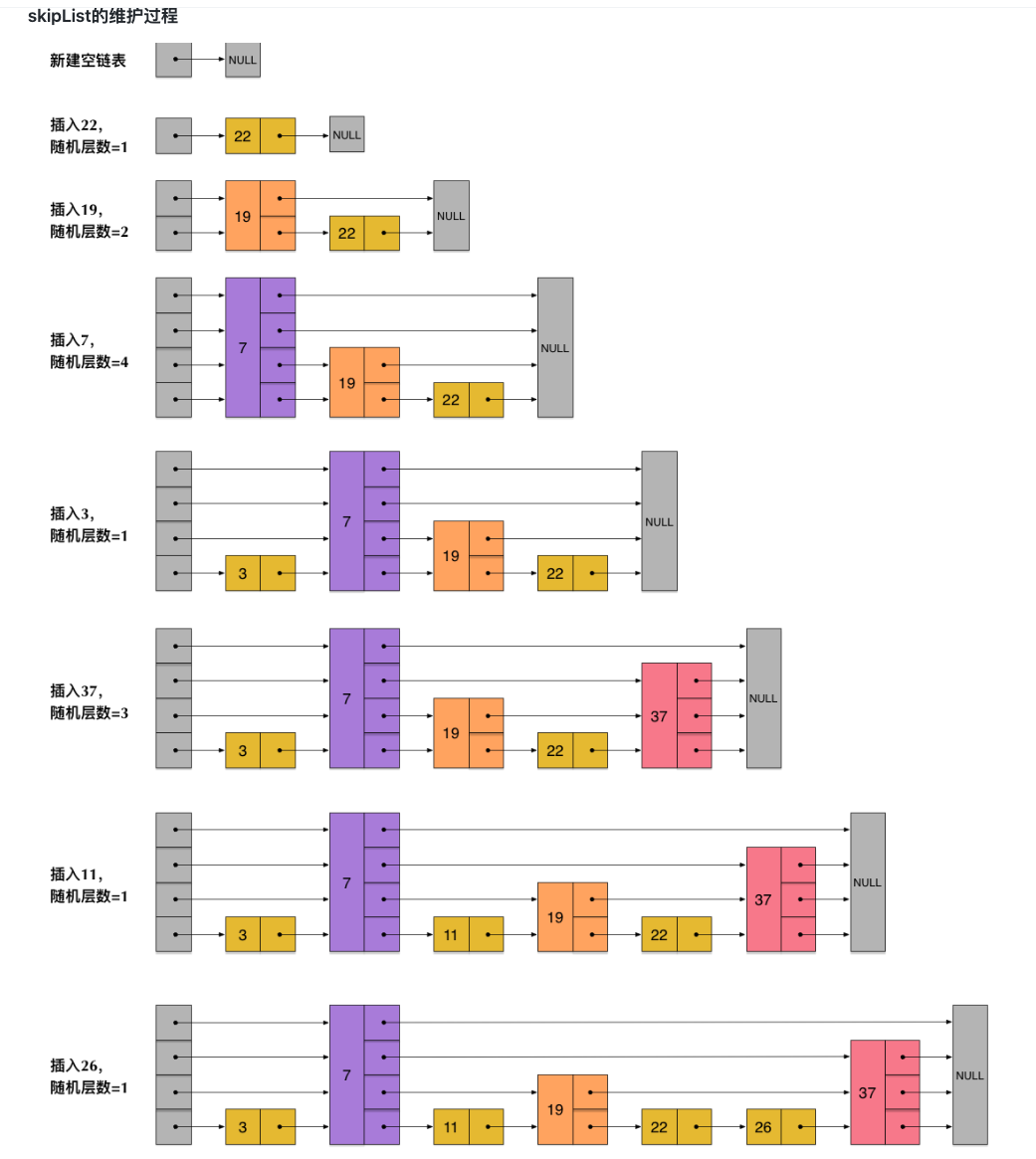
skipList在Redis中的应用:在链表增加、删除节点O(1)的时间复杂度基础上,能加入多层级的索引节点,来实现近似二分查找的时间复杂度O(LogN)数据结构。
为什么选用skiplist,而不去选择其他结构
- 有序和无序:skipList和各种平衡树(AVL、红黑树)都是有序排列的,而hash不是有序的。在hash表上只能做单key的查找,不适合范围查询。
- 范围查找:在进行范围查找的时候,树结构比跳表的操作更复杂。虽然平衡树中序遍历能找到指定范围的小指,但需要再次中序遍历才能查找到范围的大值。而跳表只需要按照上层索引节点跳到第一层(原始链表)再次遍历即可。
- 插入和删除:平衡树可能涉及到树的转换,子树的调整,实现复杂。而skiplist多层级都是链表,只需要维护对应的指针即可。
skipList的维护过程
跳表的时间复杂度和优缺点
跳表是空间换时间的一种链表基础上优化的数据结构。
链表查找的时间复杂度是O(N),借鉴数据库索引的思想,提取出关键节点(索引),先在关键节点上查找,然后下层链表继续查找。
跳表的时间复杂度是O(logN)。空间复杂度是O(N)。在新增和删除的节点的过程中,因为要维护上层索引,且排序,时间复杂度也是logN。
优点:在数据量大且读多写少的场景下,能让链表查找的时间复杂度降低,Redis底层的链表是双向链表,很好的支持了zset的范围查询。
缺点:需要更多的空间,每次插入删除都要维护上层索引,写多的场景下效率存在折中。
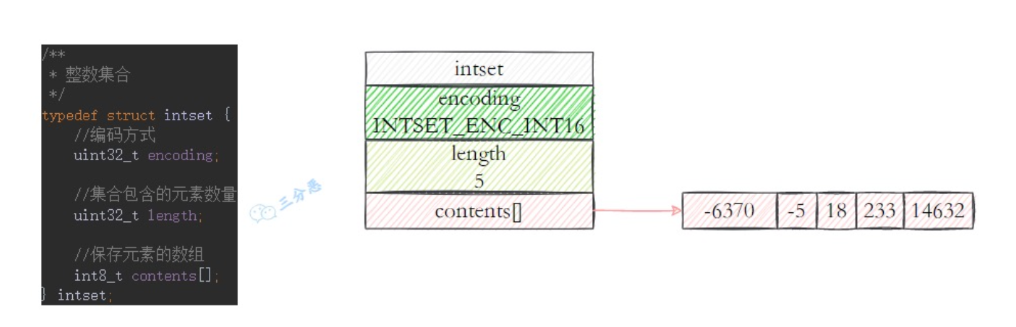
Redis中的整数集合intset
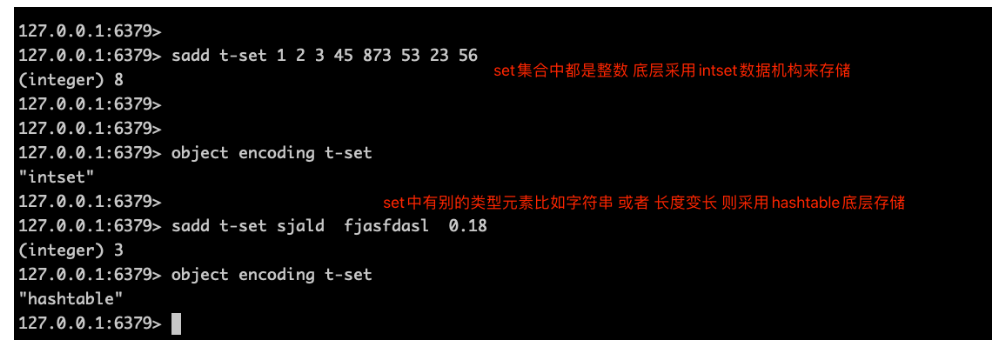
用于保存整数值的抽象数据结构,不会出现重复元素。
Redis中的set value默认是用值为null的字典ht实现的。(和java中HashMap、HashSet很像),当值元素都是整数时,使用此intset结构来存储value。
1
2
3
4
5
6
7
8
9
10typedef struct intset {
//编码方式
uint32_t encoding;
// 数组长度
uint32_t length;
// 保存元素的数组
int8_t contents[]
}