
LRU算法概述
LRU:Least Recently Read (最近最少访问),是一种常见的缓存淘汰算法,当容量不够时淘汰最近最少访问的元素。
使用示例
1 | /* 缓存容量为 2 */ |
一些特点
- 查找效率高。尽量O(1)的查找效率
- 插入、删除要求效率高,容量满的时候要淘汰最近最少访问的元素。
- 元素之间是有顺序的,因为区分最近使用和久未使用的数据。
实现LRU核心数据结构
- hash表:快速查找,但是各个节点的数据不是有顺序的。
- 链表:插入删除快,有序但是查找速度不快。
最终结合两种数据结构。哈希链表
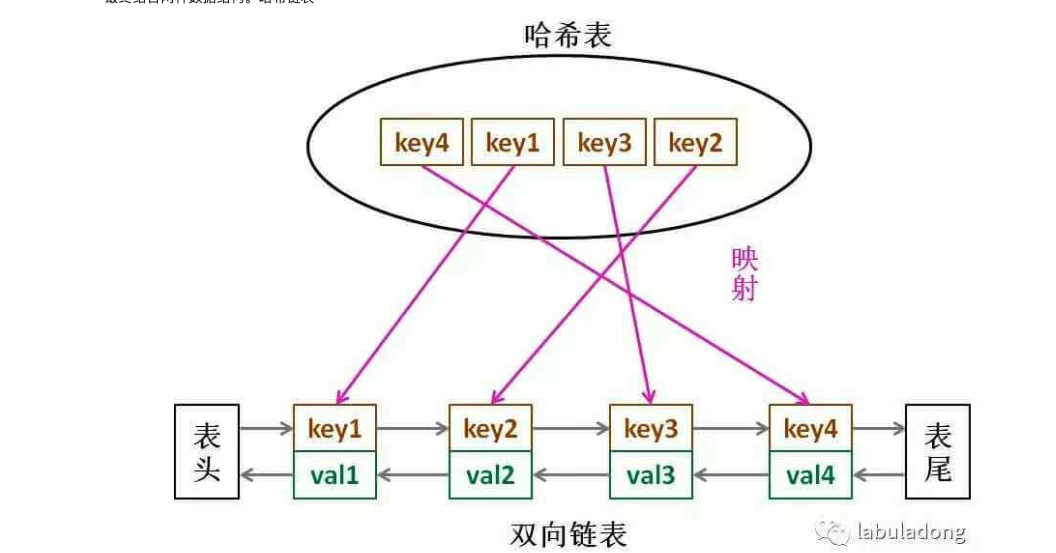
这里的两个问题:
为什么链表是双向链表?
因为在容量满足了之后需要对链表尾部的节点删除,这时候要断开上一个节点和其的链,这就需要找到上一个节点。为什么链表中也是key和value,不能直接放value吗?
因为在删除尾部节点的时候需要同时删除hash表中的元素,这时候需要根据key来删除,索引链表里也要冗余key。
java代码实现
使用HashMap和LinkedList来实现
1 | class LRUCache { |
使用HashMap和自定义的双向链表实现
- 自定义双向链表的节点和双向链表
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23/**
* 双向链表节点
*/
public class DeListNode <Key, Value>{
private Key key;
private Value value;
// 前驱节点
private DeListNode<Key, Value> prev;
// 后继节点
private DeListNode<Key, Value> next;
public DeListNode(Key key, Value value)
{
this.key = key;
this.value = value;
}
public String toString() {
return String.format(" (key:%s,value:%s) ", key, value);
}
}
1 | /** |
- 实现LRUCache
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97public class 实现LRU {
/**
* 简单双端队列
* @param <Key>
* @param <Value>
*/
public static class LRUCache <Key, Value>{
// 容量
private int cap;
// hash表
private HashMap<Key, DeListNode<Key, Value>> map;
// 双向链表缓存
private DeLinkedList<Key, Value> cache;
// 初始化函数
public LRUCache(int cap) {
this.cap = cap;
map = new HashMap<>(cap);
cache = new DeLinkedList<>();
}
/**
* 根据key获取value
* 逻辑:
* 1. 如果缓存中不存在 则返回null
* 2. 如果存在,将命中的元素移动到队头(LRU的逻辑) 返回元素
* @param key
* @return
*/
public synchronized Value get(Key key) {
if (!map.containsKey(key)) {
return null;
} else {
// 移动元素到队尾 采用先删除再插入的方式
DeListNode<Key, Value> keyValueDeListNode = map.get(key);
cache.remove(keyValueDeListNode);
cache.addLast(keyValueDeListNode);
return keyValueDeListNode.getValue();
}
}
/**
* 添加一个元素到LRU缓存中
* 逻辑:
* 1. LRUCache中是否存在key 如果存在替换对应的node 即map.put 然后维护双向链表(插入再删除)
* 2. 如果不存在 需要根基cap判断是否需要淘汰队头元素。 队列尾部添加节点 map中添加然后删除淘汰的key
*
* @param key
* @param value
*/
public synchronized void put(Key key, Value value) {
// 构造新节点
DeListNode<Key, Value> node = new DeListNode<>(key, value);
if (map.containsKey(key)){
// 存在key 则去替换map中的节点 且维护双端队列(删除再添加)
cache.remove(map.get(key));
cache.addLast(node);
map.put(key, node);
} else {
// 不存在要去判断是否触发淘汰
if (cap == cache.size()) {
// 双端队列队头淘汰(LRU逻辑)
DeListNode<Key, Value> first = cache.removeFirst();
// map中remove
map.remove(first.getKey());
}
// 直接添加到尾部即可
cache.addLast(node);
// map中添加
map.put(key, node);
}
}
public void printf() {
System.out.println("cachhe 队列" + cache.toString());
}
}
public static void main(String[] args) {
// 初始化为2的lruCache
LRUCache<Integer, Integer> lruCache = new LRUCache<>(2);
lruCache.put(1, 1);
lruCache.put(2, 2); // 新 [(2,2), (1,1)] 旧
lruCache.printf();
Integer integer = lruCache.get(1); // 新 [(1,1), (2,2)] 旧
lruCache.printf();
lruCache.put(2,3); // 新 [(2,3), (1,1)] 旧
lruCache.printf();
// 再添加 淘汰的是1
lruCache.put(4, 4); // 新 [(4,4), (2,3)] 旧
lruCache.printf();
}
}