
GC日志
输出的GC日志是分析线上问题的很关键的点,要能看懂不同收集器下对应的垃圾回收日志,比如CMS回收器的每次GC的每个阶段都在GC日志里详细标出。
对于应用程序可以配置jvm参数:1
2-Xloggc:./gc-%t.log -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+PrintGCTimeStamps -XX:+PrintGCCause
-XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=10 -XX:GCLogFileSize=100M
其中:
- -Xloggc:./gc-%t.log:日志文件存放的位置,./是当前位置
- -XX:PrintGCDetails:打印GC日志详细信息
- -XX:PrintGCDateStamps:打印GC发生日期戳
- -XX:PrintGCTimeStamps:打印GC发生时间戳
- -XX:PrintGCCause:打印GC原因
- -XX:UseGCLogFileRotation:滚动日志记录
- -XX:NumberOfGCLogFiles=10:分为10个日志文件记录
- -XX:GCLogFileSize=100m:每个日志文件100兆大小
GC日志关于内存展示:
num1 -> num2(num3)。其中:
- num1:GC之前此区域的使用大小
- num2:GC之后此区域的使用大小
- num3:此区域的总容量
Parallel收集器的GC日志
Parallel年轻代的收集器是Parallel Scavenge,老年代的垃圾收集器是Parallel Old。
MinorGC
1 | 2020-07-10T17:45:40.296+0800: 1.285: |
- GC (Allocation Failure):代表一次MinorGC。Eden区分配内存失败引起的。
- PSYoungGen:年轻代,收集器是Parallel Scavenge
- 49152K->3892K(57344K):年轻代GC之前使用大小49152K,GC之后使用3892K,年轻代总内存57344K。
- 49152K->3900K(188416K):堆内存GC之前使用大小49152K,GC之后3900K使用大小,总共188416K。
- 0.0080059 secs:总共耗时
- Times: user=0.03 sys=0.00, real=0.01 secs:分别代表用户态消耗的CPU、内核态消耗的CPU时间、real是操作从开始到结束经理的墙钟时间。墙钟时间和CPU时间区别是:墙钟时间包含各种非运行的等待耗时,比如等待IO、等待磁盘、等待线程阻塞等,而CPU时间不包含这些,现在是多CPU或者多核机器,user+sys > real是很正常的。
FullGC
1 | 2020-07-10T17:45:44.450+0800: 5.439: |
- Full GC (Metadata GC Threshold):因为元空间不足引起的FullGC
- PSYoungGen: 4286K->0K(201216K。):年轻代GC前占用4286K,GC后占用0K,总共201216K。
- ParOldGen: 3289K->7277K(74752K):老年代使用Parallel Old垃圾收集器,GC前占用3289K,GC后占用7277K,总共大小74752K。
- MetaSpace: 20854K->20854K(1069056K):不赘述和上面一样。
CMS垃圾回收器的GC日志
1 | # 1.CMS初始标记 标记GCRoots直接关联的对象 会STW 第一个内存是老年代 第二个内存数据是堆内存 |
CMS在资料里主要是四个阶段:初始标记、并发标记、最终重新标记、并发清理。在GC日志中会比较细和多了预清理、并发重置的过程。
CMS的concurrent mode failure
CMS在并发标记或者并发清理阶段(不会STW)中,可能因为之前浮动垃圾的产生,或者老年代担保机制失败,或者启动CMS垃圾回收的阈值太大导致剩余空间不够用等原因,可能又会触发了FullGC,那么会出现Concurrent mode failure,此时CMS会退化为单线程的Serial Old垃圾回收器。1
2
3
4
5
6
7
8# CMS并发标记开始
2022-05-23T16:34:29.502-0800: 0.687: [CMS-concurrent-mark-start]
# FullGC(可能是浮动垃圾+用户线程触发)
2022-05-23T16:34:29.503-0800: 0.688: [Full GC (Allocation Failure) 2022-05-23T16:34:29.503-0800: 0.688: [CMS2022-05-23T16:34:29.529-0800: 0.714: [CMS-concurrent-mark: 0.026/0.027 secs] [Times: user=0.04 sys=0.00, real=0.02 secs]
# concurrent mode failure 退化为SerialOld。
(concurrent mode failure): 194559K->194559K(194560K), 0.1069558 secs] 203774K->203771K(203776K), [Metaspace: 3306K->3306K(1056768K)], 0.1070098 secs] [Times: user=0.12 sys=0.00, real=0.11 secs]
可以看到在并发标记开始之后,触发了一次FullGC(用户线程没有STW),此时FullGC之后会有concurrent mode failure,CMS退化为Serial Old。
G1垃圾回收器
深入理解JVM中的知识点
G1(Garbage-First)收集器也是追求很低的停顿垃圾回收时间的收集器,在高版本的jdk中建议使用。
在G1之前垃圾收集器都是收集单独的年轻代或者老年代对象,而G1收集器将整个Java堆空间分为多个大小相等的Region,虽然还在概念上保留着新生代和老年代,但不再是物理隔离划分的Region,都是一部分Region(不需要连续)的集合。
G1垃圾回收器之所以能建立可预测的停顿时间模型,是因为其可有计划的在Java堆中进行全区域的垃圾收集。各个Region定义了一个垃垃圾堆积的价值大小(回收所获得的空间大小以及回收所需要时间的经验值),G1在后台维护了一个优先列表, 每个根据允许的回收时间,来选择优先回收价值最大的Region(这解释了为什么叫做Garbage First)。这种使用了Region划分内存的方式和具有优先级回收的方式,保证了G1在有限时间内尽可能获取到最高的回收效率。
回想之前垃圾回收器的跨代引用,如果回收新生代时也要扫描老年代的引用,那么MinorGC的效率会很低。G1也存在这个问题,每个Region不可能是单独独立的,可能存在Region之间的相互引用,如果要扫描整个堆空间,那效率是不可接受的。和跨代引用一样,Region之间的对象引用扫描效率问题都是使用RememberdSet来避免扫描全部区域的。G1每个Region都有一个对应的RememberedSet,虚拟机在发现对Reference类型的对象赋值操作时,会通过内部写屏障来实现将跨Region的引用信息维护被引用对象的RememberedSet中,所以在GCRoots扫描过程中只扫描存在跨Region的区域即可,不需要扫描整个堆,提高了扫描效率。
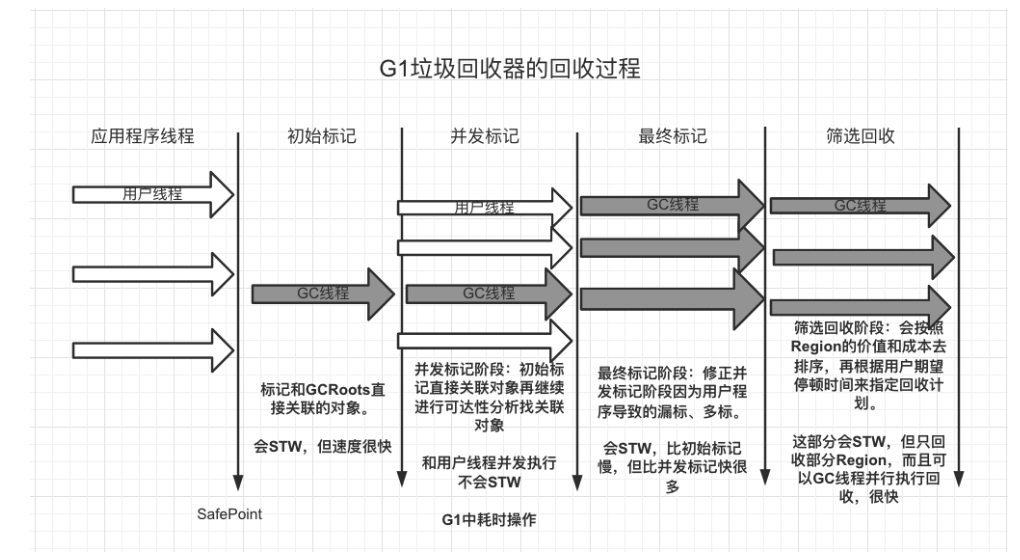
G1垃圾回收的过程
- 初始标记(Inital Marking):仅仅是标记一下GCRoots能直接关联的对象,这部分只扫描直接关联的对象,很快,同时此阶段需要STW。
- 并发标记(Concurrent Marking):此阶段是从GCRoots开始对堆中对象进行可达性分析,标记连通还能存活的对象。和CMS一样,这个阶段是主要的耗时阶段,但不会STW,即可以和用户线程并发的执行。
- 最终标记(Final Marking):修正在并发标记阶段因用户线程继续运行而导致标记有误的对象,这阶段会STW,可以并行标记,且时间也不会很长。
- 筛选回收(Live Data Counting and Evacuation):筛选回收阶段首先对每个Region按照回收的价值和成本进行排序(G1自己维护的优先级列表),根据所期望的GC停顿时间计划来回收。注意这部分会STW,且GC线程可以并行执行。
G1的优点
- 并发和并行:G1能在多核环境下使用多个CPU来加快STW的时间(并行),而且在一些耗时阶段是可以也可以和用户线程一起运行,并STW用户线程(并发)。
- 分代收集:G1的分代收集还是得以保留。G1可以不搭配其他垃圾收集器配合就能独立管理整个堆,但其保留了分代思想,对新创建的对象、已经存在一段时间、熬过很多次GC的旧对象都采用了不同的方式
- 空间整合:G1从整体看是采用的标记-整理算法实现。但是G1从两个Region来看是基于复制算法实现的。空间整合代表G1在GC之后不会产生垃圾碎片,GC之后都是规整的内存。
- 可预测的停顿:这是G1相比CMS垃圾收集器最大的优势。G1除了和CMS一样追求低停顿外,还建立了可预测的停顿时间模型,能让使用者明确指定在一个长度为M毫秒的时间片段内,停留在垃圾收集上的时间不超过N毫秒。
G1的垃圾回收分类
G1的mixedGC就是把老年代(逻辑分区)的一部分区域加载Eden和Surivor区域的后面,所有要回收的区域叫做Collection Set(CSet),最后用年轻代的算法进行回收。
这里也能看出逻辑分代的好处,没有真正的物理划分,而是通过划分更细粒度的Region来实现的mixedGC要回收的区域。
在执行mixedGC时,其实就是筛选回收的过程,会回收young region和部分old Region还有大对象Region,这其中对回收对象进行了价值排序,根据用户设置的期望停顿时间来优先回收价值高的对象,即G1的可预测的停顿模型。
相关问题
- G1的特点是什么
- 并行和并发
- 分代收集(逻辑分代),内存划分为Region
- 垃圾回收分类为youngGC、mixedGC、fullGC
- 整体来看采用标记-整理算法,不会有空间碎片产生,region之间采用复制算法清除(年轻代的younggc和mixedgc)
- 最显著的特点:可预测的停顿模型。可以按照用户设置的在GC上停顿的时间来执行价值排序优先级的回收,实现追求最低停顿的GC时间。
- 适用大内存服务器,来设置可预测的GC STW时间
- G1和CMS的区别
- G1对整个内存区域回收、CMS是老年代的回收器,需要搭配ParNew等年轻代垃圾回收器一起使用
- CMS是标记-清除算法,G1是标记-整理算法
- 增量阶段的处理,CMS采用增量更新,G1采用的是satb(快照)
- G1分代但是逻辑分代。
- G1最大的特点:提供了用户可设置的GC停顿时间,提供了可预测的停顿模型,适用于大内存。
- G1如何控制暂停时间
- 对young gc控制新生代Region的大小,会根据设置的-XX:MaxGCPauseMills值来调整,来减少触发YoungGC的次数。
- 对mixed gc控制回收region的个数,根据参数-XX:InitiatingHeapOccupancyPercent值触犯,回收所有的Young区、部分Old区(根据期望的GC停顿时间对old区垃圾收集排序选出)、和大对象区,采用复制算法。
- fullgc:会暂停应用程序,退化为单线程去标记、清除和压缩整理。
大内存系统为什么适合使用G1
类似于Kafka这种支撑高并发系统,会部署很大内存的机器,比如年轻代可能都会很大,这种情况下因为eden区的回收可能变得很慢(相对于常见4G的机器的eden区),那young gc带来的stw对于系统来说不能接收。那么在这种情况下G1可以设置期望的最大GC暂停时间,-XX:MaxGCPauseMills,整个系统在GC上的时间大幅降低,可以最大限度的一遍用户线程在跑,一遍去GC。G1天生适合大内存机器来对JVM进行垃圾回收,可以解决大内存机器垃圾回收时间过长造成停顿的问题。