
JVM的整体结构和内存模型
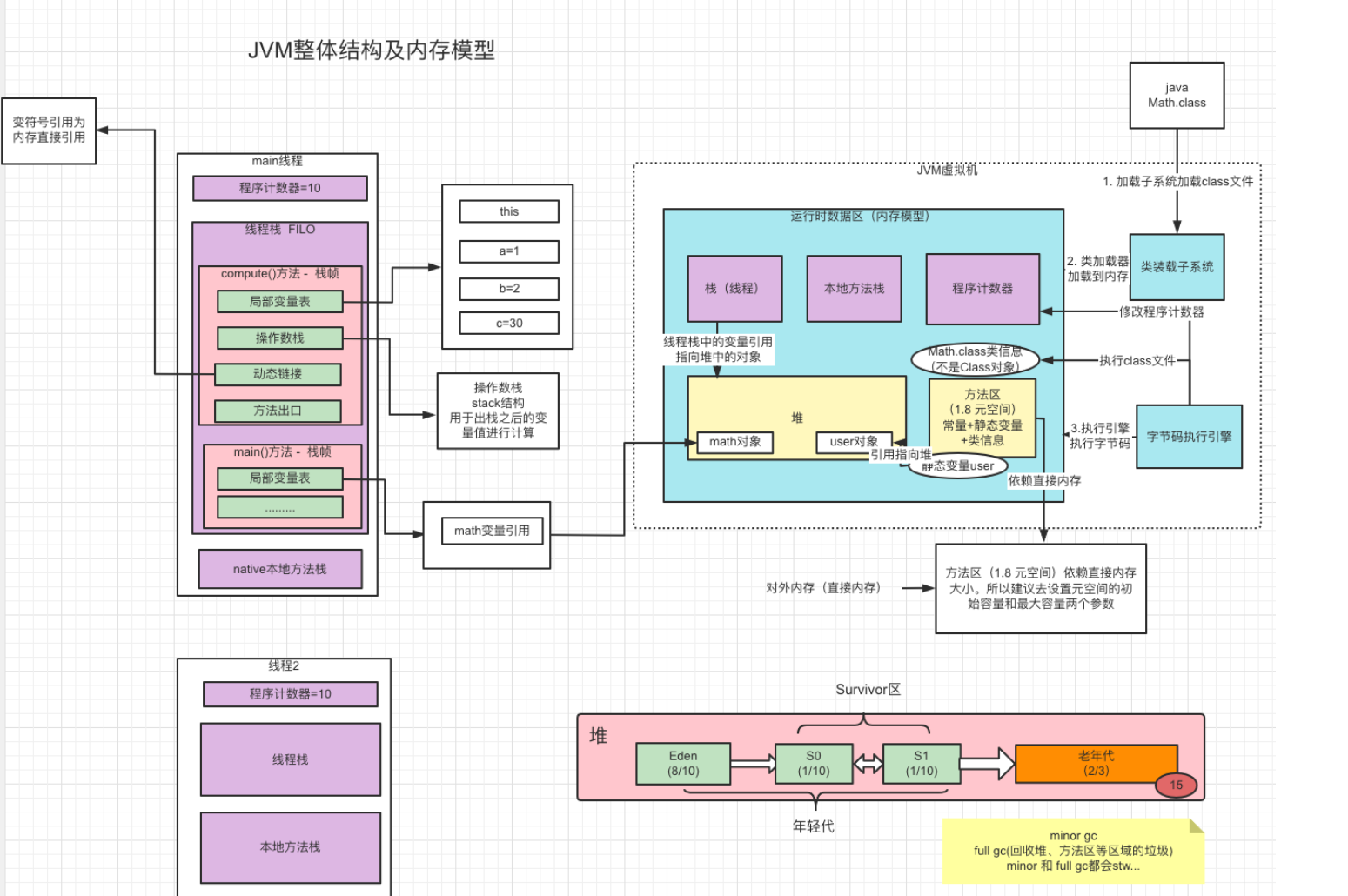
关于方法区和元空间
- jdk1.8之前存放方法元信息、Class信息、常量池等的为方法区,在堆内存储。而在1.8之后废弃了永久代,替换为元空间,常量池和静态变量并入堆内存储,MetaSpace来存储类、方法元信息,同时使用了本地内存来存储。
- 相当于1.8版本之后,方法区一部分归到堆内存中,一部分移动到堆外内存,受机器本地内存大小限制。不过设置了Metaspace参数也会在内存不足时OOM。
JVM内存参数设置(简要说明)
运行时数据区的一些基本参数
- -Xms:堆的最小值参数
- -Xmx:堆的最大值参数
- -Xmn:新生代的内存大小
- -XX: MaxDirectMemorySize:直接内存的最大值。即NIO使用的堆外内存的最大值。 这里注意heap dump不会记录堆外内存的移除,但也可以造成OOM,现象是dump文件很小,即堆内存其实使用很少。
- -XX:MetaspaceSize:设置元空间触发fullgc的初始阈值(元空间没有固定初始值大小)。默认不设置为21M。到达该值就会触发full gc进行类型卸载,同时收集器会对该值进行调整,如果释放了大量空间,则调小;如果释放了很少的空间,则在不超过-XX: MaxMetaspaceSize的情况下适当提高此值。 在jdk1.8之前的永久代参数-XX: PermsSize参数标识为初始化的容量,1.8之后调整为元空间后不一样
- -XX: MaxMetaspaceSize:元空间最大值,默认是-1,不限制的话,受限于直接内存大小。
- -Xss:线程栈的大小(默认为1M)
常量池
Class常量池和运行时常量池
Class文件中包含常量池,也包含字段、方法、接口、类版本等描述信息。常量池用于存放编译期间的字面量和符号引用。

当常量池字面量和符号引用被加载到内存中,符号才会有内存的地址,常量池就是运行时常量池。
而动态链接的过程就是把运行时常量池的符号引用变为直接内存地址引用。
常量池在1.8之后从永久代(元空间)拿出,移动到了堆内存。
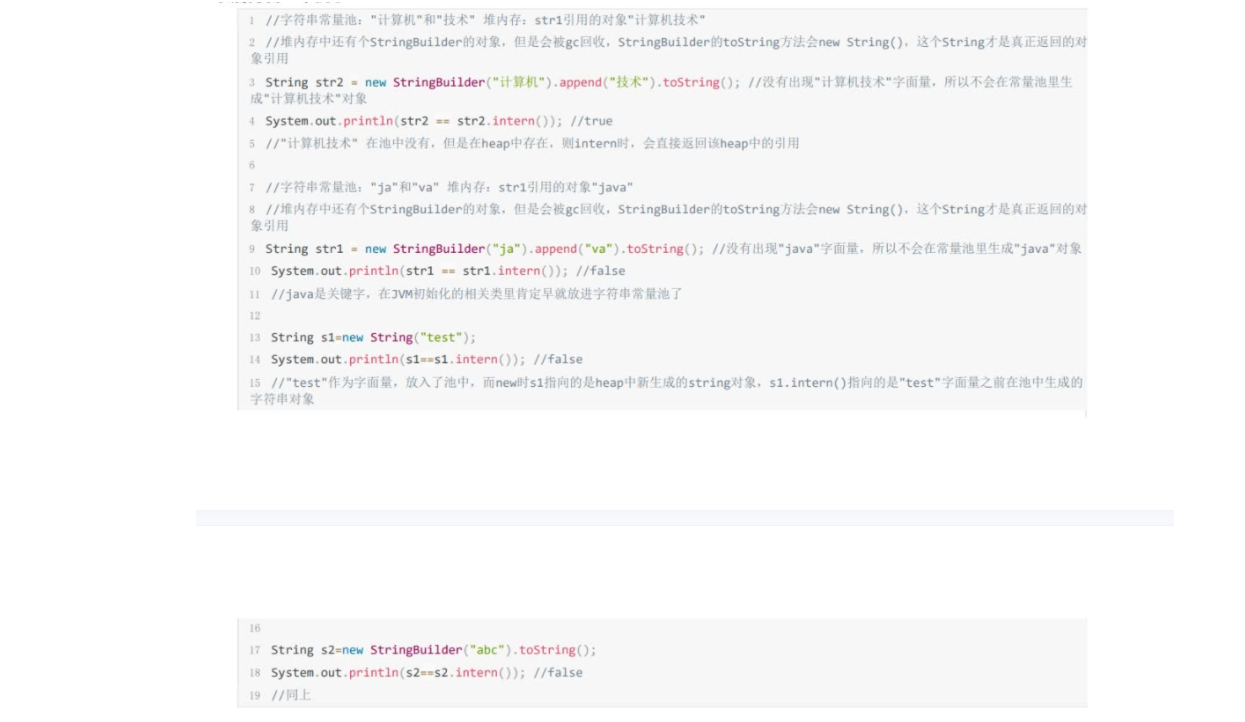
字符串常量池
创建字符串对象时,做了一些优化:
- 如果字符串常量在常量池中存在,返回此常量的地址引用;
- 如果不存在,则实例化改字符串放入常量池中,是字面量的引用直接返回,是new String()这种则会在堆内新创建一个对象。
字符串操作
- 字面量直接赋值
1
String a = "aaa";
这样会用equals()方法判断字符串常量池是否存在,如果存在返回引用,不存在创建一个放入字符串常量池之后返回引用。
- new String()复制
1
String a = new String("aaa");
这里也会判断字符串常量池和堆中是否有这个对象,没有则都创建,然后返回堆中的对象引用。也就是可能会创建两个对象。
- intern方法
1
2String s1 = "aaa";
String s2 = s1.intern();
一个native方法,调用intern()时如果字符串常量池中存在常量,则返回池中的引用地址,否则将池中的地址直接指向堆中字符串对象(例子是s1)的地址。
常见面试题


关于String是不可变的
除非下面的a、b、c三个变量被final修饰,即变为常量,那么执行String s1 = a + b + c时会编译为常量进行优化,也就是和String s = “a” + “b” + “c” 字面量直接相加一样,都是字符串常量池中常量对象的引用。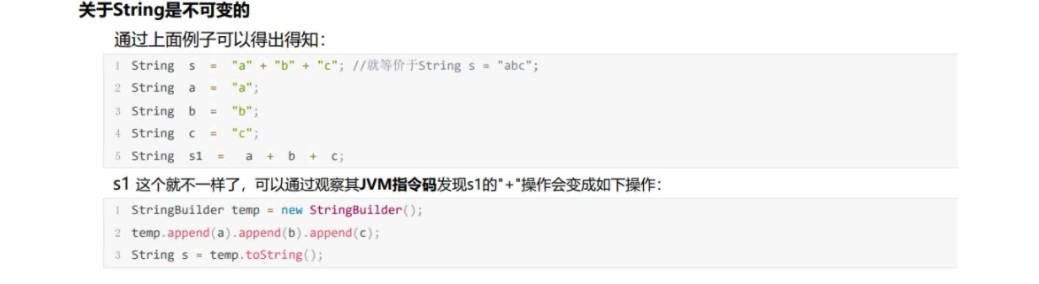
为什么是不可变的?
- 安全。最常用的String内部char[]数组是final的,规避了直接改变对象内容,封装了内部数据。(享元模式)
- 线程安全,final在要求构造函数中初始化char[]数组
- hashcode初始化时确定,String很适合作为hash表的key。
彩蛋:比较对象时为什么要重写hashcode()方法
equals()方法相等,则对象一定相等,为什么还要hashcode方法呢?
- 因为hashcode效率高,一般约束都是equals()方法相等,则hashcode()一定相等;而hashcode()不相等,一定不是一个对象。
- HashSet这种数据结构是去重的,比较时候为了效率如果hashcode不相等,那么即使equals方法相等也会认为不是一个对象。