基本原理

代码
1 | public class SnowflakeIdWorker { |
代码实现细节
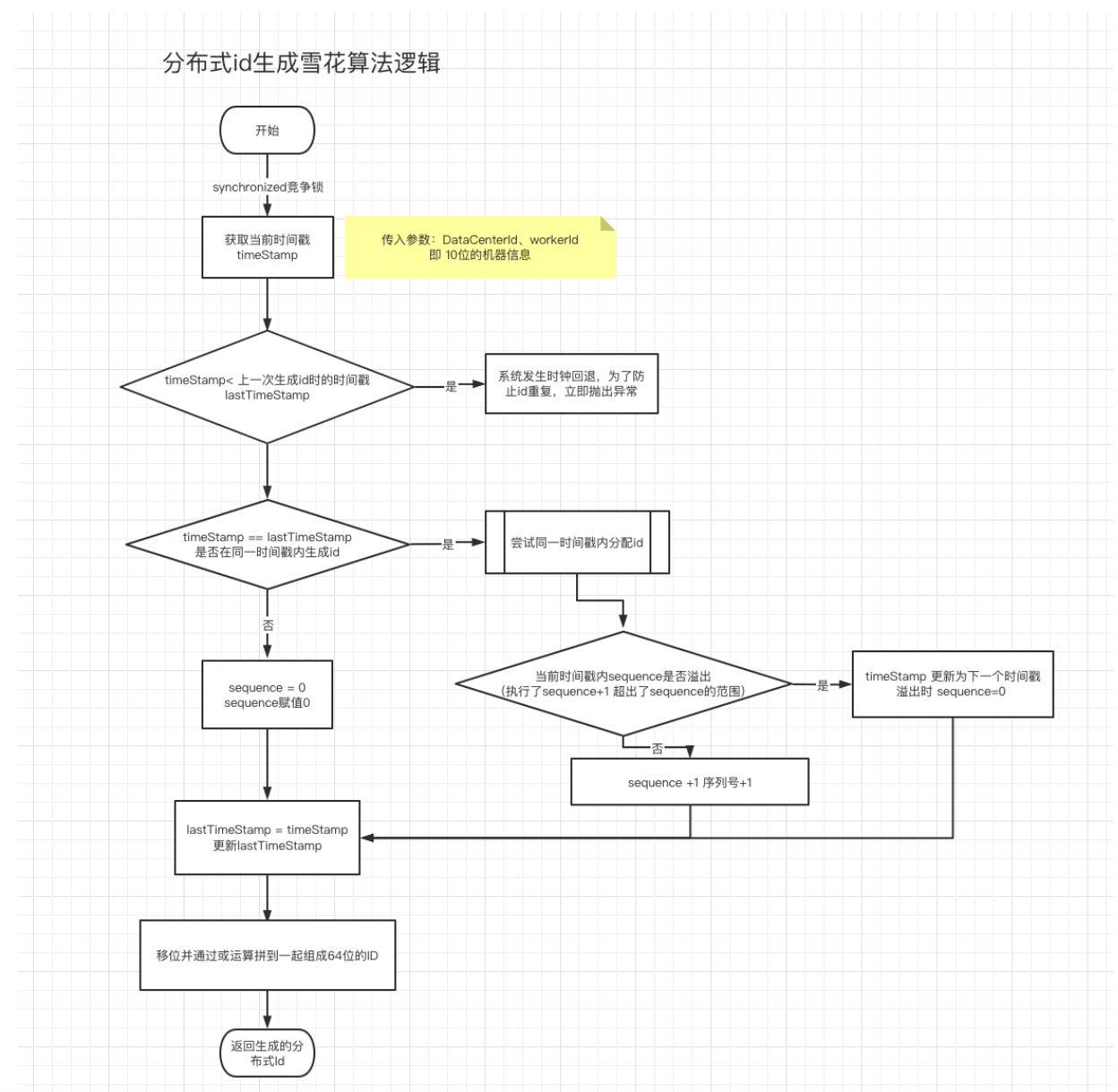
- nextId()方法是加锁的,同进程内需要竞争锁,因为内部有赋值维护sequence(序列号)和lastTimestamp(上次生成id的时间戳)。
- 参数是组成机器部分的dataCenterId和workerId,各占5个Bit位。
- 时钟回退是有可能发生的,如果发生了之后是可能会有分布式id重复的问题,这时候直接报错。(条件是当前时间戳 timeStampe < lastTimeStamp)
- 如果当前时间戳timeStamp和lastTimeStamp相等,说明是同一个时间戳的获取分布式id的流程,这时候通过sequence增加来分配id。
- 如果sequence + 1之后和sequence的掩码做 &操作,如果算出为0,则说明12位的sequence发生了溢出,这时要将timeStamp更新为下一个时间戳来获取分布式id。
- 最后根据雪花算法,将移动对应的位之后再做或操作生成对应的64位id。
位运算的运用
- sequence++之后判断是否溢出(大于对应的sequence的值的范围),用的是 sequence++ & sequenceMask == 0 来判断,这里掩码是2^12 - 1。与运算是二进制位都是1的时候才是1,其余为0。这里2^12-1的二进制位是 011111111111 做与操作结果为0 说明是和10000000000 做了与操作,即代表了溢出。
- 最后按照雪花算法从高到低的位置左移对应的长度,再做或操作。或操作是当全为0时,结果的二进制位为0, 其余情况为1。高位比如时间戳已经左移了(10 + 12= 22位),后面的22位都是0, 此时和代表机器位置的数字做或操作,即将机器的10位二进制数字直接填充对应的位置即可。同理sequence的二进制位也一样。这样通过或运算就将 三部分的二进制位拼接了起来。
雪花算法流程