
为什么redo log具有数据恢复能力
Mysql的binlog只能用于归档,不足以实现崩溃恢复(Crash-Safe),需要借助引擎层的redo-log才能拥有崩溃恢复的能力。 所谓崩溃恢复,即指在数据库宕机恢复之后,也要保证事务的完整性,不能做一半操作,同时也要注意主从同步的一致性。
简单看下binlog和redo log的区别:
- 适用对象不同
- redo log是针对innodb引擎特有的。
- binlog是server层实现的,所有存储引擎可以使用
- 写入内容不同
- binlog是逻辑日志,是语句的原始语义,比如“给id为1的记录的age字段+1”。
- redo log是物理日志,记录的是“表空间号 + 数据页 + 偏移量 + 修改内容”
- 写入方式不同
- binlog是追加写入的,在写入一定大小的文件之后会切换下一个文件进行写,不会覆盖和删除之前的文件。
- redo log是循环写入的,空间固定会被用完。当redo log两阶段提交落盘之后,会在有限的空间删除这些redo log,是一种循环写。
其中第三点写入方式不同决定了redo log拥有恢复能力,因为追加写没办法看出binlog日志何时写入磁盘的,不能去做区分;而在宕机之后,可以根据redo log中的日志恢复到内存即可,也就是知道要恢复哪些数据。
redo log的两阶段提交
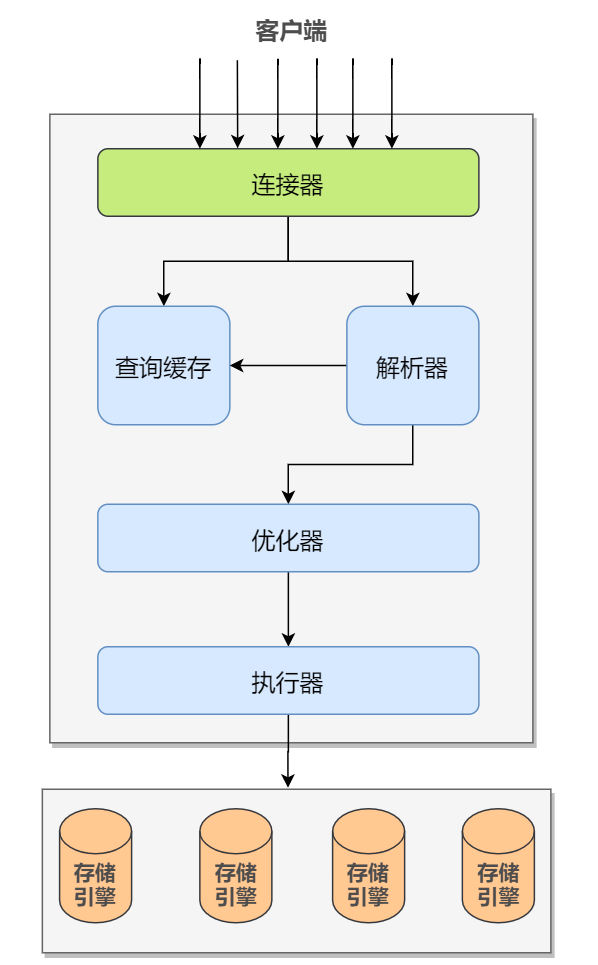
一条sql执行的过程
- MySql客户端和服务端建立连接,客户端发送一条语句到服务端。
- 服务端查询缓存,如果命中缓存,返回结果,否则进入下一步
- 服务端进行SQL解析、预处理、生成合法的语句树。
- 再由优化器生成对应的执行计划
- 执行器根据优化器生成的执行计划,调用存储引擎的API进行执行,把结果返回给客户端。
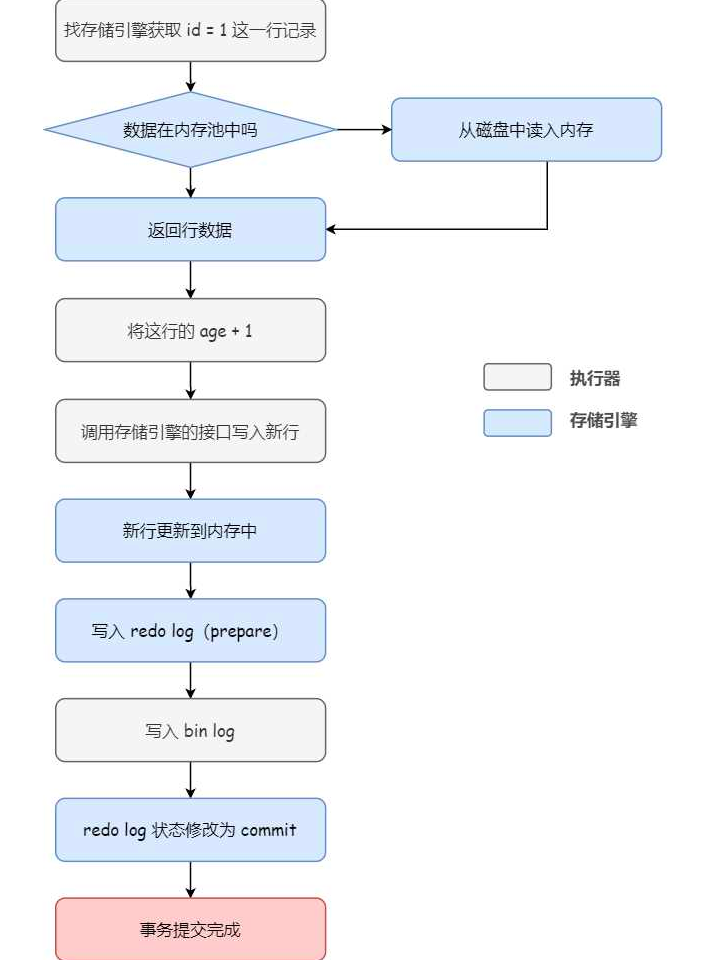
对于一条update的SQL,也是大致上边的步骤,但是在执行器和存储引擎中要多写redo log和binlog的过程。比如对于SQL:1
update table set age = age + 1 where id = 1;
- 执行器:找到存储引擎取id=1的这条记录
- 存储引擎:在id聚簇索引上找到id=1的这行,加载其数据页到缓冲池。返回给执行器。
- 执行器:拿到记录之后,把age字段值+1,得到一个新的记录,调用存储引擎的接口写入这行新纪录。
- 存储引擎:将这行新纪录更新到内存,将这个更新操作写入redo log中,此时redo log为prepare状态。然后告诉执行器执行完成,可以提交事务。
- 执行器:生成binlog,将binlog写入磁盘。
- 执行器:调用存储引擎的接口提交事务。
- 存储引擎:将redo log状态置为commit,更新操作完成
流程图如下:
这里根据两阶段提交的流程,在Crash之后做崩溃恢复流程是这样的:
- 如果恢复时,redo log事务是完整的,即commit阶段,则直接提交。
- 如果恢复时,redo log事务是prepare阶段的,这时需要判断binlog的完整性。
- a. 如果binlog存在且是完整的,则进行提交事务的操作,再写binlog到磁盘,redo log置为commit。
- b. 如果binlog是不完整的,则需要回滚事务。
这里主要是考虑了主备同步的问题,从库都是通过binlog进行主备同步。这里的binlog的完整取决于其自身的格式,比如row模式和statement模式下或者mixed模式下各自的校验,或者各自的checkSum之类的,这里不去纠结。
如果redo log在prepare阶段Crash,但是binlog不完整,那么此时如果去继续提交事务,那么因为崩溃之前的binlog没有生成或者不完整,所以从库是没有这条SQL结果的数据的。所以此时去回滚这个redo log。
反过来,如果是在写入binlog成功之后数据库Crash,那么此时因为 binlog已经写入成功,从库有了这条数据,那么处于prepare阶段的redo log要去commit操作,进行事务的提交来保证主从数据一致性。
所以,处于prepare阶段的redo log和完整的binlog就能保证数据库Crash-Safe了
redo log不用两阶段行不行?
假设也是先写redo log,再写binlog,但是redo log是直接commit的,数据已经修改,这时如果写binlog crash了,那么redo log已经提交,主库中有数据但从库此时无法同步数据,就造成数据不一致。
先写binlog到磁盘 后写 redo log行不行
主从的架构下,binlog到磁盘,从库同步数据,如果在写redo log时Crash,就会造成主从不一致。