
并发编程基础拾遗
在看并发的书或者看并发相关的博客时,会发现一些知识点会遗漏或者之前没有看到,这里去总结一下。
创建线程相关
main线程
我们通常会通过写main方法去创建多个线程,main线程是非守护线程,代表方法的入口。这个时候如果用jconsole去看的话,会发现这时也会启用很多后台线程:比如GC线程、计算引用线程、JMX线程。
线程生命周期
- 新建状态
- 可运行状态
- 运行状态
- 阻塞状态
- 死亡状态
这些个状态之间的转换每次都记得不是很牢固。
当新建一个线程之后,这个线程处于新建状态,这时调用t.start()方法,线程就会进入可运行状态,这个状态下线程还没有真正的执行。当os分配给当前线程时间片的时候,线程会进入运行状态。当线程处于运行状态时,时间片用完或者调用Thread.yield()方法,线程则变回为可运行状态,同样若再获得os的时间片,线程将会再次进入运行状态。当正在运行状态的线程遇到Thread.sleep或者其他线程join的时候,会进入阻塞状态,直到sleep结束或者join线程结束之后线程进入可运行状态等待时间片的分配。(这里不能直接由阻塞状态直接变为运行状态)。当线程处于运行状态的时候,对象调用了o.wait方法,那么线程就会进入等待队列,等待被其他线程唤醒进入锁池,还有如果线程未持有对象的锁而被阻塞的时候也会进入到锁池,直到拿到对象锁标志之后,才能到可运行状态,再次等待时间片的分配。当线程的run方法结束,或者线程是一个守护线程是main线程结束,或者异常退出之后,线程进入到死亡状态。
start()方法和run方法的一个设计
start方法和run()方法是Thread类中的两个方法,我们启动一个线程的时候要调用start方法。
1 | public synchronized void start() { |
在start方法里是调用了一个start0的native方法,这个方法其实是调用的run方法。
1 |
|
这样的设计是体现的设计模式中的一个简单模板方法,在调用start方法的同时其实是调用你重写的run方法,其他的start0和一些线程状态的判断都在start方法中作为不变的部分,而变的run方法则供使用者去实现run方法。
Runnable接口相关
runnable接口的作用
Runnable接口创建线程,这种创建线程的方式可以将run方法的逻辑从new thread的控制中抽离出来,这里如果耦合在new Thread中,没有体现业务可执行逻辑和线程控制分离开,体现了面向对象的思想。其实这种方式体现的是一种策略模式,Runnable接口就像策略模式中的策略接口,实现Runnable接口的run方法的类都是一个线程运行的策略,同时Runnable设计成了函数式接口,也更加灵活。
Thread API相关
new Thread构造函数
Thread构造函数有多个参数的重载,这里去记录下相关的构造函数,并且每个构造函数中参数的含义。
new Thread()
创建线程对象Thread,默认有一个线程名,以Thread-开头,从0开始数。
new Thread(Runnable target)
如果在构造Thread的时候没有传递Runnable或者没有复写Thread的run方法,该Thread将不会调用任何东西,如果传递了Runnable接口的实例,或者复写了Thread的run方法,则会执行该方法的逻辑单元(逻辑代码)。
new Thread(ThreadGroup g)
在创建线程的时候,如果构造函数中未传入threadGroup,则thread会默认获取父线程的threadGroup作为该线程的threadGroup。此时子线程和父线程将会在同一个ThreadGropu中。这时候可以通过threadGroup提供的api去获取一些信息。
比如threadGroup.getActiveCount 获取活跃线程数。
比如threadGroup.enumerate(new Thread[]) 是将所有活跃线程枚举到一个数组中。
new Thread(long stackSize)
stackSize是平常用的比较少的,这里要清楚jvm的一个结构:(这里简单用图去展示了jmm和虚拟机栈中栈帧结构)。jmm的结构:
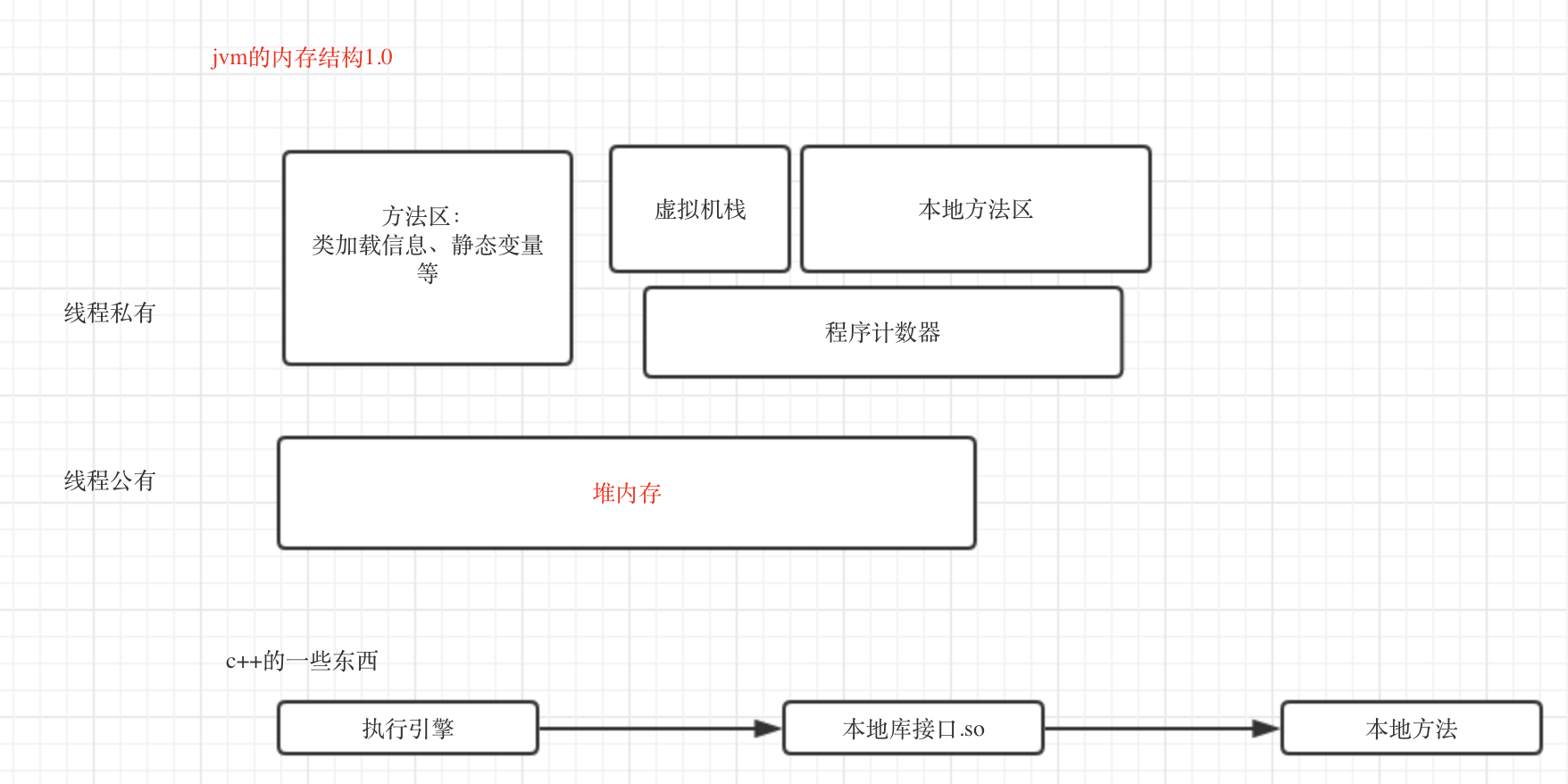
关于变量的存储,这里可以看一下下面代码中的注释:
1 | public class NewThreadWithStackSize { |
栈帧的结构: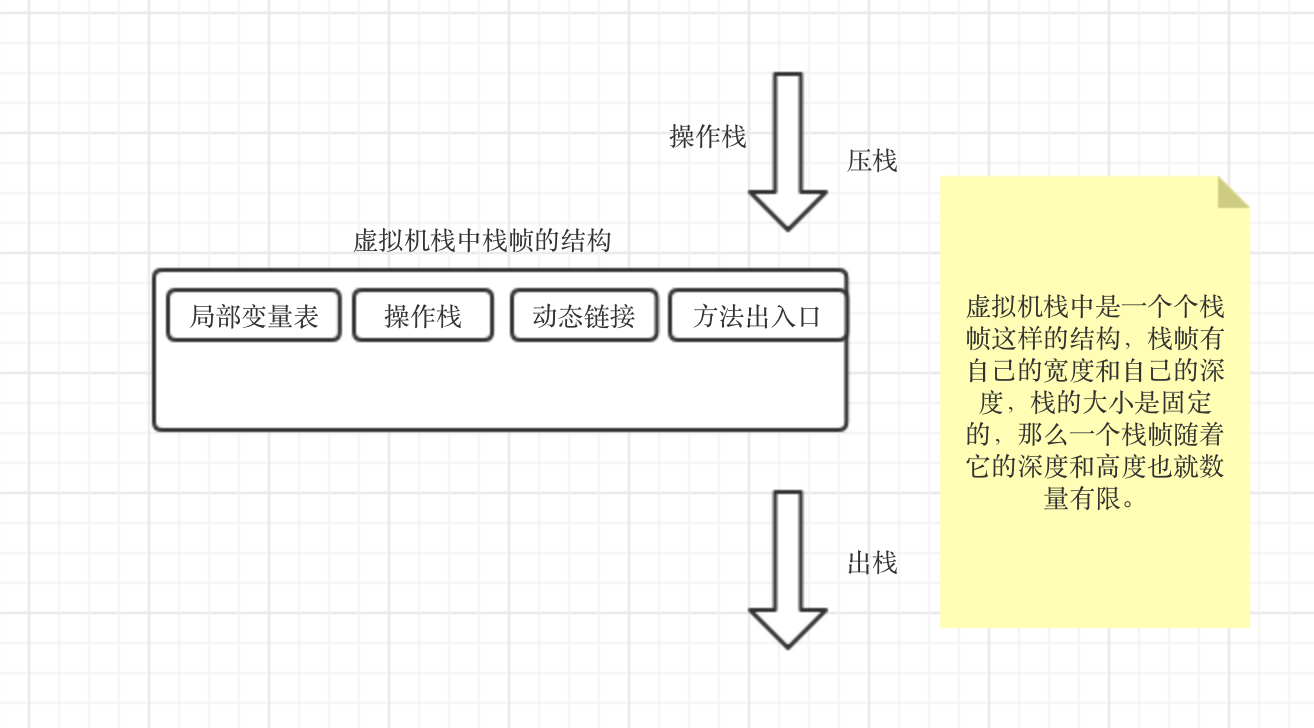
这里可以做一个栈溢出的的例子,来为一个线程分配固定栈空间的大小,看看大概操作栈的次数(这里只是一个大概的数值)
1 | public class NewThreadWithStackSize2 { |
可以看到count的数值是: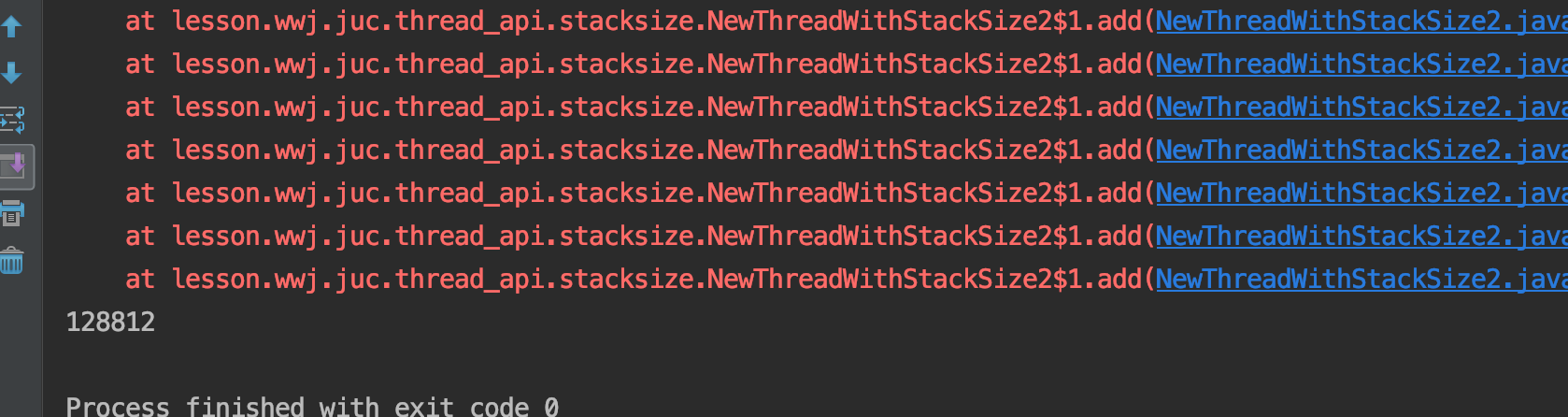
我们可以知道:构造Thread的时候传入stacksize表示该线程占用的stack大小,如果没有指定stacksize的大小,默认是0,0代表着会忽略该参数,该参数会被JNI函数去调用。需要注意:该参数有一些平台有效,有些平台则无效。可以通过jvm参数 -Xss10m 来设置stacksize的大小