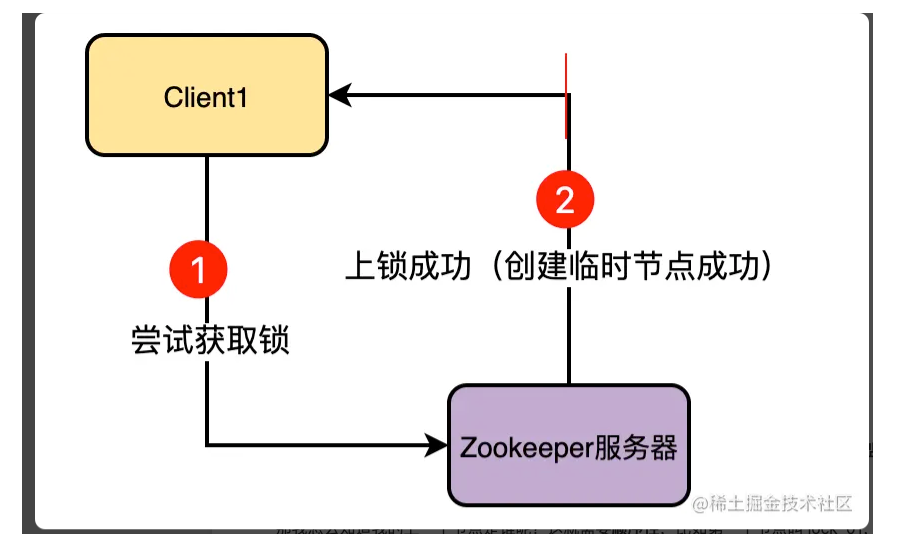
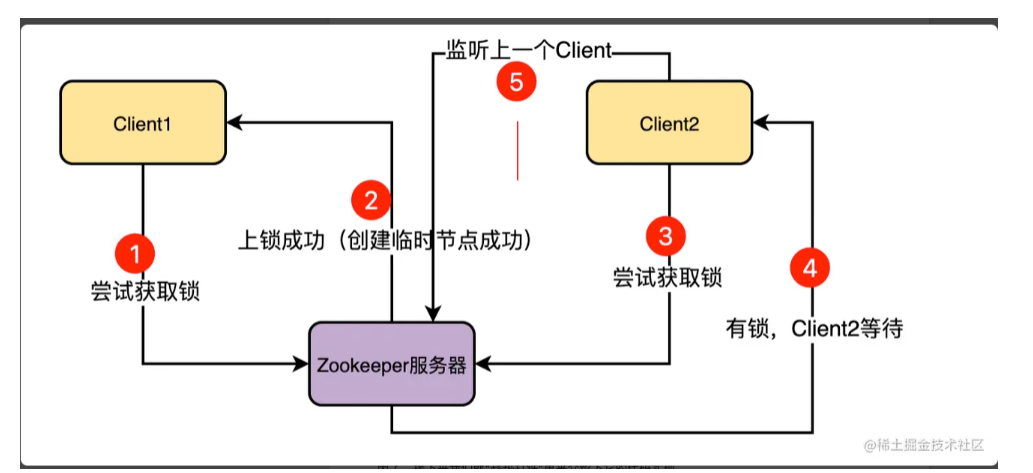
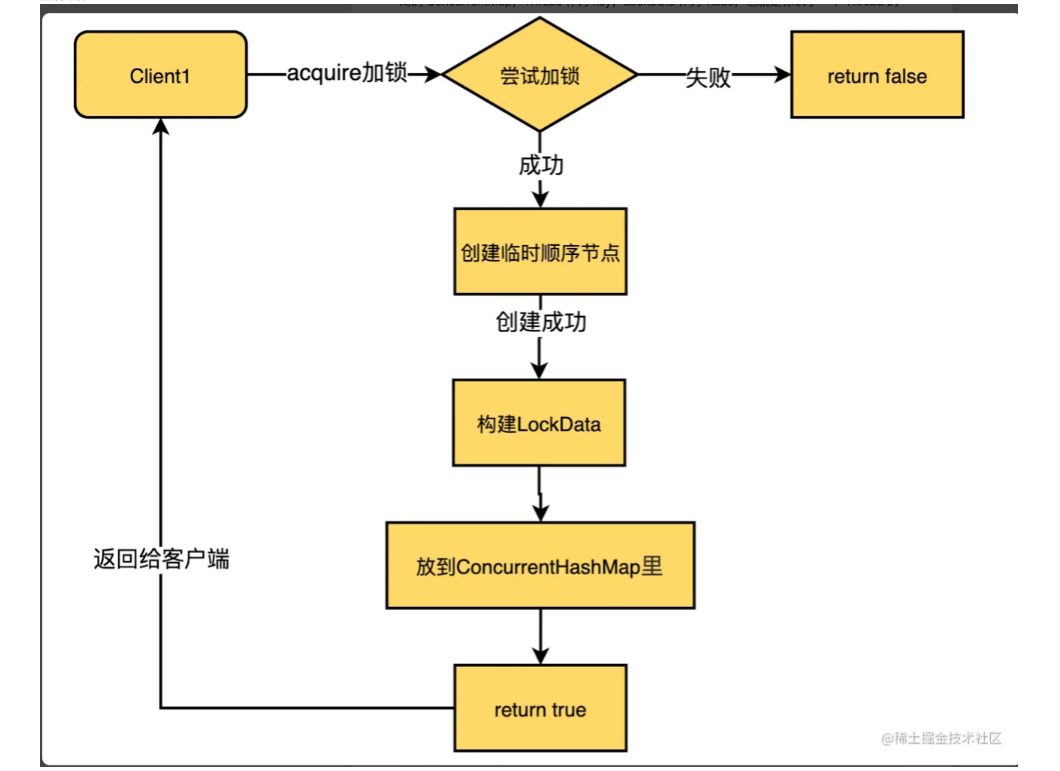
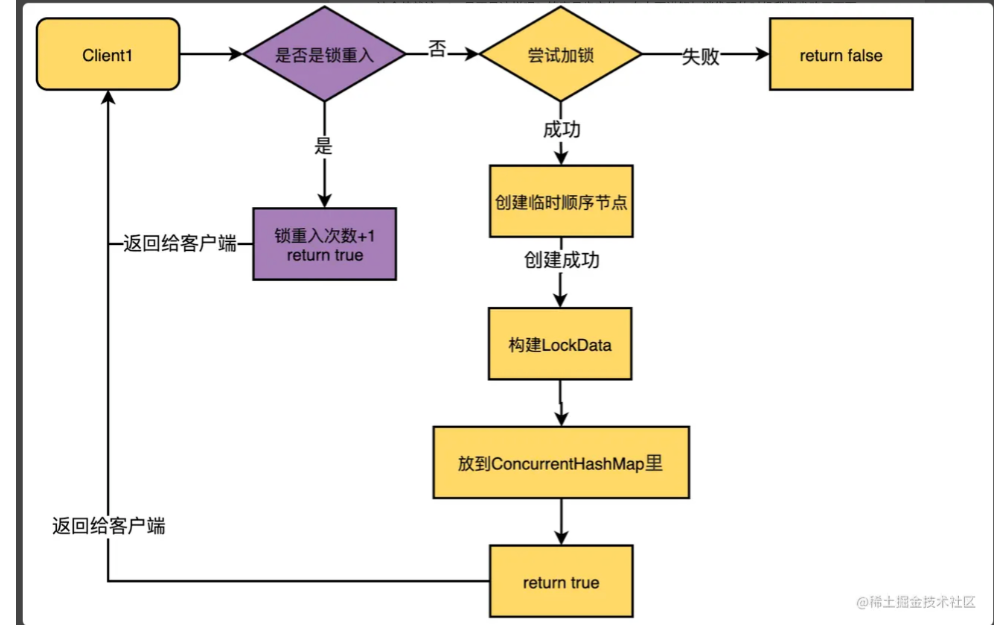
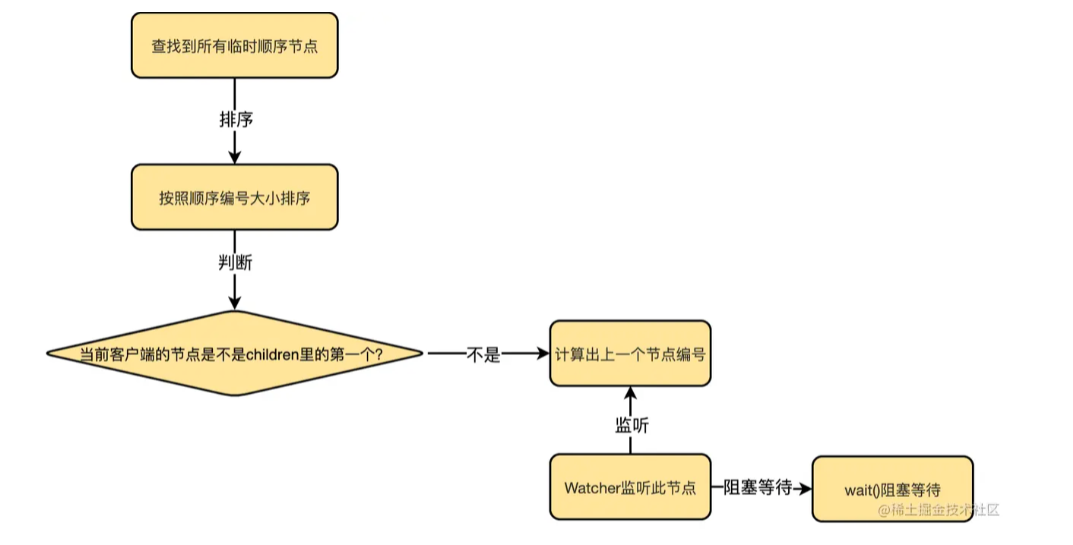
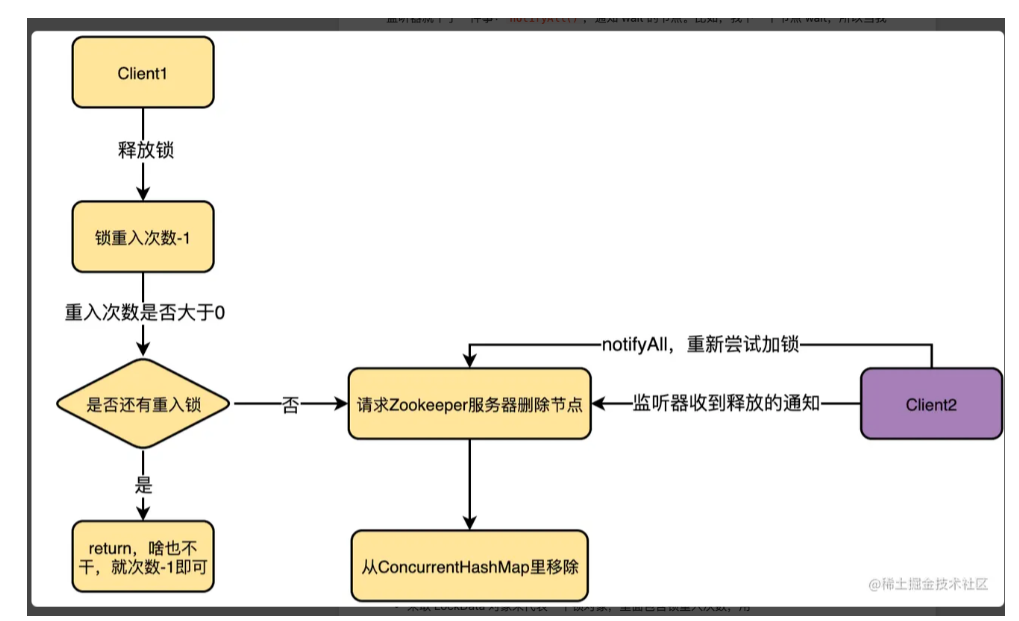
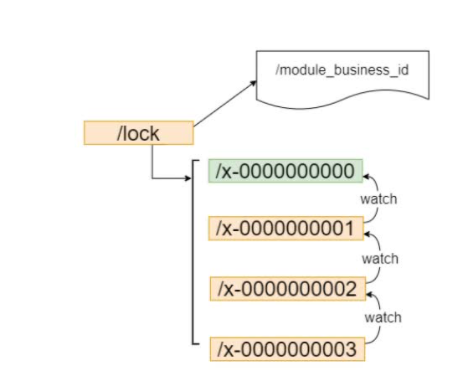
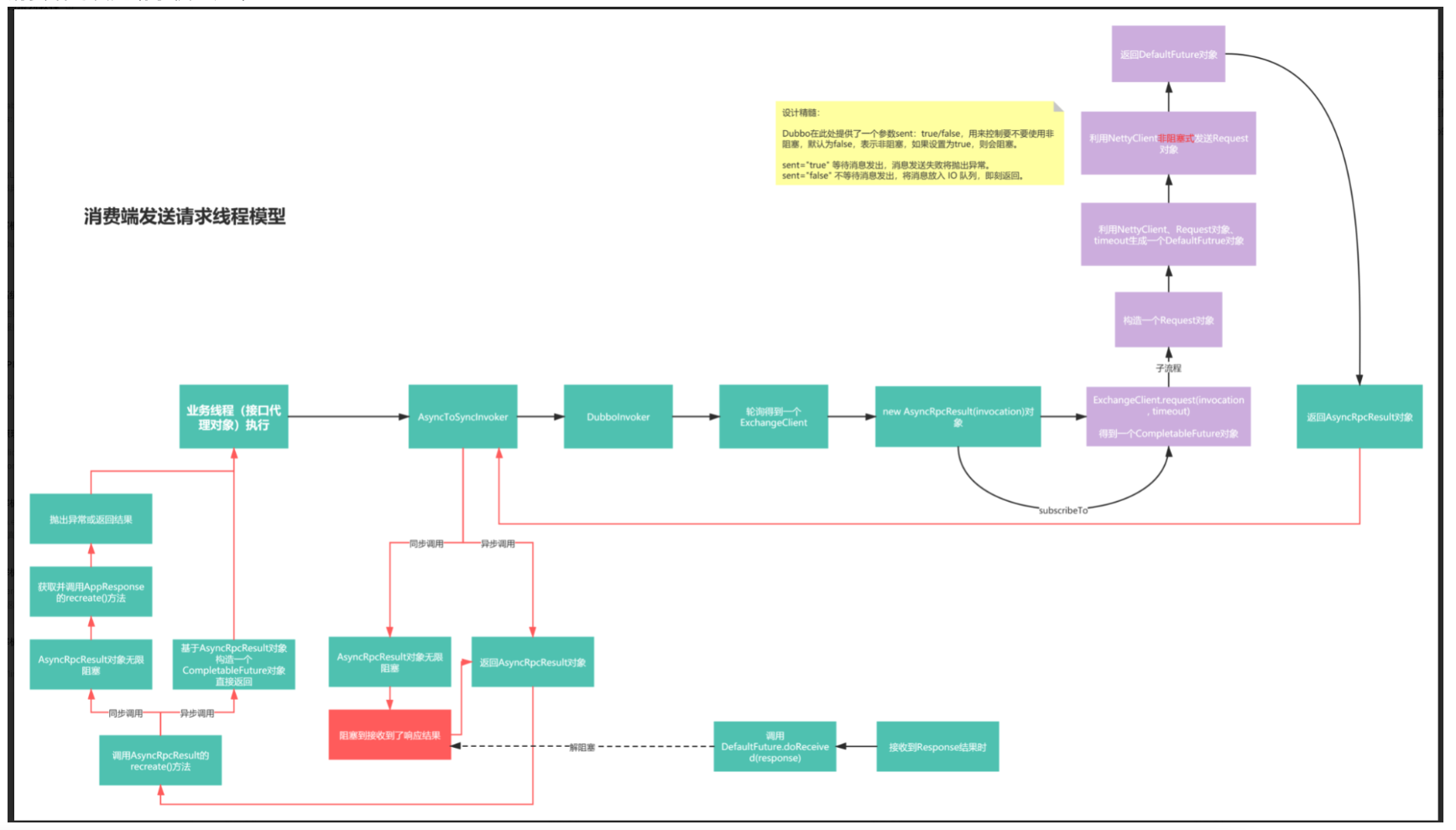
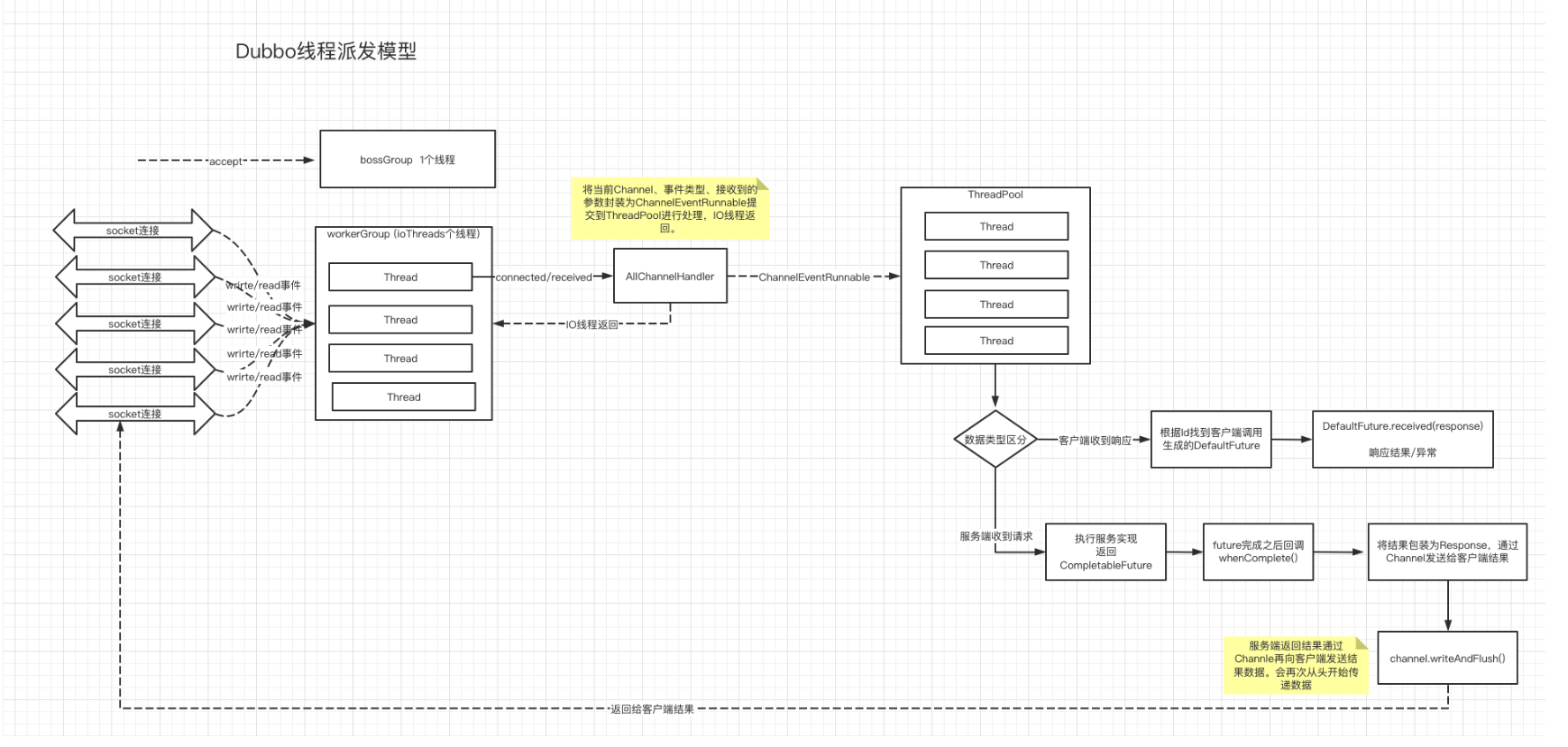
一颗B+树能承载多少数据的计算方式
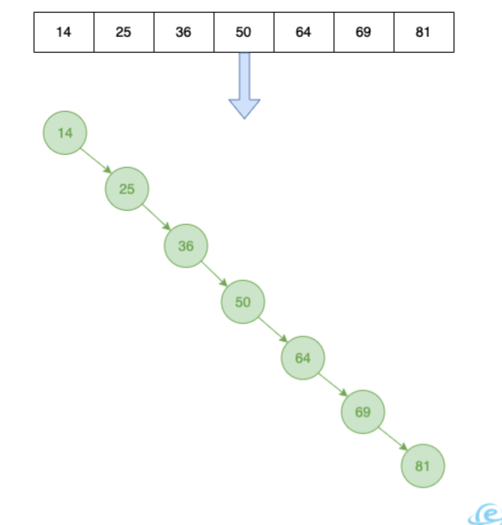
单表数据上亿之后,索引的查询效果可能就没那么明显了。因为B+树的层级可能会变高,定位一条数据可能要经过好几次磁盘IO加载。
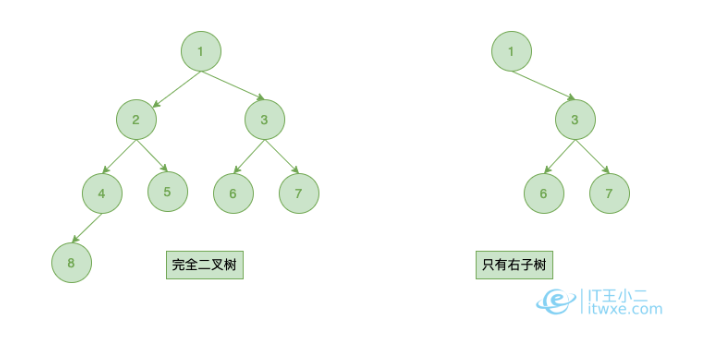
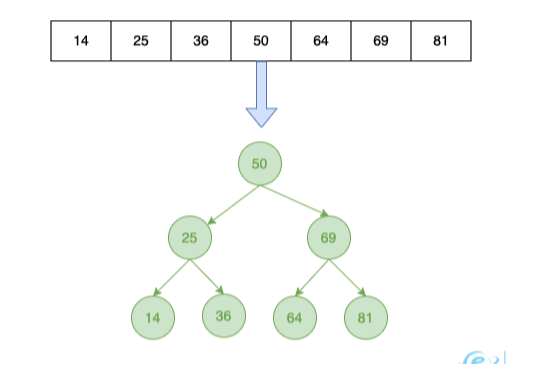
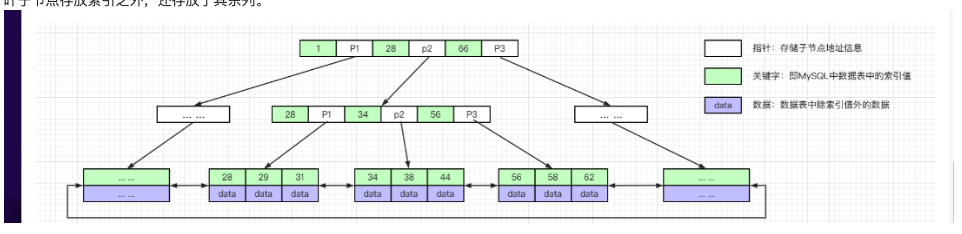
以三层高度为例,一颗B+树能承载的数据量是多少?
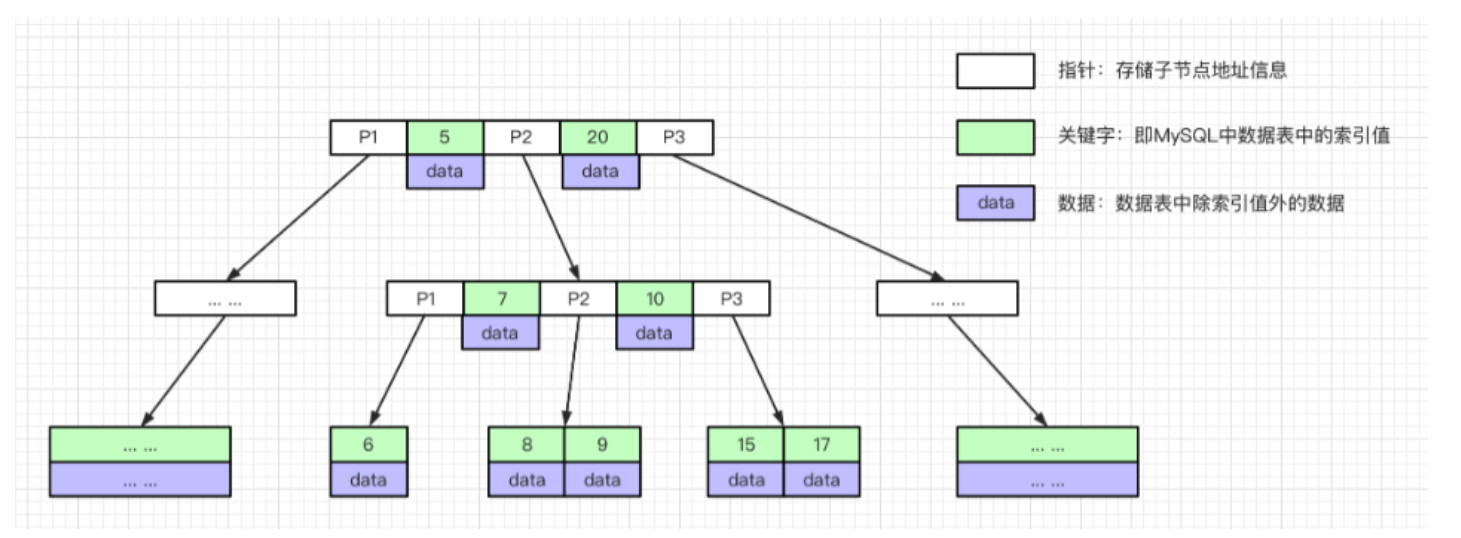
这里只考虑聚簇索引,数据页大小16kb,假设一行用户记录大小为1kb,所以叶子节点一个数据页存放记录16条。 对于非叶子节点,一个目录项由主键id和页号组成,主键id是(bigint)8个字节,Innodb中页号指针6个字节,所以一个非叶子节点的数据页有大概 16k / (8+6) = 1170条目录项记录。
那么此时高度为3的树可以存放 1170 1170 16 约等于2000w的数据,所以2000w以内的数据的索引树高度大概是1到3层。